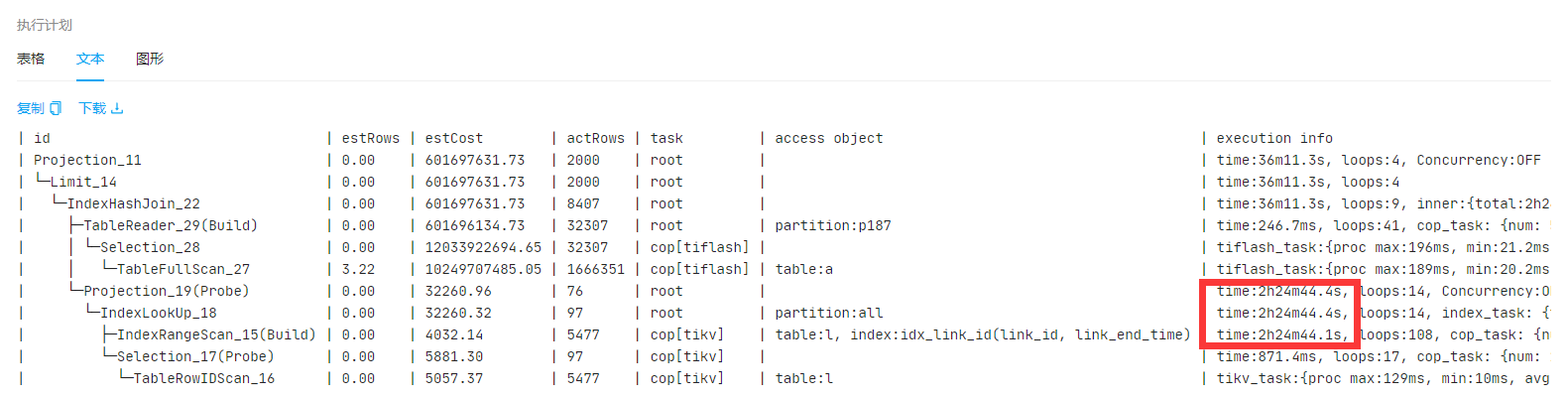
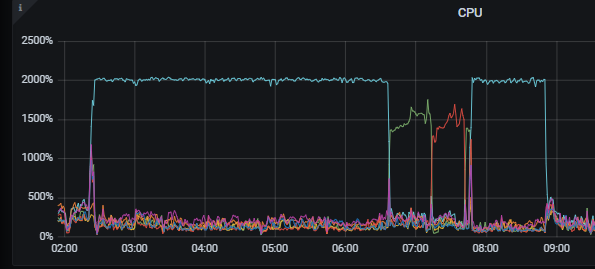
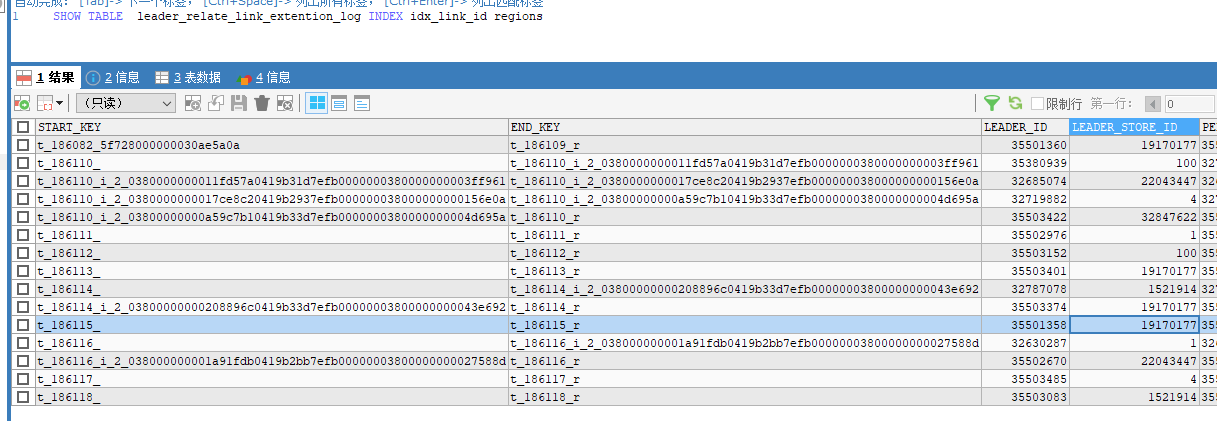
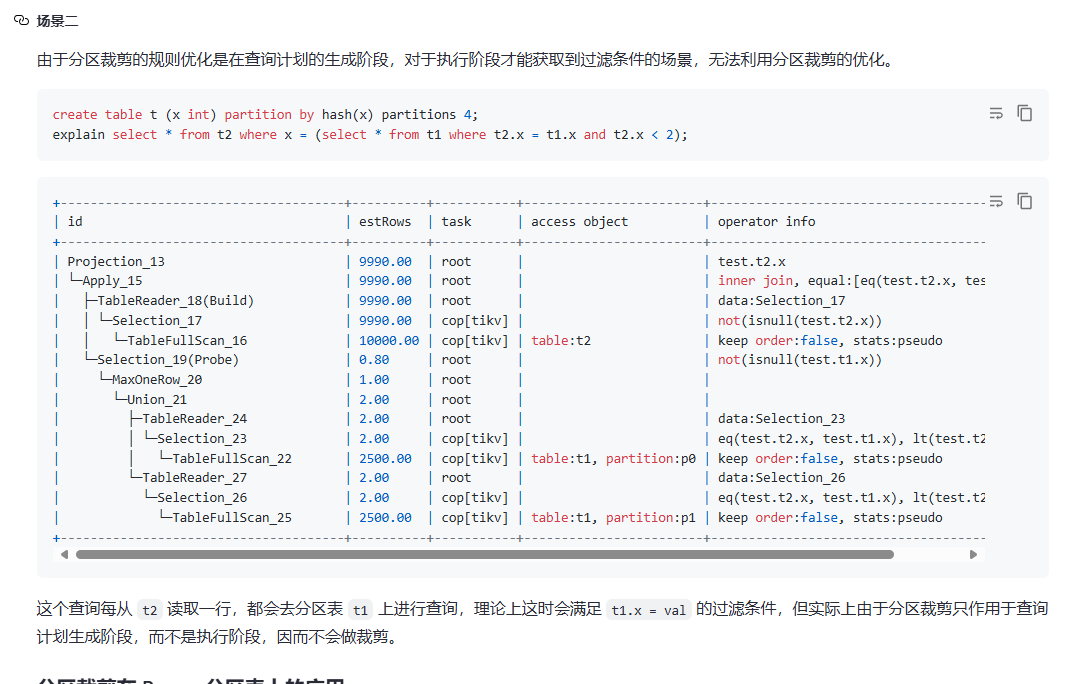
SELECT a.id, a.relate_product_id, a.institution_id, a.relate_activity_id, a.link_end_time, a.tenant_id FROM leader_relate_link a WHERE a.tenant_id = 187 AND a.platform = 1 AND a.relate_activity_id = '889562' AND a.link_end_time >= '2024-07-19 00:00:00' AND a.link_end_time <= '2024-08-03 23:59:59.999' AND a.relate_activity_product_status IN (1, 6) AND NOT EXISTS ( SELECT 1 FROM leader_relate_link_extention_log l WHERE l.link_id = a.id AND l.tenant_id = a.tenant_id AND l.link_end_time = a.link_end_time AND l.status = 1 ) LIMIT 6000, 2000;
SELECT a.id, a.relate_product_id, a.institution_id, a.relate_activity_id, a.link_end_time, a.tenant_id
FROM leader_relate_link a
WHERE a.tenant_id = 187
AND a.platform = 1
AND a.relate_activity_id = '889562'
AND a.link_end_time >= '2024-07-19 00:00:00'
AND a.link_end_time <= '2024-08-03 23:59:59.999'
AND a.relate_activity_product_status IN (1, 6)
AND NOT EXISTS
( SELECT 1 FROM leader_relate_link_extention_log
l WHERE l.link_id = a.id AND l.tenant_id = a.tenant_id
AND l.link_end_time = a.link_end_time AND l.status = 1 ) LIMIT 6000, 2000;
SELECT a.id, a.relate_product_id, a.institution_id, a.relate_activity_id, a.link_end_time, a.tenant_id
FROM leader_relate_link a
WHERE a.tenant_id = 187
AND a.platform = 1
AND a.relate_activity_id = '889562'
AND a.link_end_time >= '2024-07-19 00:00:00'
AND a.link_end_time <= '2024-08-03 23:59:59.999'
AND a.relate_activity_product_status IN (1, 6)
AND NOT EXISTS
( SELECT 1 FROM leader_relate_link_extention_log
l WHERE l.link_id = a.id AND l.tenant_id = 187
AND l.link_end_time = a.link_end_time AND l.status = 1 ) LIMIT 6000, 2000;