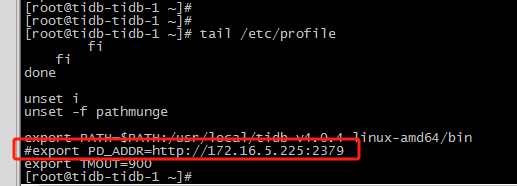
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.3.0
【复现路径】做过哪些操作出现的问题
1、升级前做 tiup cluster check,三个pd节点均报
disk Fail mount point / does not have 'nodelalloc' option set
2、根据官档搭建指导,把172.16.5.225(pd,以下简称225)的/etc/fstab文件改为如下:
\# UUID=3d682a67-edb8-4ac7-ba8b-594f9d146fb6 / ext4 defaults 1 1 # 原来的挂载参数 UUID=3d682a67-edb8-4ac7-ba8b-594f9d146fb6 / defaults,nodelalloc,noatime 0 2 # 新的挂载参数(注意:此处有误操作,把ext4不小心替换没了)
3、重启服务器,整个磁盘变只读,经阿里云介入大约40分钟后服务器恢复,但此台pd已经无法起来,日志报如下:

并且pd-ctl也无法使用:

此时经过切换不同的pd-ctl版本情况依旧
4、考虑到225的pd已挂,于是决定先扩容一台pd(ip为172.16.5.36,以下简称36),但执行完扩容命令后起来不,新的pd日志报错如下:

5、在军军导师的指引下,stop了有问题的225节点pd,然后编辑 meta.yaml 文件,把225这个节点信息删除,并且reload新扩容的36那个pd节点,日志如下:
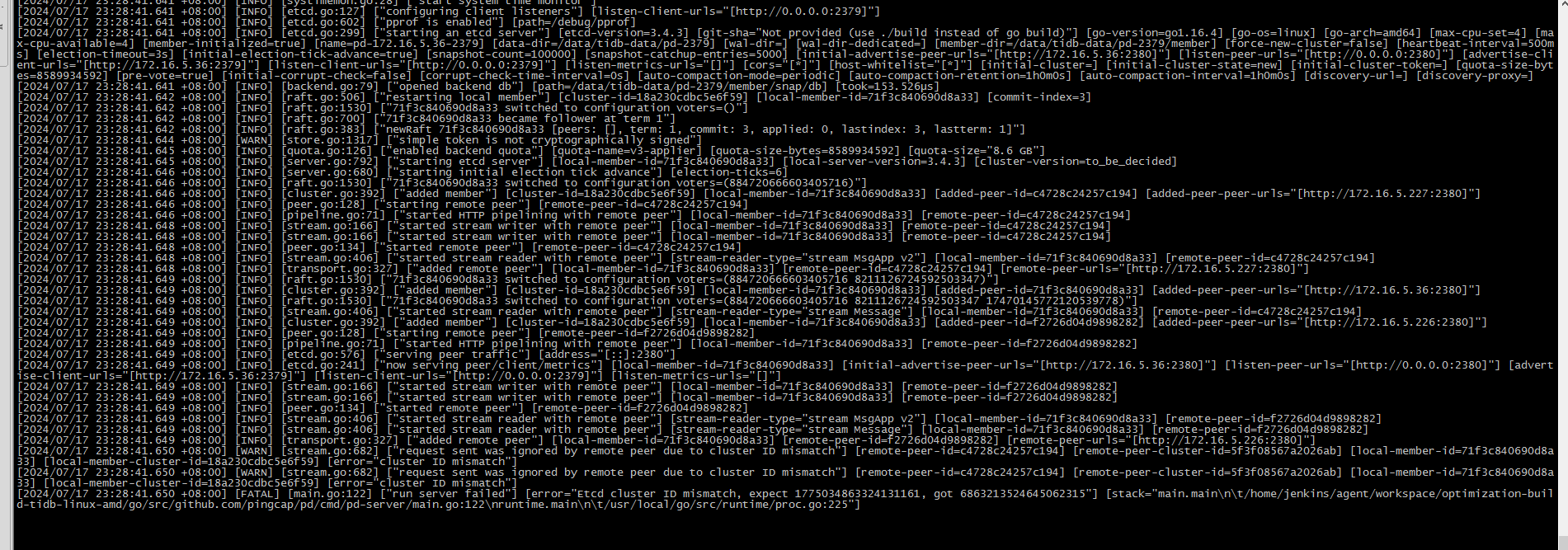
6、把有问题的225那台pd进行缩容,执行 ctl-pd 依然报错:

7、把其它两个正常的pd相继reload,最后整个集群reload后
8、此时 curl http://172.16.5.226:2379/pd/api/v1/members 已没有225 那台故障pd的信息
9、上述ctl-pd操作均在172.16.5.220服务器操作,当换其它服务器后执行ctl-pd执行正常
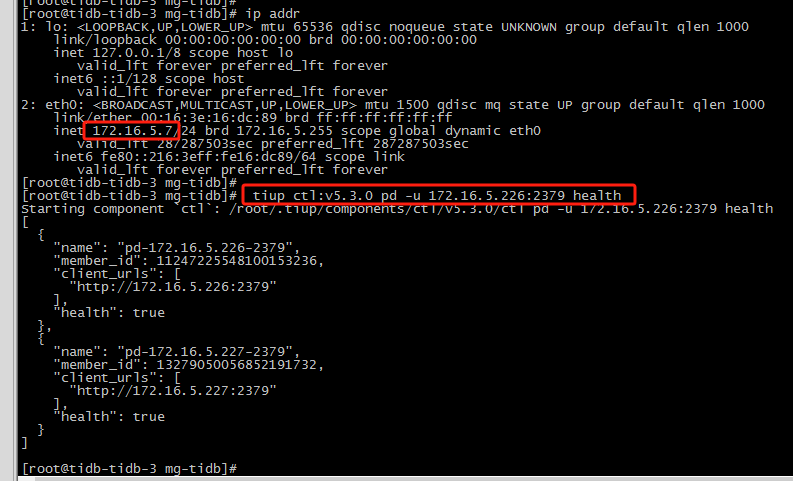
平时我们维护都在220机器操作,操作完后会把.tiup整文件夹scp到各台tidb-server中,目前发现除了220,还有一台172.16.5.94服务器是无法执行ctl-pd命令,220的tiup有做过升级,但94服务器是没动过。其它四台都可以正常执行ctl-pd
另外,在220和94上执行ctl-pd --help,也会引访问225,如下:

【遇到的问题:问题现象及影响】 只有两台pd,无法扩容
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】