【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】 tidb 7.1.3
【复现路径】 1、ticdc同步表的数据到kafka 2、源端开启了参数enable-tidb-extension=true
【遇到的问题:问题现象及影响】 下游消费kafka数据顺序错误
1、ticdc到kkf的数据不是顺序
2、下游SR消费数据,如何保证按照commit ts进行消费
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
目标端kafka 1个topic只有一个partition ,一个任务只有1个表,使用的是default分发,也就是按照表分发,仍然会乱序,请教问题点在哪里
–sink-uri=“kafka://xxxxx:port/table_name?kafka-version=3.0.0&max-message-bytes=67108864&replication-factor=2&partition-num=1&enable-tidb-extension=true” --changefeed-id=“table_name” --config /tidb/cdc/table_name.toml
同步任务配置信息
case-sensitive = true
是否输出 old value,从 v4.0.5 开始支持,从 v5.0 开始默认为 true
enable-old-value = true
[filter]
忽略指定 start_ts 的事务
ignore-txn-start-ts = [1, 2]
过滤器规则
rules = [‘a.table_name’]
[[filter.event-filters]]
matcher = [“a.table_name”]
ignore-delete-value-expr = “create_time<‘2023-01-01 00:00:00’”
[mounter]
mounter 线程数,用于解码 TiKV 输出的数据
worker-num = 16
[sink]
对于 MQ 类的 Sink,可以通过 dispatchers 配置 event 分发器
支持 default、ts、rowid、table 四种分发器,分发规则如下:
- default:有多个唯一索引(包括主键)时按照 table 模式分发???只有一个唯一索引(或主键)按照 rowid 模式分发;如果开启了 old value 特性,按照 table 分发
- ts:以行变更的 commitTs 做 Hash 计算并进行 event 分发
- rowid:以所选的 HandleKey 列名和列值做 Hash 计算并进行 event 分发
- table:以???的 schema 名和 table 名做 Hash 计算并进行 event 分发
matcher 的匹配语法和过滤器规则语法相同
dispatchers = [
{matcher = [‘a.table_name’], dispatcher = “default”},
]
对于 MQ 类的 Sink,可以指定消息的协议格式
目前支持 default、canal、avro 和 maxwell 四种协议。default 为 TiCDC Open Protocol
protocol = “canal-json”
–sink-uri=“kafka://xxxxx:port/table_name?kafka-version=3.0.0&max-message-bytes=67108864&replication-factor=2&partition-num=1&enable-tidb-extension=true” --changefeed-id=“table_name” --config /tidb/cdc/table_name.toml
kafka的消费策略是怎么配置的,这个也要保证是顺序的
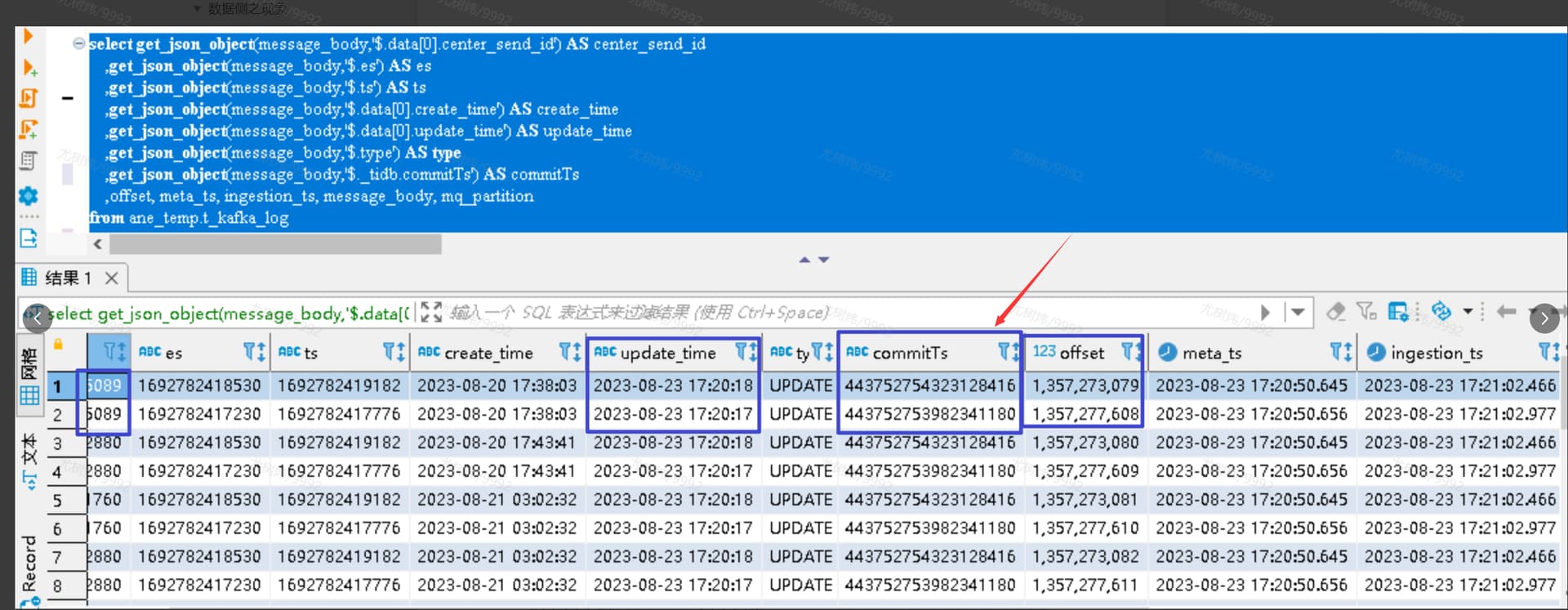
说是从这个图上看,同一条数据,到达kafka的顺序 offsize 和commit顺序不同
消费策略是研发那边配置就是根据offsest 一次性拿几千条数据,或者根据bytes大小达到一定200M消费到SR
突破边界
11
你是要保证什么样的顺序性呢? ticdc提供的是事务的顺序性,并不提供事务内不同行的顺序性
煲汤镇河妖
(Ti D Ber Pkn Gbh4 U)
13
建议在消费者端根据业务时间戳判断,先消费时间戳大消息后接收到时间戳小消息直接忽略消息