一张2亿表建索引测试
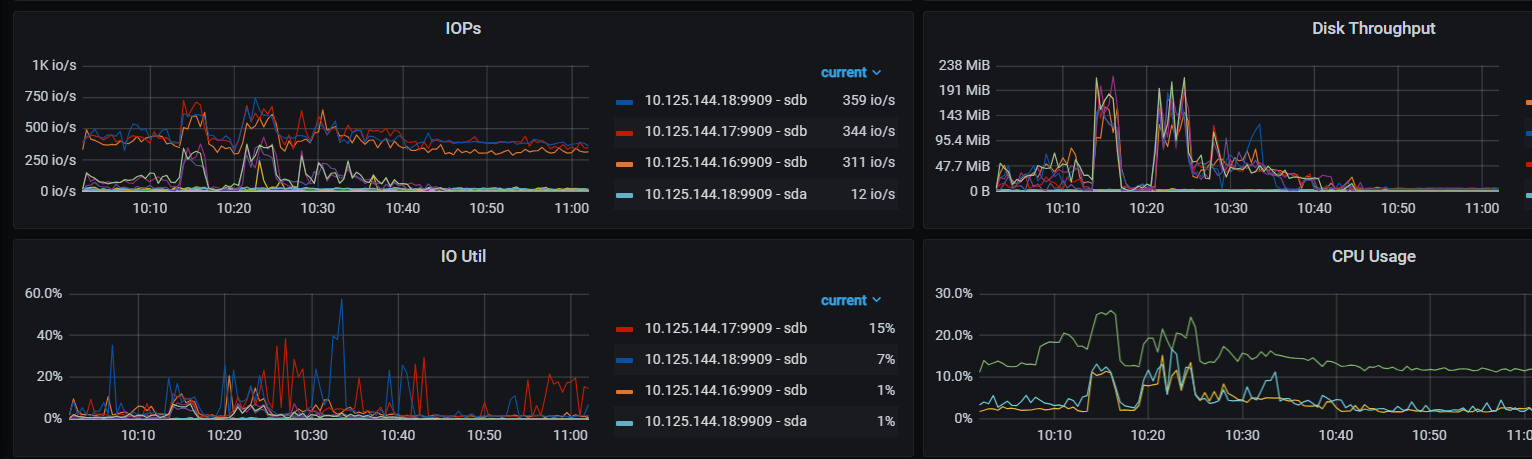
不使用分布式ddl时 执行时间和CPU如下
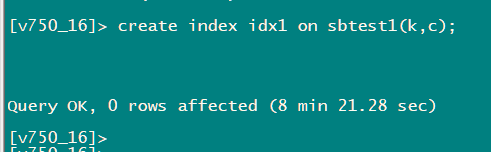
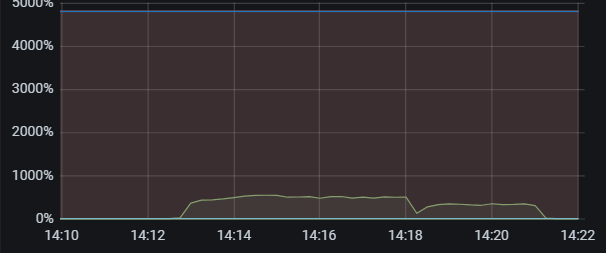
当通过调整tidb_service_scope tidb_enable_dist_task 开启并行DDL后 建索引时间反而变的更长,3个tidb节点是时间如下
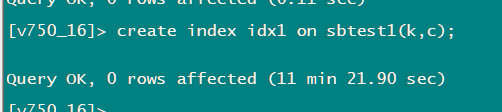
从tidb cpu上看 每个tidb执行是并不像单tidb一样一直持续的执行的

ddl owner是16节点,3个节点的tidb.log 见附件
log.rar (275.3 KB)
一张2亿表建索引测试
不使用分布式ddl时 执行时间和CPU如下
当通过调整tidb_service_scope tidb_enable_dist_task 开启并行DDL后 建索引时间反而变的更长,3个tidb节点是时间如下
从tidb cpu上看 每个tidb执行是并不像单tidb一样一直持续的执行的
ddl owner是16节点,3个节点的tidb.log 见附件
log.rar (275.3 KB)
mark 关注
怀疑是写的太快导致的,能否该时间段的收集一下监控?cinic 收集方法如下: https://docs.pingcap.com/zh/tidb/stable/quick-start-with-clinic , 收集信息类型里建议包含 metric 和 log,option 是 --include=monitor,log
[2024/07/15 15:25:32.518 +08:00] [WARN] [region_job.go:532] ["meet error and handle the job later"] [category=ddl-ingest] ["job stage"=wrote] [error="[Lightning:KV:ServerIsBusy]too many sst files are ingesting"] [region="{ID=122161,startKey=7480000000000041FFF05F698000000000FF0000080380000000FF0708A84D01383530FF3830373139FF3531FF392D37303934FF36FF3133323630392DFFFF3830353338343437FFFF3337342D383237FF37FF343239323435FF352DFF3633303434FF323437FF3637342DFF35393239FF393032FF383330352DFF3638FF353932323935FF36FF37352D31303135FFFF333235383831302DFFFF34323136343631FF35FF3433302D3139FF3832FF3239323839FF383900FE03800000FF00012BBB6D000000FC,endKey=7480000000000041FFF05F698000000000FF0000080380000000FF0745460E01393533FF3433303233FF3338FF332D34303735FF32FF3936313434372DFFFF3831303532353432FFFF3230382D393339FF30FF303539353039FF312DFF3731393134FF313737FF3531392DFF38323736FF393238FF313334342DFF3334FF323930333634FF34FF30312D38313839FFFF373134323732382DFFFF34333034383236FF37FF3230352D3835FF3033FF3433383032FF313100FE03800000FF00090B61F7000000FC,epoch=\"conf_ver:30125 version:8670 \",peers=\"id:122163 store_id:1 ,id:122299 store_id:3 ,id:122300 store_id:8007 \"}"] [start=7480000000000041F05F69800000000000000803800000000708A84D013835303830373139FF3531392D37303934FF363133323630392DFF3830353338343437FF3337342D38323737FF343239323435352DFF3633303434323437FF3637342D35393239FF393032383330352DFF3638353932323935FF3637352D31303135FF333235383831302DFF3432313634363135FF3433302D31393832FF3239323839383900FE0380000000012BBB6D] [end=7480000000000041F05F6980000000000000080380000000071AC7EB013939353232353837FF3836392D30393234FF383831373634372DFF3231363932383931FF3236362D38313731FF353430343735372DFF3530323634333937FF3633392D31333639FF313234343636332DFF3037353836323438FF3837312D37323532FF343334363233372DFF3538353930383036FF3834342D34363939FF3633373530313300FE038000000009DD3F84]
[2024/07/15 15:25:32.518 +08:00] [INFO] [local.go:1461] ["put job back to jobCh to retry later"] [category=ddl-ingest] [startKey=7480000000000041F05F69800000000000000803800000000708A84D013835303830373139FF3531392D37303934FF363133323630392DFF3830353338343437FF3337342D38323737FF343239323435352DFF3633303434323437FF3637342D35393239FF393032383330352DFF3638353932323935FF3637352D31303135FF333235383831302DFF3432313634363135FF3433302D31393832FF3239323839383900FE0380000000012BBB6D] [endKey=7480000000000041F05F6980000000000000080380000000071AC7EB013939353232353837FF3836392D30393234FF383831373634372DFF3231363932383931FF3236362D38313731FF353430343735372DFF3530323634333937FF3633392D31333639FF313234343636332DFF3037353836323438FF3837312D37323532FF343334363233372DFF3538353930383036FF3834342D34363939FF3633373530313300FE038000000009DD3F84] [stage=wrote] [retryCount=1] [waitUntil=2024/07/15 15:25:34.518 +08:00]
有点大 放网盘了
链接:百度网盘 请输入提取码
提取码:dpw2
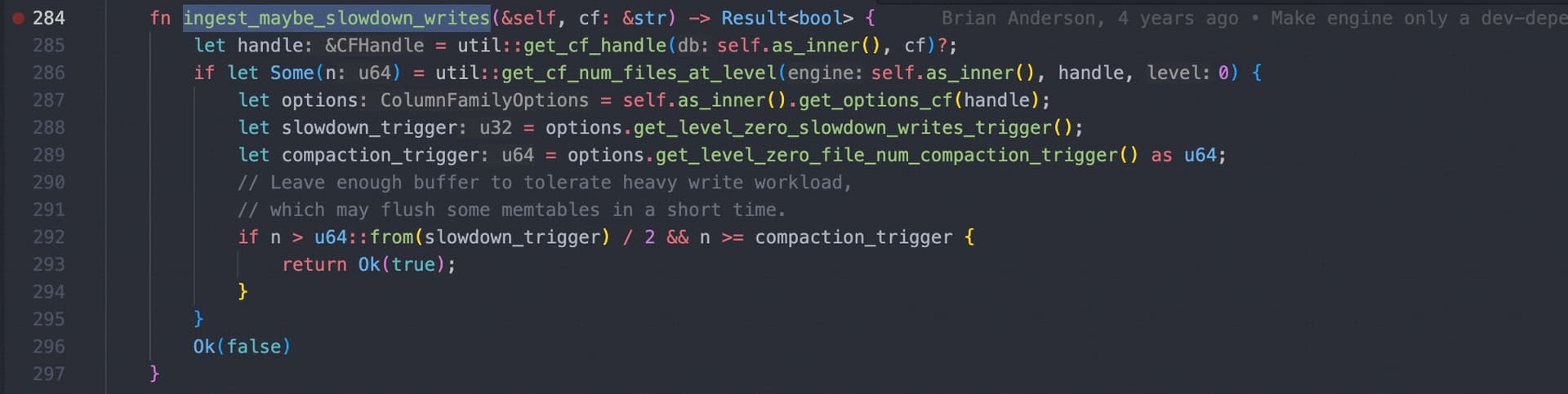
inject sst 失败的原因是写的太快导致了 L0 的文件太多了,然后 inject 就失败了,
相关的 tikv 代码如下:
建议适当的降低 tidb_ddl_reorg_worker_cnt 和 tidb_ddl_reorg_batch_size 减少写压力来减少 retry。
另外,如果瓶颈在 tikv 上,分布是 ddl 并不比非分布 ddl 快,这个符合理论预期的。
的确有点慢
可以开启监控功能,看看是什么原因导致的。
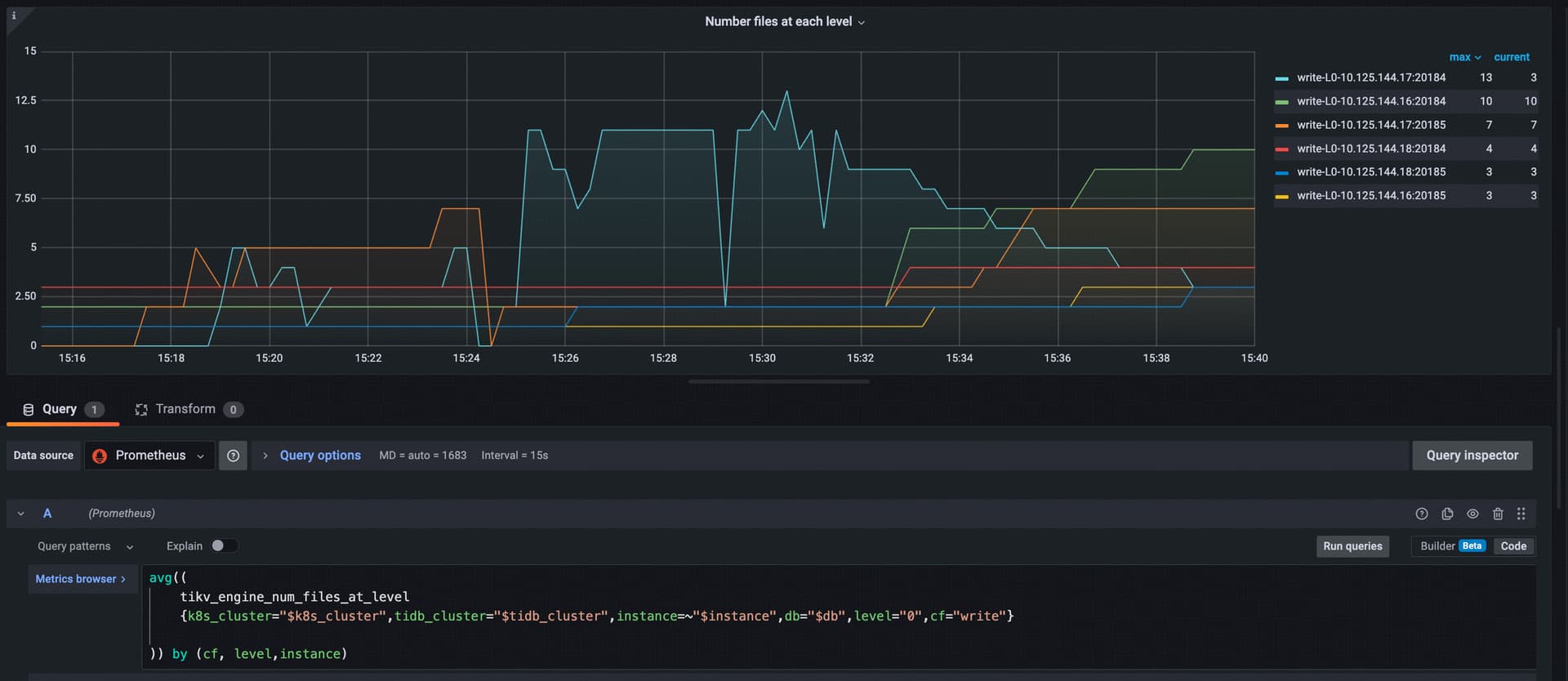
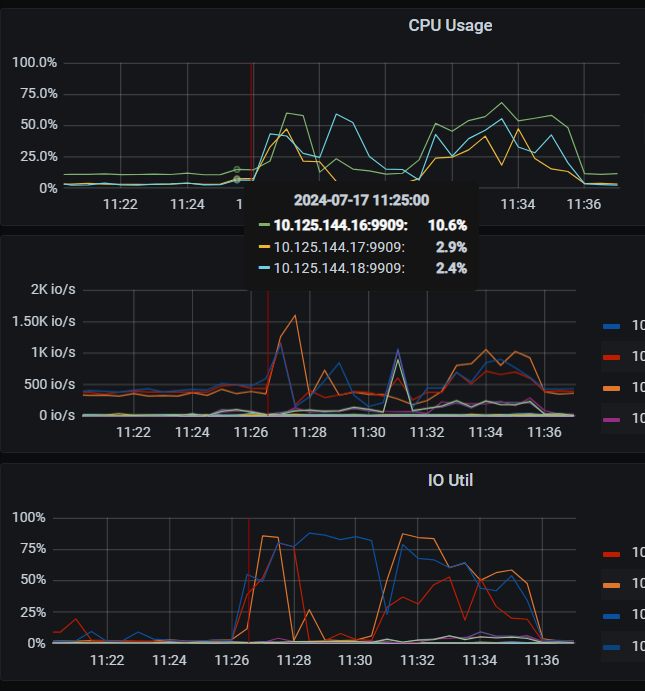
@h5n1 另外从监控可以看 inject sst 到各个 tikv 是不均衡的,如下监控可以看,热点集中在 10.125.144.17:20184
因此可以查一下这个 table index 的在各个 tikv 上分布,然后可以尝试参考文档打散这个 table,这样可以降低上述错误发生的概率, https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices#热点分布不均匀
@jhm633 这个报失败的阈值是有参数可调吗?
刚才检查region分布 发现这个表之前有placement 都放到17这个节点了(3tidb 6tikv ssd盘,目前就这1个表有数据)。取消placement 自动均衡后测试发现速度比之前还慢,单tidb 8 min 40.27 sec ,3tidb分布式 12 min 58.50 sec 。
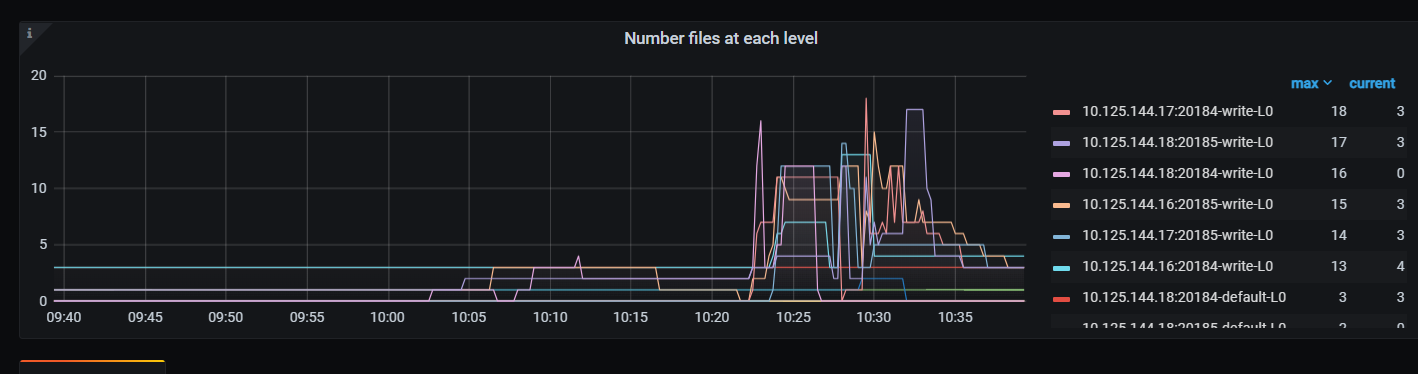
从监控看L0达到的数据量比之前还要多
资源还是比较充足
@h5n1 麻烦把 placement rule 删除后的 ddl ,单 tidb 和多 tidb 的监控和 log 也收集一下,同昨天一样,我们再看一下,有一些怀疑方向,需要 log 和监控再调查一下,谢谢。
@jhm633
链接:百度网盘 请输入提取码
提取码:vy54
@h5n1
当前你遇到的这个问题出现的原因是,多个 tidb 各自处理一部分 table range,将里面的索引列抽取出来编码成一组索引 kv,因为索引数据的顺序是不确定的,所以每个 tidb 只能通过本地排序保证自己的那一组索引 kv 有序,而 tidb 之间不同组 kv 可能有 overlap,这种 overlap 导致了 tikv rocksdb L0 文件太多,写入被限流 https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#l0-files-threshold 。
解决方法是启动 global sort,参考文档 https://docs.pingcap.com/zh/tidb/stable/tidb-global-sort,global sort 依赖一个外部的存储,在外部存储上排好序然后再分给 tikv,这样写入就没有 overlap,所以并行导入效率就会变高。
不过,考虑到配置外部存储也要成本,像几亿这个量级的数据,单机一趟就能完成的话还是建议用单机模式。
另外,默认单机本地盘空间是 100GB,如果要加的索引数据超过了 100GB,还使用单机 DDL 的话需要改大 tidb_ddl_disk_quota 到 n * 100GB。
感谢,@jhm633 我又测试了还是有几个问题
3、调整l0-files-threshold 时reload集群 有2个tikv再默认超时时间内没起来,单独指定超时时间要等很久才能起来。2个节点花了很多时间再rfat recover上。
17节点:
[2024/07/16 16:58:50.734 +08:00] [WARN] [pipe_builder.rs:475] ["Truncating log file due to broken batch (queue=Append,seq=121,offset=9558543): Corruption: Unrecognized compression type: 51"] [thread_id=24]
[2024/07/16 16:58:50.761 +08:00] [INFO] [engine.rs:93] ["Recovering raft logs takes 99.081493245s"] [thread_id=1]
[2024/07/16 16:58:51.832 +08:00] [INFO] [mod.rs:298] ["Storage started."] [thread_id=1]
18节点
[2024/07/16 17:08:54.670 +08:00] [WARN] [pipe_builder.rs:475] ["Truncating log file due to broken batch (queue=Append,seq=687,offset=23998273): Corruption: Unrecognized compression type: 55"] [thread_id=24]
[2024/07/16 17:09:16.023 +08:00] [INFO] [util.rs:639] ["connecting to PD endpoint"] [endpoints=http://10.125.144.18:23794] [thread_id=12]
[2024/07/16 17:09:19.015 +08:00] [INFO] [engine.rs:93] ["Recovering raft logs takes 602.508061717s"] [thread_id=1]
[2024/07/16 17:09:22.346 +08:00] [INFO] [mod.rs:298] ["Storage started."] [thread_id=1]
为什么这个recover时间很长(和删除索引后GC有关?)。
链接:百度网盘 请输入提取码
提取码:d7fo
关注学习,跟着大牛进步。
问题 1. 可以自建一个内部 minio 实现一个类 aws s3 的对象存储;Install and Deploy MinIO — MinIO Object Storage for Container
MinIO 高性能分布式存储最新版单机与分布式部署 - 大数据老司机 - 博客园
问题 2 和 3 我分析一下监控和 log 稍后回复。
谢谢老师的指导 。
用s3排序跑了下,执行了10 min 27.84 sec,因为minio和tikv在同一个盘上 ,不知道资源争用能影响多少,不过tidb里到是没有ingest那种失败了
另外有个问题 admin show ddl 这里不显示行数进度
看tidb CPU 中间有段时间 貌似处于了暂停状态
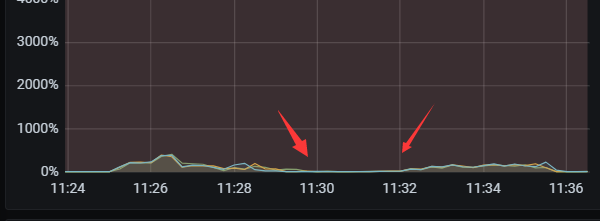
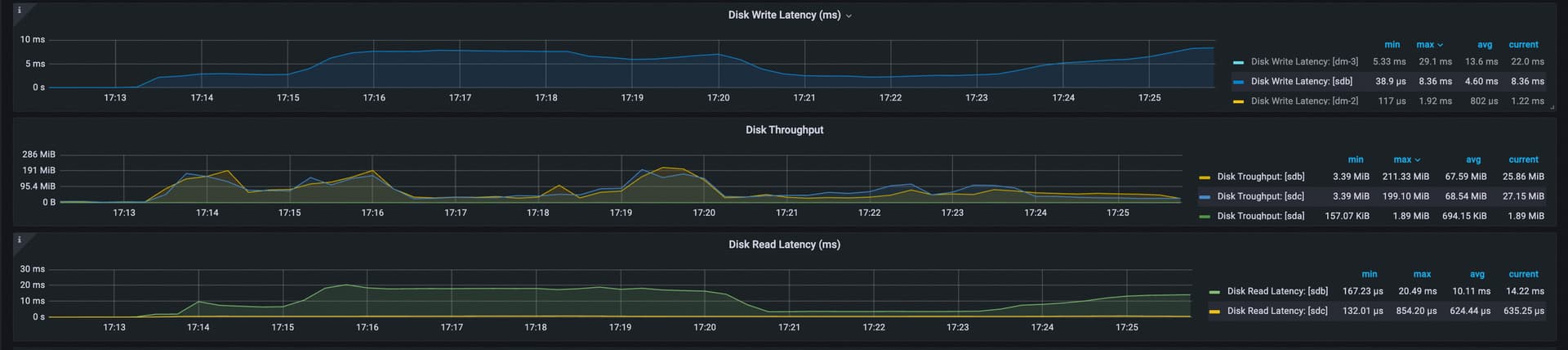
问题 2: 本质是调参导致 tikv 写压力更大,叠加上盘慢,触发了流控和 slow store evict.
这个是 18 上 sdb和 17 上 sdb 磁盘监控的 write latency 可以看到:
调大 L0 threshhold 后,tikv 压力也就更大了,写入变慢,触发了 slow store 检测,
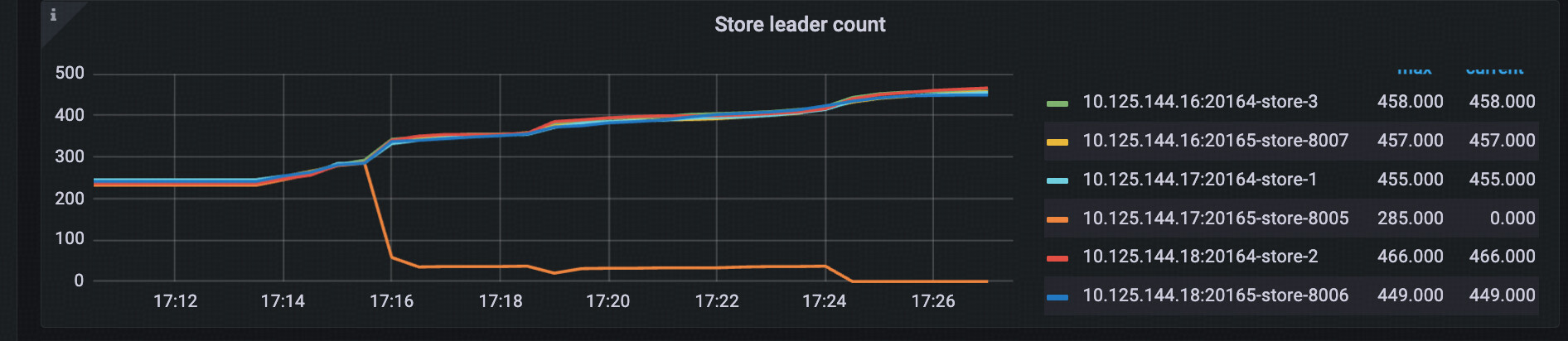
region leader 的变更,导致 ddl 遇到大量如下的报错:
[2024/07/16 17:17:58.310 +08:00] [WARN] [region_job.go:532] ["meet error and handle the job later"] [category=ddl-ingest] ["job stage"=needRescan] [error="[Lightning:KV:NotLeader]peer is not leader for region 361501, leader may Some(id: 361503 store_id: 2)"] [] [start=7480000000000041F05F69800000000000000B038000000005FE40AF013039373938373139FF3338312D33393734FF343531303636372DFF3436313535383633FF3331352D34383332FF373031373733372DFF3235313432343438FF3536342D35333533FF383136313239332DFF3631373431373135FF3532392D38393231FF383630353432312DFF3537393037383531FF3130382D34313437FF3832373836323800FE03800000000685F601] [end=7480000000000041F05F69800000000000000B038000000005FE44D8013436353533363337FF3034352D38383134FF323234323632302DFF3239323535383535FF3836392D34313130FF343433383235352DFF3734363537393834FF3338302D35373535FF373239333330392DFF3035303239313130FF3136372D34313634FF393332303134332DFF3830363033313036FF3934362D31363536FF3735303937323200FE0380000000096FA99A]
问题 3: 没有这个时间段的监控,从当前监控来估计应该是数据量大叠加盘慢,同问题 1 是一样的。
“Recovering raft logs” 需要 reload raft log,add/drop index 操作的数据量太大,reload 的时候需要处理的数据就多,再加上盘慢,所以导致这个阶段耗时过长。
建议:以当前的资源情况,建议使用 minio 部署一个外部存储,启动 global sort 后,再使用分布是 ddl。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。