【 TiDB 使用环境】测试
【 TiDB 版本】v7.6.0
【复现路径】执行升级命令
tiup cluster upgrade tidb-test v8.1.0
最终在重启tiflash时失败
Error: failed to restart: 192.168.0.150 tiflash-9000.service,
please check the instance's log(/mnt/filemanage/data1/tidb-deploy/tiflash-9000/log) for more detail.:
timed out waiting for port 3930 to be started after 2m0s
【遇到的问题:问题现象及影响】
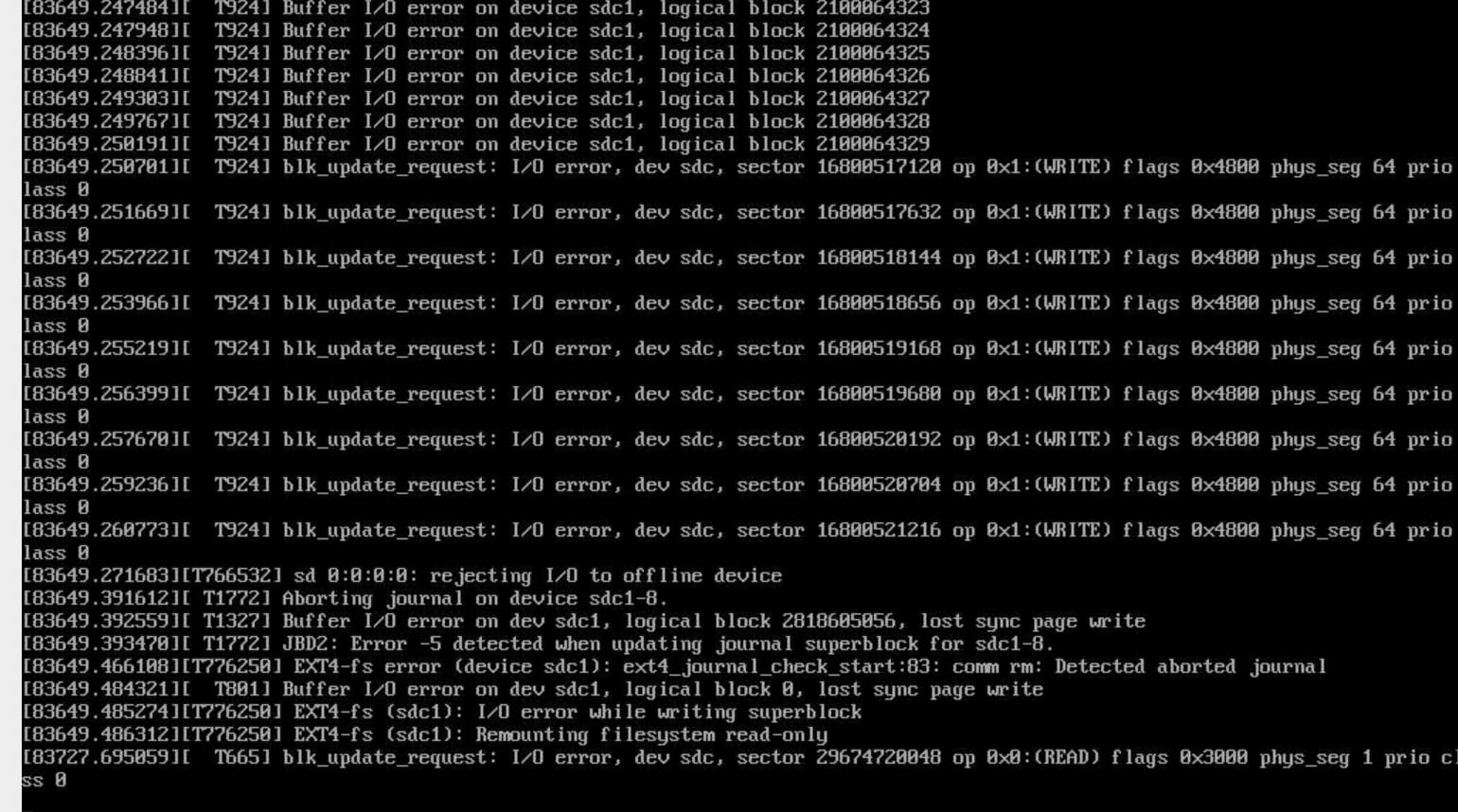
现象一:升级过程tiflash.log日志有发现一行错误信息如下:
[2024/07/11 22:48:39.009 +08:00] [ERROR] [LocalAdmissionController.cpp:445]
["watch resource group event failed: read watch stream failed, CANCELLED"]
[source=LocalAdmissionController] [thread_id=804]
现象二:升级过程重启tiflash环节,tiflash.log最后的日志显示一直在WaitCheckRegionReady,日志如下:
[2024/07/11 22:49:22.648 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:49:42.648 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:50:02.649 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:50:22.649 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:50:42.650 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:51:02.650 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:51:22.651 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:51:42.652 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:52:02.652 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:52:22.653 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:52:42.654 +08:00] [INFO] [ReadIndex.cpp:207]
["1 regions need to fetch latest commit-in
dex in next round, sleep for 20.000s"] [source=WaitCheckRegionReady] [thread_id=1]
[2024/07/11 22:53:02.655 +08:00] [WARN] [ReadIndex.cpp:224]
["1 regions CANNOT fetch latest commit-ind
ex from TiKV, (region-id): 60200"] [source=WaitCheckRegionReady]
[thread_id=1]
现象三:升级失败后,数据库仍可以正常使用
补充另一个信息,今天下午我在7.6.0版本下扩容了tiflash节点,部署成功了,但是似乎并不能下推算子,具体可参见:算子没有下推到TiFlash. 都跟tiflash有关,不知道是否有关联?
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】