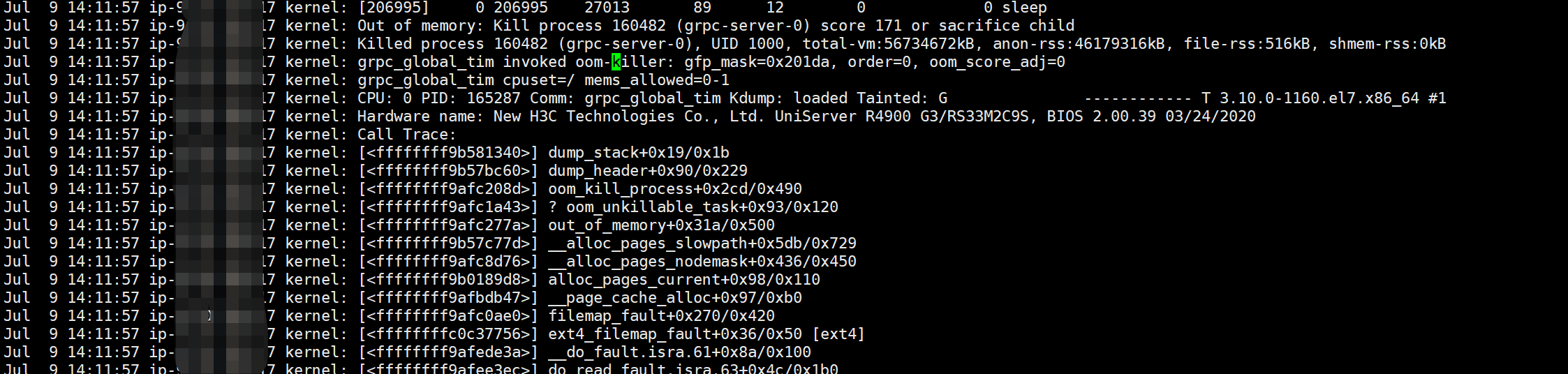
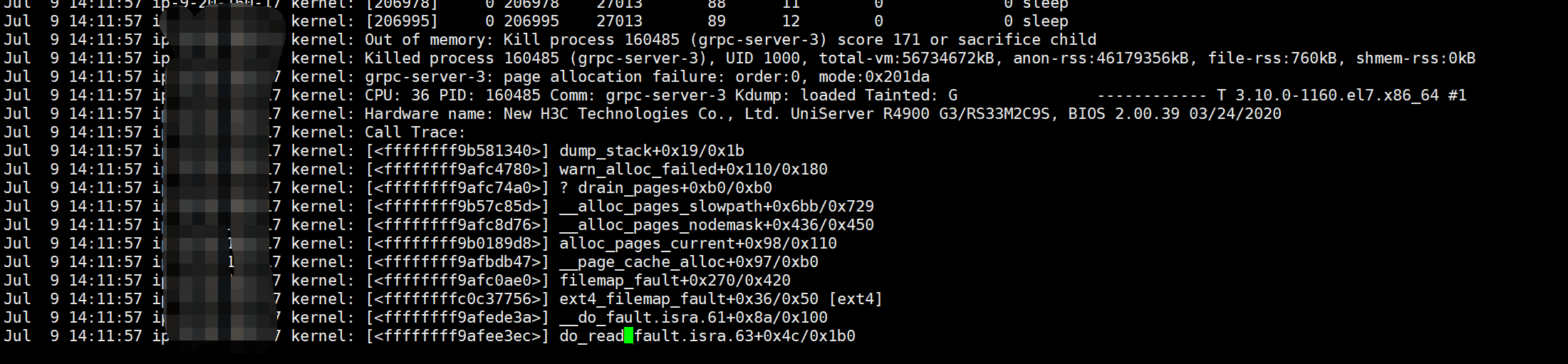
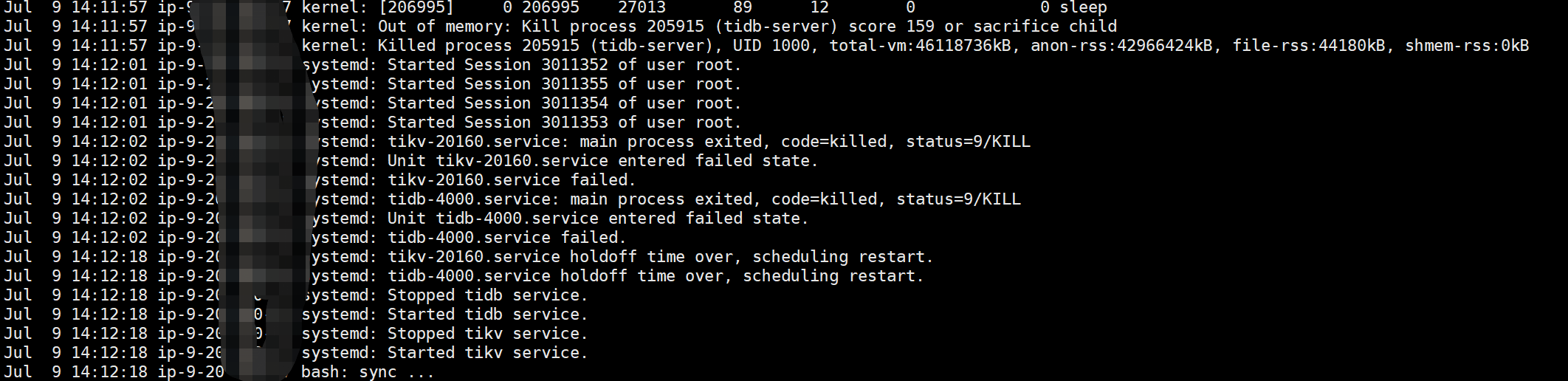
测试环境,发现tidb节点、tikv节点经常重启,系统日志相关信息:
混合部署的,尽量做一下资源限制,比如tikv的block-cache进行手动设置并降低。
-
storage.block-cache.capacity:调整存储层块缓存的容量。
raftdb.rate-limiter.capacity:调整 RaftDB 的写入速度限制。grpc-concurrency:调整 gRPC 并发度,以减少内存使用。server.grpc-concurrent-streams:调整 gRPC 最大并发流数量。
试试调整上述参数试试。
这是 oom 了呀, 可以参考文档配置下相关参数
tidb :
https://docs.pingcap.com/zh/tidb/v8.0/configure-memory-usage#tidb-内存控制文档
tikv :
https://docs.pingcap.com/zh/tidb/stable/tune-tikv-memory-performance#tikv-内存参数性能调优
也考虑下优化一下SQL
1.TiDB和TiKV要合理分配下内存 2.内存过低需要对内存扩容 3.看看服务器有没有其他进程占用内存较多 4.是不是执行了啥SQL造成的
tidb 和tikv 混部了,没台服务器上2个tikv实例,2个tidb实例,block-cache 由之前的128G 修改为50G ,修改完了之后还有重启的问题,是需要再改小点吗?机器的配置值512G 128核
看了下重启时间段的sql ,最大内存占用不超过1G
tikv仍然还有被kill的情况发生?发几个监控图看一下。
1.Overview → System info → Memory Available
2.TiDB → Server → Memory Usage
3.TiKV-Details → Cluster → Memory
4.TiDB-Runtime → OOM节点 → Memory Usage
顺便看一下绑没绑numa,绑了的话怎么绑的
内存溢出了
TiDB和TiKV节点还是尽量不要混合部署在一起,这样很容易内存紧张的时候导致占用内存大的节点进程被干掉
混合部署也不好