【 TiDB 使用环境】生产环境
【 TiDB 版本】V7.1.0
【复现路径】
事务逻辑
1、游标长链接**「扫描全表」大概20亿行数据**
2、每批次1000条做ETL写入TiDB
3、启动8进程写入,触发OOM
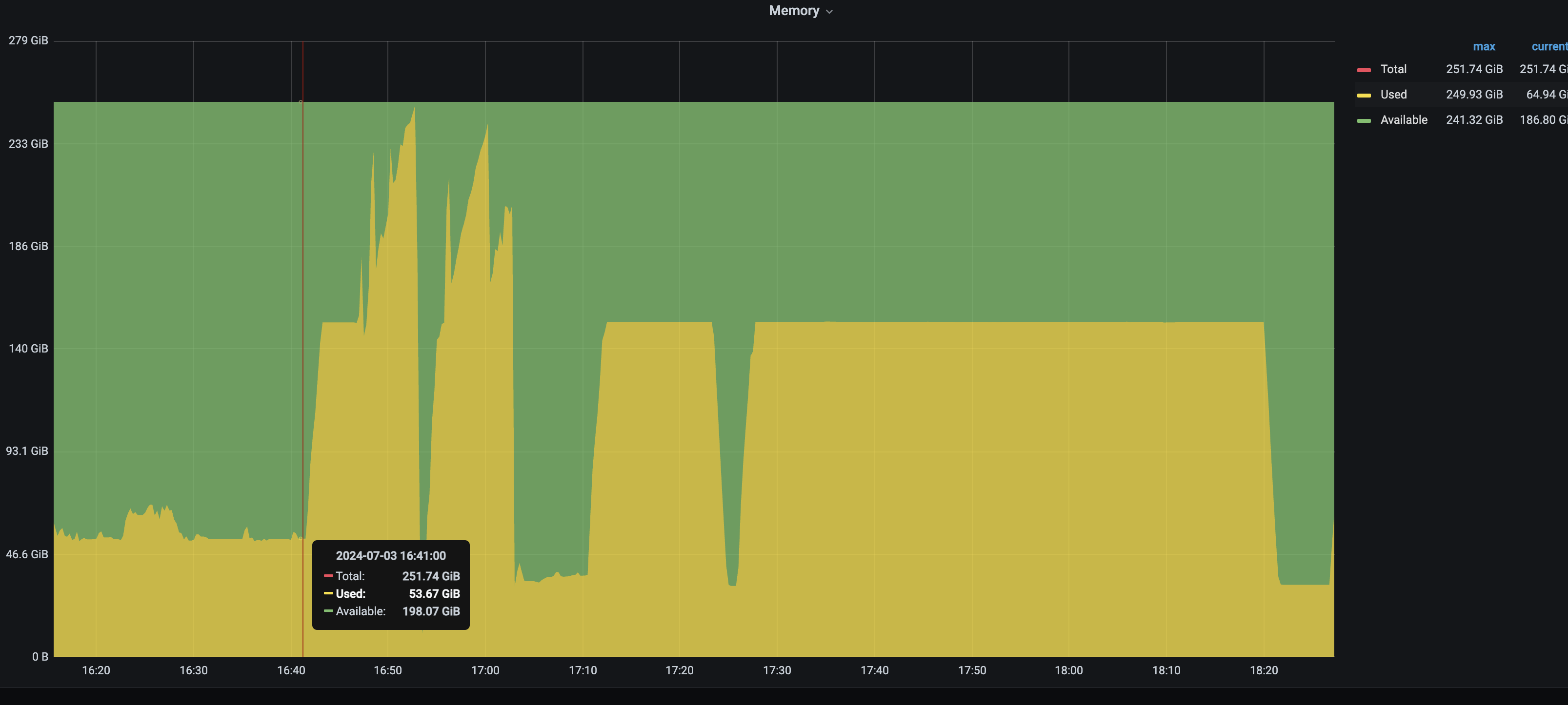
4、第一次整改:改为4进程并发写入,内存占用65%,未发生OOM。
5、第二次整改:改为3进程并发写入,内存占用65%,未发生OOM【与第一次整改内存用量相等】。
6、第三次整改:改为4进程,同时将游标查询「全表数据」改为「索引范围查询 – 半年查询」,内存占用25%。
【遇到的问题:问题现象及影响】
1、上述第3部,触发OOM,为什么游标查询没及时释放内存
2、为什么游标查「全表扫描」改为「索引范围查询」内存下降明显(应该跟第一个问题根因相同,个人理解是内存释放不及时,或存在bug)
proflie和heap抓到了,但按照官方推荐没能打开。
附录:https://docs.pingcap.com/zh/tidb/stable/java-app-best-practices#使用-streamingresult-流式获取执行结果
1 个赞
小龙虾爱大龙虾
(Minghao Ren)
2
描述下具体场景,如何做的 ETL ,是直接发 insert xxx select xxx; 这种 SQL ?还是 SELECT 查到放到文件里,再 INSERT 到 TiDB 里?还是其他方式
你是混合部署吗?【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面 在这个页面截图看一下
Qiuchi
(Ti D Ber T Hwl2t Uf)
6
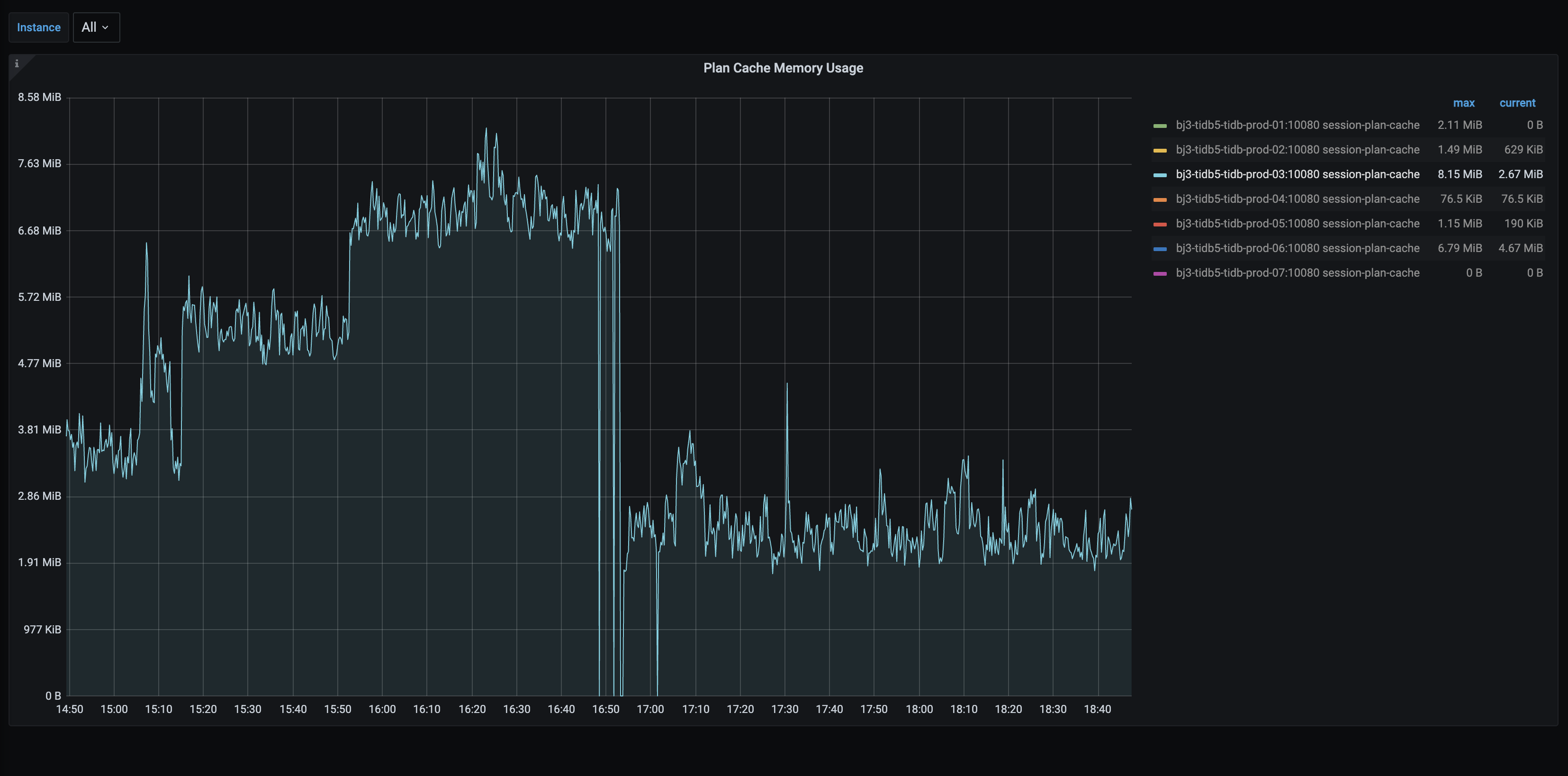
发一下 grafana / tidb / executor / plan cache memory usage
Qiuchi
(Ti D Ber T Hwl2t Uf)
9
这个场景上是从这个库查数据,处理后再插回这个库么?
没看懂啊,你这些数据是从其他地方写入tidb,还是tidb要弄到其他地方,还是直接就在tidb本地复制一份?
Qiuchi
(Ti D Ber T Hwl2t Uf)
11
8进程时感觉就是频繁的插入操作导致内存增加。比如8进程 索引范围查询-半年查询试过没?估计也不会oom。内存来不及释放,是否可以手动释放下 间隔合理时间?
select 完成后,做etl(flink读出来,再解析)转换,再写入tidb。
查询的表和写入的表在同一个tidb集群,不同库。
1 个赞
没试过
我留意一下,对比3、4并发同时查询「全量数据」写入的内存没有明显差异。
盲猜8并发同时查询「半年数据」,不会出现内存暴涨问题。
小龙虾爱大龙虾
(Minghao Ren)
16
 那是扫的数据太快了,你现在测试下 8 进程写入,游标长连接读取,但在开始读取前,设置会话变量 `SET SESSION tidb_distsql_scan_concurrency = 2; 观察下内存使用情况
那是扫的数据太快了,你现在测试下 8 进程写入,游标长连接读取,但在开始读取前,设置会话变量 `SET SESSION tidb_distsql_scan_concurrency = 2; 观察下内存使用情况
有可能,前序是2个4并发的开始(总共8并发)。
我让研发测测,印象有监控面板看这个指标。