【 TiDB 使用环境】生产环境
【 TiDB 版本】
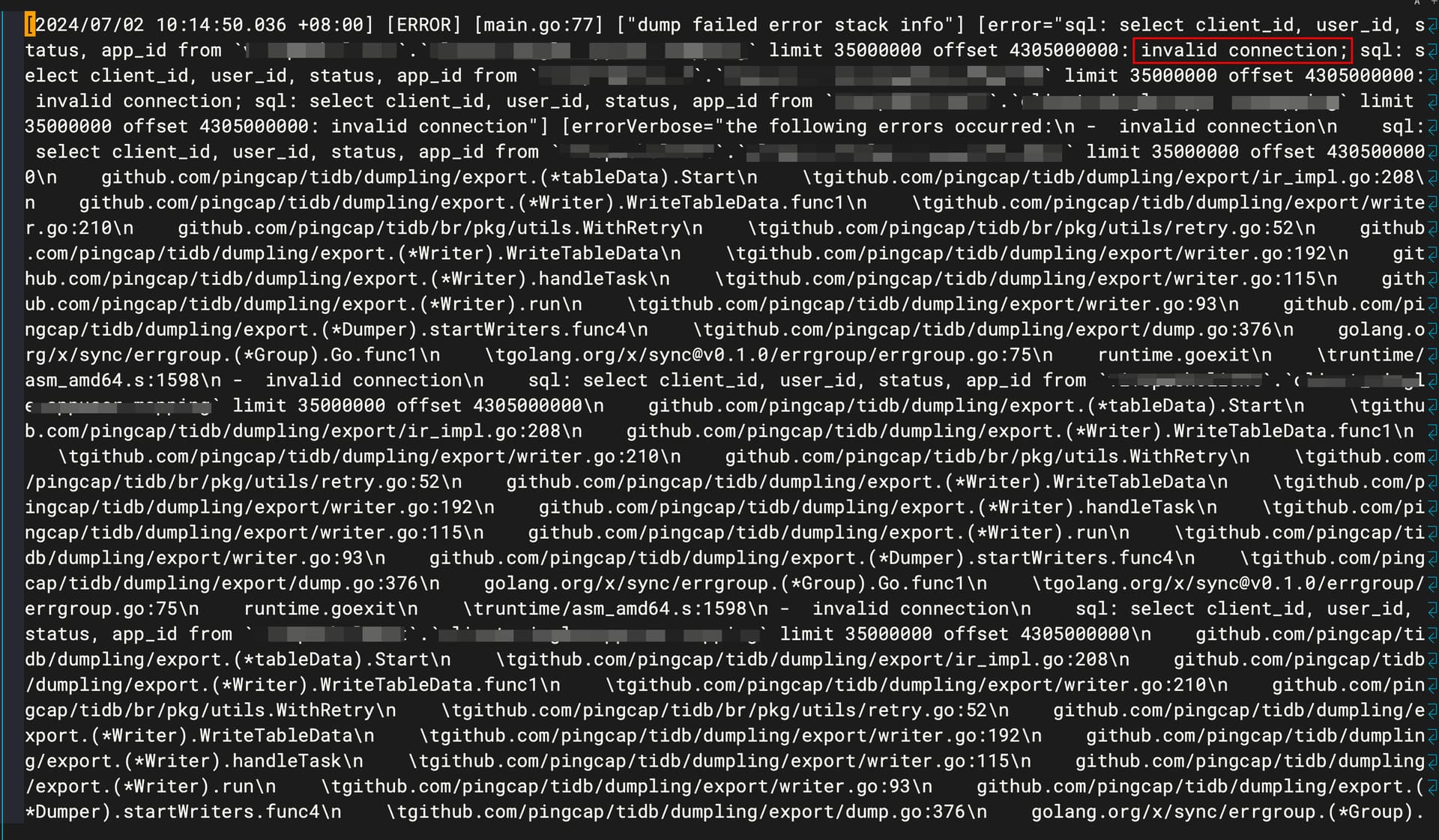
【复现路径】执行脚本:/data/dumpling -u client -p pj9xxt -P 4000 -h 10.102.1.1 -o /data/tars/logs/ --filetype csv --csv-delimiter ‘’ --output-filename-template ‘active_regid_4305000000_1719883785729.{{.Index}}’ -r 500 --tidb-mem-quota-query 4294967296 -t 32 --sql ‘select client_id, user_id, status, app_id from client.mapping limit 35000000 offset 4305000000’ -F 50MiB --params “tidb_enable_chunk_rpc=OFF”
【遇到的问题:问题现象及影响】
报错invalid connection
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
10.102.1.1 这节点CPU很高嘛,你试着把 -t 32 并发线程数开小一点呢
我试试哈
表数据总共有200多亿,dumpling能跑完这么多数据不。我打算通过limit和offset分批次把数据加载出来,或者您对于这类场景有更好的建议吗
你现在集群版本4.0的嘛
对的。4.0.8
你是想把200亿数据分批导出成多个 csv 文件嘛,要不你试试按照ID分批次导出
可以按照ID分批次导出,您可以提供个类似的执行指令供我参考下吗

写个脚本,把 id 值分批传入 --where中,例如 --where ’xxx<=xx_id and xx_id <=xxx‘ 或者 --sql ’ select client_id, user_id, status, app_id from
client .mapping --where ’xxx<=id and id <=xxx‘;‘还有可以考虑把集群升下级,这样性能也有提升
感谢您的答复,我试试看