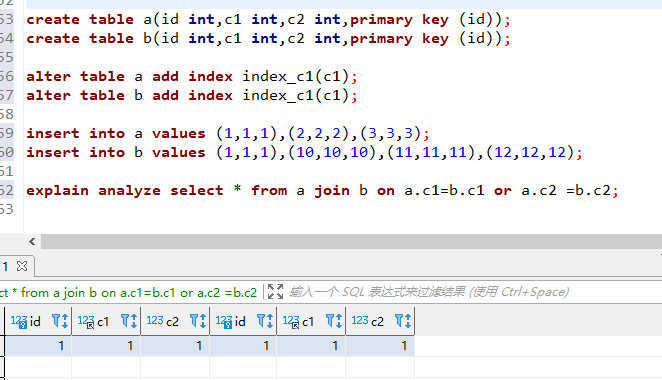
mysql> explain analyze select * from a join b on a.c1=b.c1 or a.c2 =b.c2;
+-----------------------------+---------+---------+-----------+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------+-----------+---------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+-----------------------------+---------+---------+-----------+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------+-----------+---------+
| HashJoin_8 | 12.00 | 1 | root | | time:11.1ms, loops:2, build_hash_table:{total:10.9ms, fetch:10.9ms, build:3.76µs}, probe:{concurrency:5, total:54ms, max:10.9ms, probe:41.4µs, fetch:54ms} | CARTESIAN inner join, other cond:or(eq(zktest.a.c1, zktest.b.c1), eq(zktest.a.c2, zktest.b.c2)) | 25.9 KB | 0 Bytes |
| ├─TableReader_10(Build) | 3.00 | 3 | root | | time:10.9ms, loops:2, cop_task: {num: 1, max: 10.9ms, proc_keys: 3, rpc_num: 1, rpc_time: 10.9ms, copr_cache: disabled, distsql_concurrency: 15} | data:TableFullScan_9 | 318 Bytes | N/A |
| │ └─TableFullScan_9 | 3.00 | 3 | cop[tikv] | table:a | tikv_task:{time:0s, loops:1}, scan_detail: {total_process_keys: 3, total_process_keys_size: 123, total_keys: 4, get_snapshot_time: 9.37ms, rocksdb: {key_skipped_count: 3, block: {cache_hit_count: 4}}} | keep order:false, stats:pseudo | N/A | N/A |
| └─TableReader_12(Probe) | 4.00 | 4 | root | | time:1.79ms, loops:2, cop_task: {num: 1, max: 1.79ms, proc_keys: 4, rpc_num: 1, rpc_time: 1.76ms, copr_cache: disabled, distsql_concurrency: 15} | data:TableFullScan_11 | 328 Bytes | N/A |
| └─TableFullScan_11 | 4.00 | 4 | cop[tikv] | table:b | tikv_task:{time:0s, loops:1}, scan_detail: {total_process_keys: 4, total_process_keys_size: 164, total_keys: 5, get_snapshot_time: 7.49µs, rocksdb: {key_skipped_count: 4, block: {cache_hit_count: 2}}} | keep order:false, stats:pseudo | N/A | N/A |
+-----------------------------+---------+---------+-----------+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------+-----------+---------+
5 rows in set (0.01 sec)
测试数据
create table a(id int,c1 int,c2 int,primary key (id));
create table b(id int,c1 int,c2 int,primary key (id));
alter table a add index index_c1(c1);
alter table b add index index_c1(c1);
insert into a values (1,1,1),(2,2,2),(3,3,3);
insert into b values (1,1,1),(10,10,10),(11,11,11),(12,12,12);
1.请问一下,在执行语句时,为什么走hash join 时要形成笛卡尔积呢(如果没记错的话,貌似Oracle不需要形成笛卡尔积)?
2.为什么不能走Index join (oracle 应该是可以的)?