【 TiDB 使用环境】生产环境
【 TiDB 版本】8.1
【复现路径】做过哪些操作出现的问题
每天间故障都会间歇性出现,到现在一直还没有解决。
【遇到的问题:问题现象及影响】
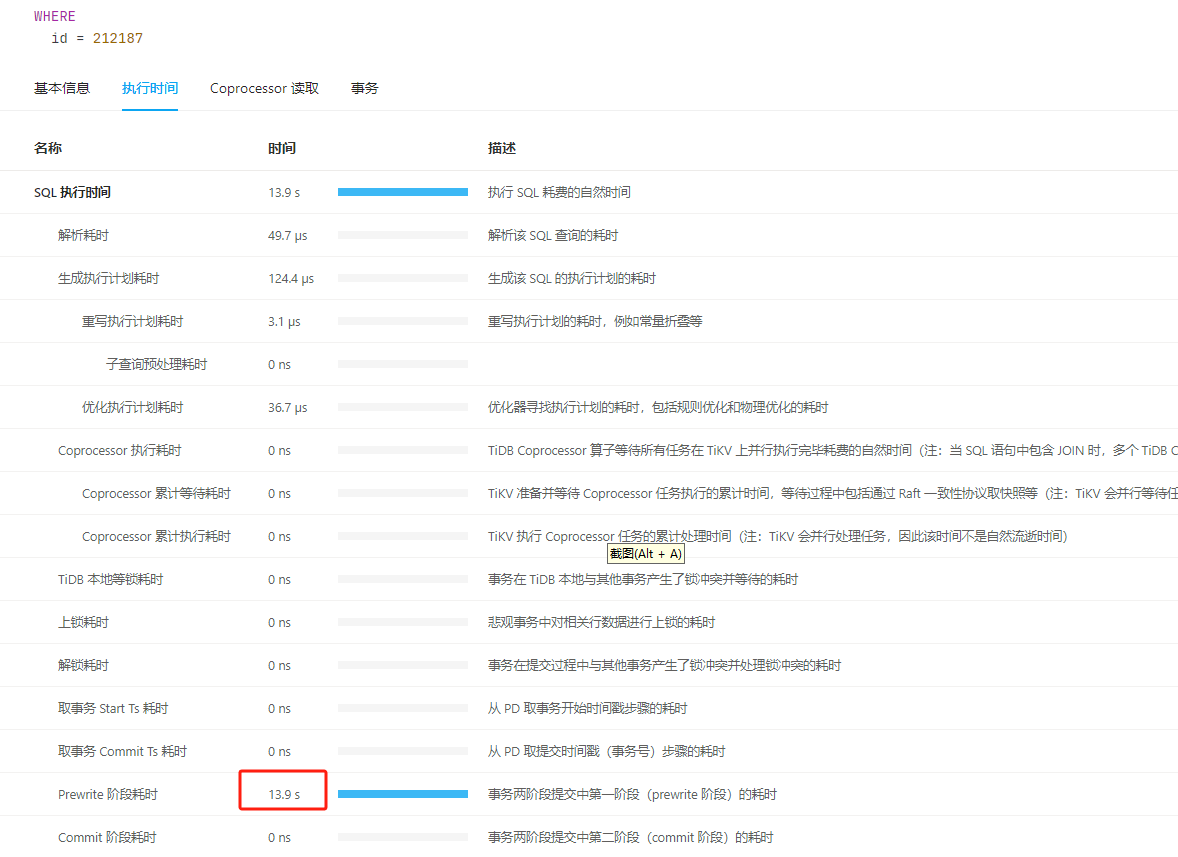
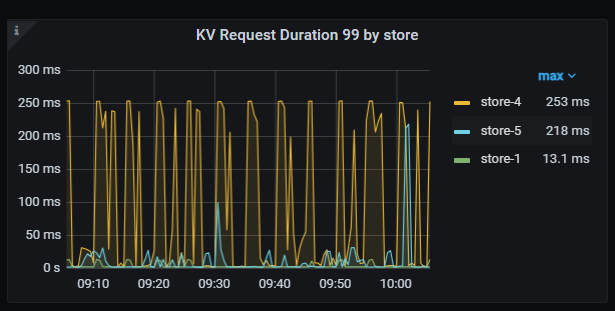
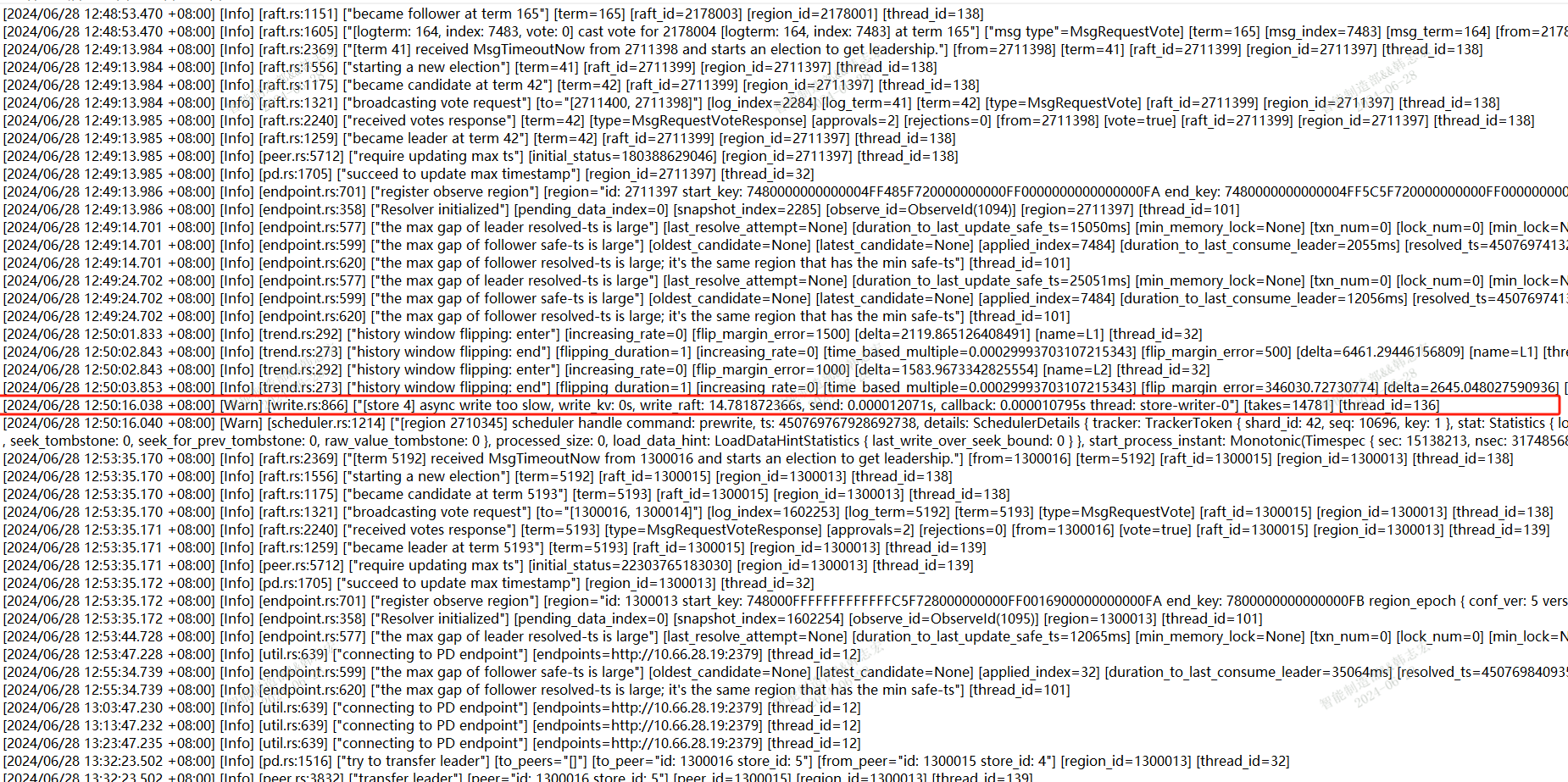
tidb数据库总共配置了9个节点,3个PD、3个TidbServer、3个TiKV(25、26、27). 最近总是服务间歇性出现写入性能问题,问题发生时更新数据的简单SQL会执行时间在10秒以上。目前故障没有明显的规律可循,发生时间和执行时间过长的SQL都是不固定的,检查故障发生时主机运行参数,也没发现主机CPU、内存、磁盘IO、网络等参数没有明显的大幅变化。我通过dashboard的“慢查询”功能,定位到更新慢的SQL,打开SQL查看执行时间,发现耗时主要是在“Prewrite 阶段耗时”这个参数上。在dashboard上的25节点日志上可以看到同一时间点有报错“[store 4] async write too slow, write_kv: 0s, write_raft: 14.781872366s, send: 0.000012071s, callback: 0.000010795s thread: store-writer-0"] [takes=14781] [thread_id=136]”,根据意思我理解是raft日志写入时间过长花费了14.7秒时间。 根据这个线索,查看了grafana系统上的tidb参数,排除了几种可能原因:
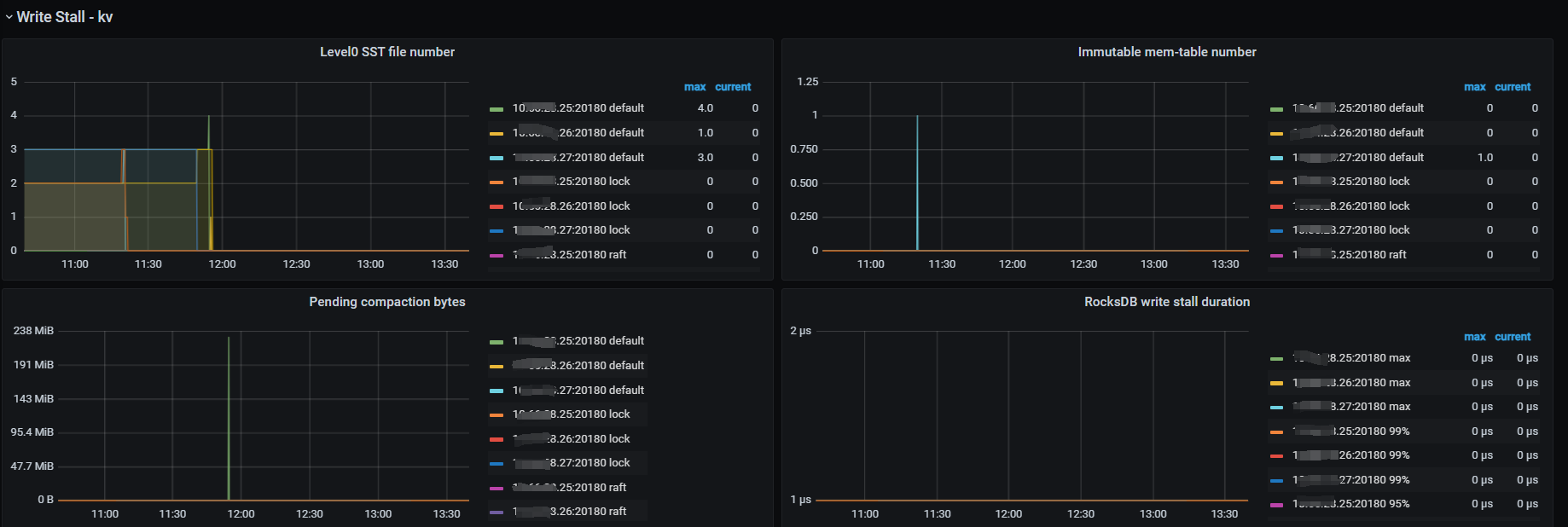
- 排除region压缩造成的短时间性能问题。(write Stall kv 下的参数正常,没有明显的变化)
- 排除region分步不均造成的写压力问题。(db-bigdata-accdb-Overview面板的region参数正常)
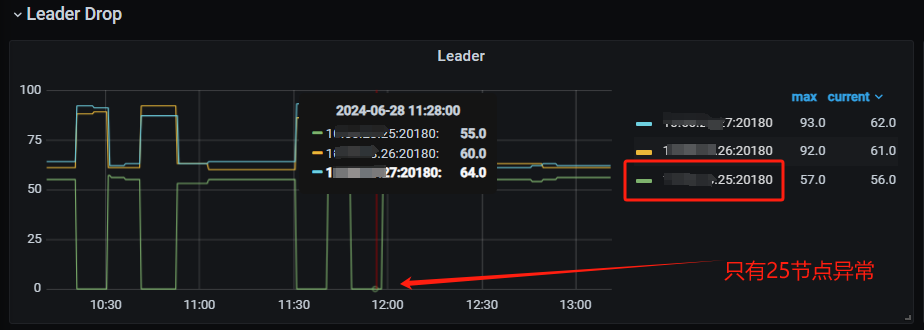
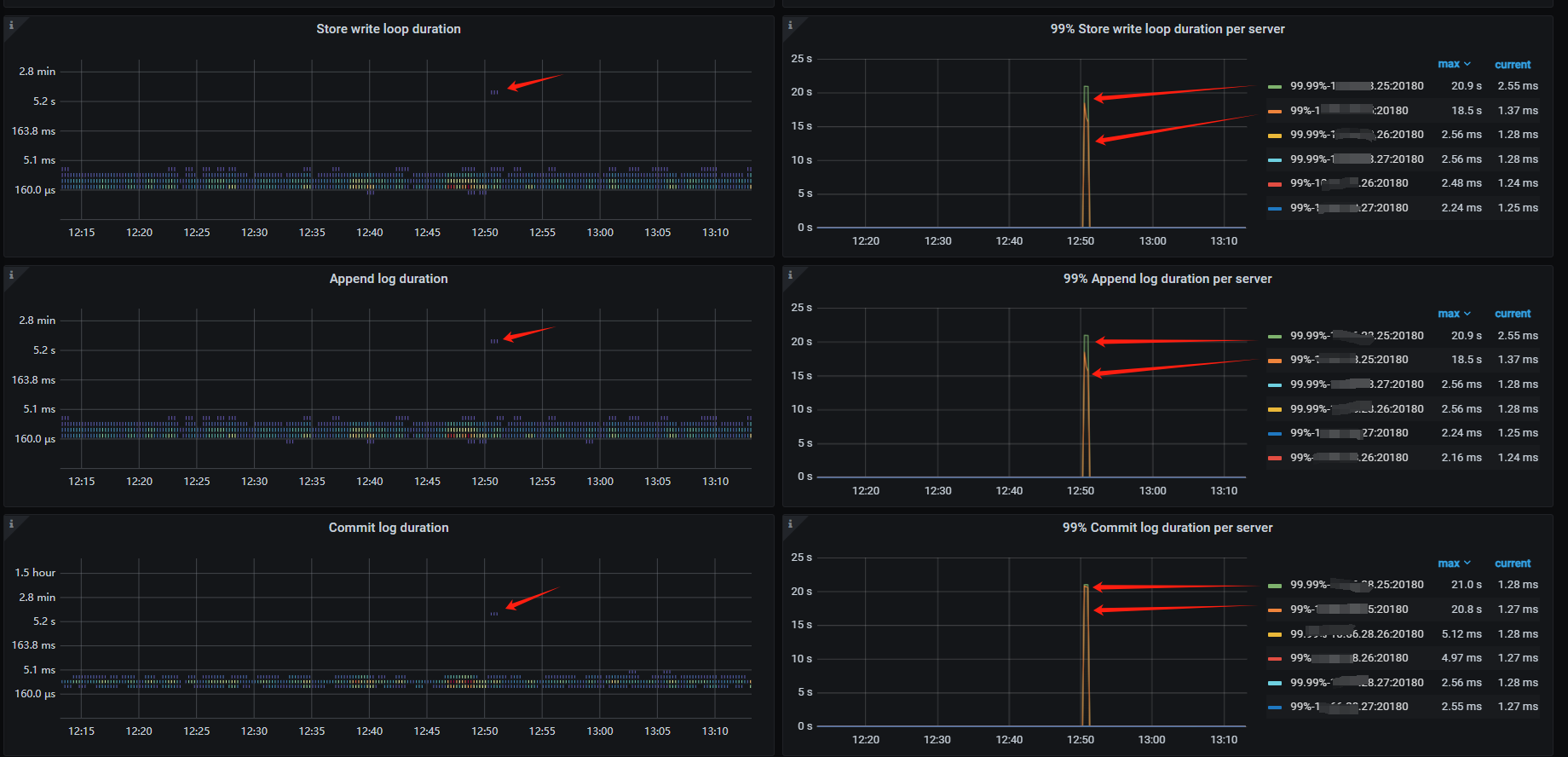
目前怀疑是25节点的raft日志写入时的问题。因为抽查了多个慢SQL,通过事务号查询发现都是发生在TikV的25节点上,对于12:50的故障案例, 也是发生在25节点。并且,25节点在12:50 的Append Log 、Commit Log 时间长超过10秒。另外查询日志还发现一个比异常的问题,统计了1周的数据发现,25节点总是出现transfer leader事件,并且从图表看有时25上的leader直接变为0,而26、27节点没这个问题。
现在问题还是在频繁发生没有解决,我使用tidb数据库的时间只有半年没有太多经验,请论坛里的大拿、专家帮忙分析一下可能的原因,给出一些解决建议。不胜感激,谢谢!
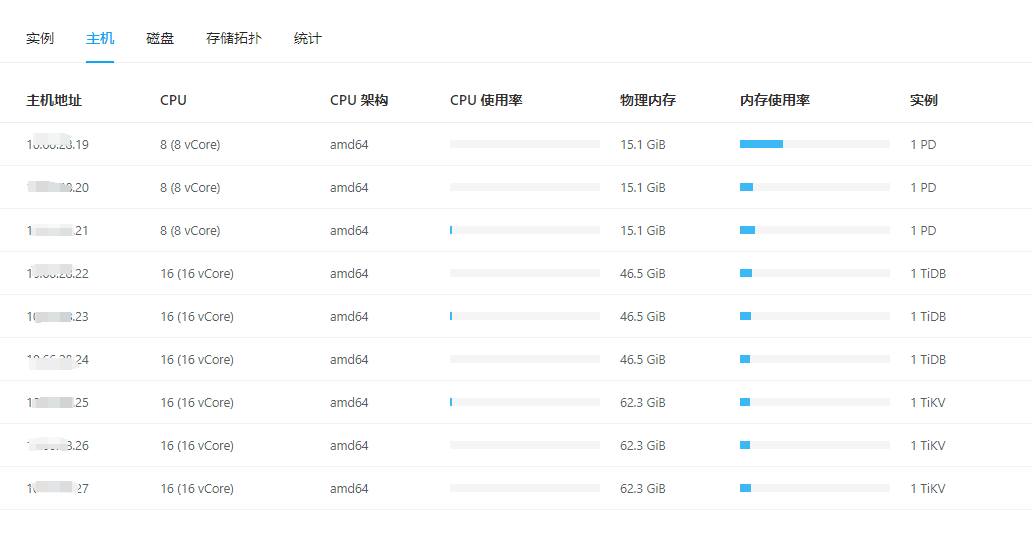
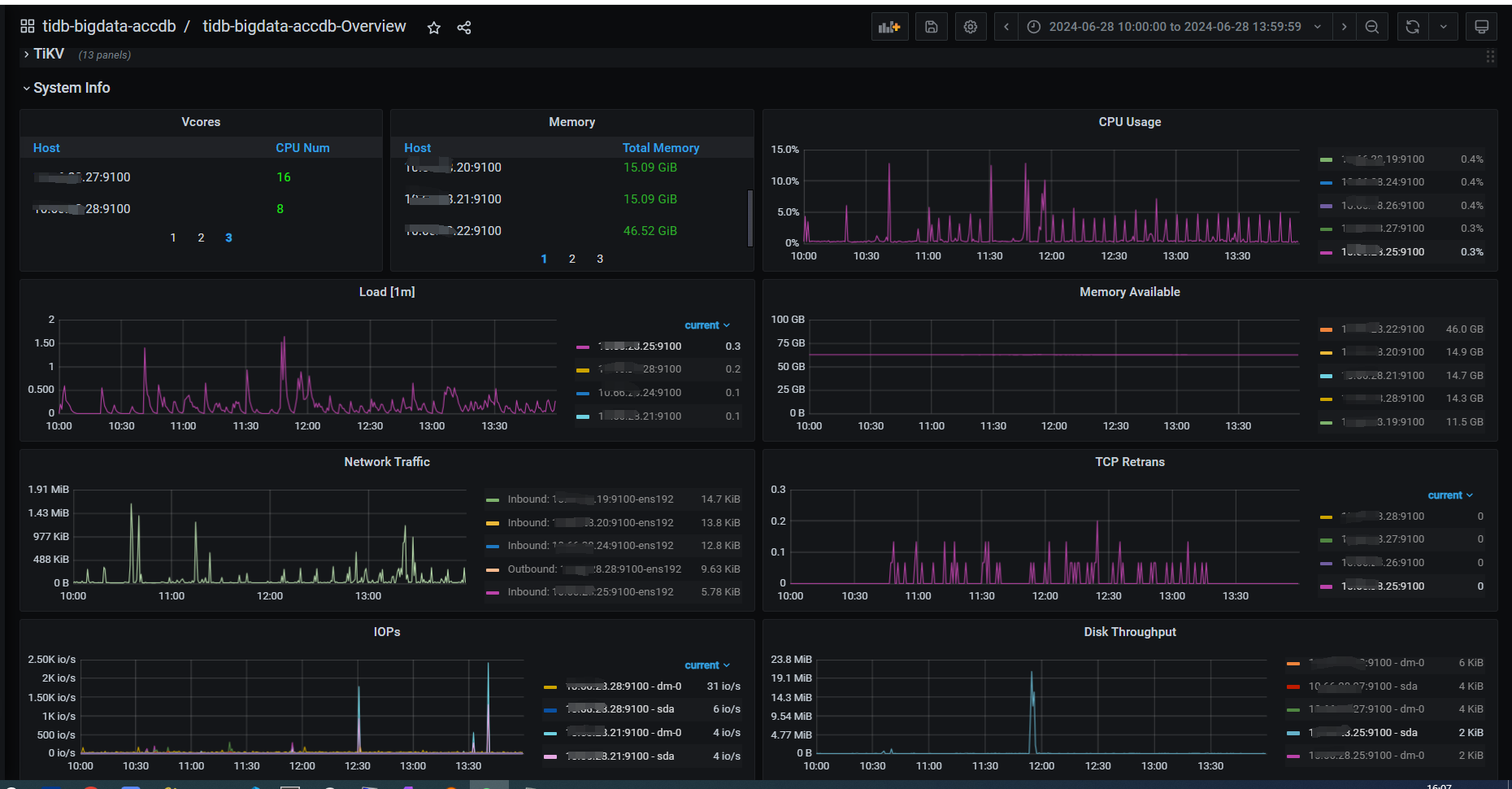
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面

【附件:截图/日志/监控】

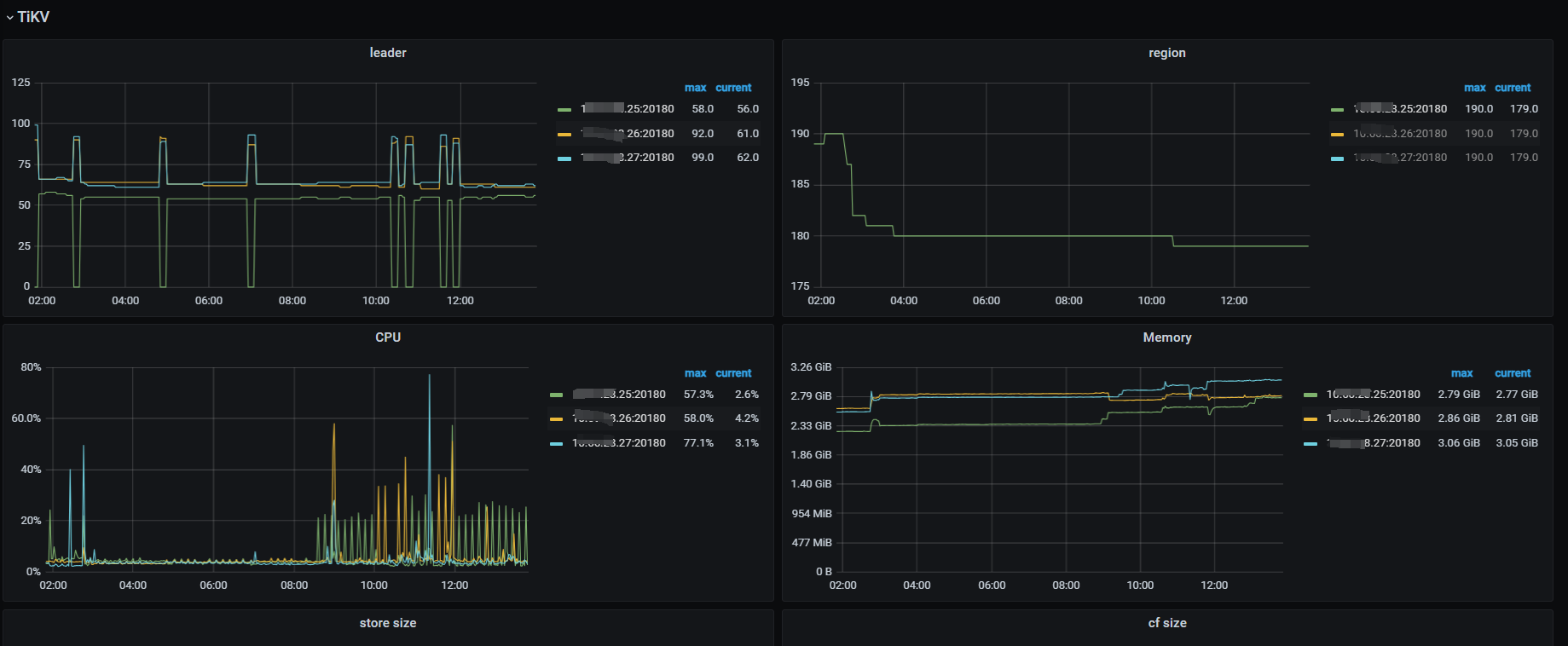
CPU、内存
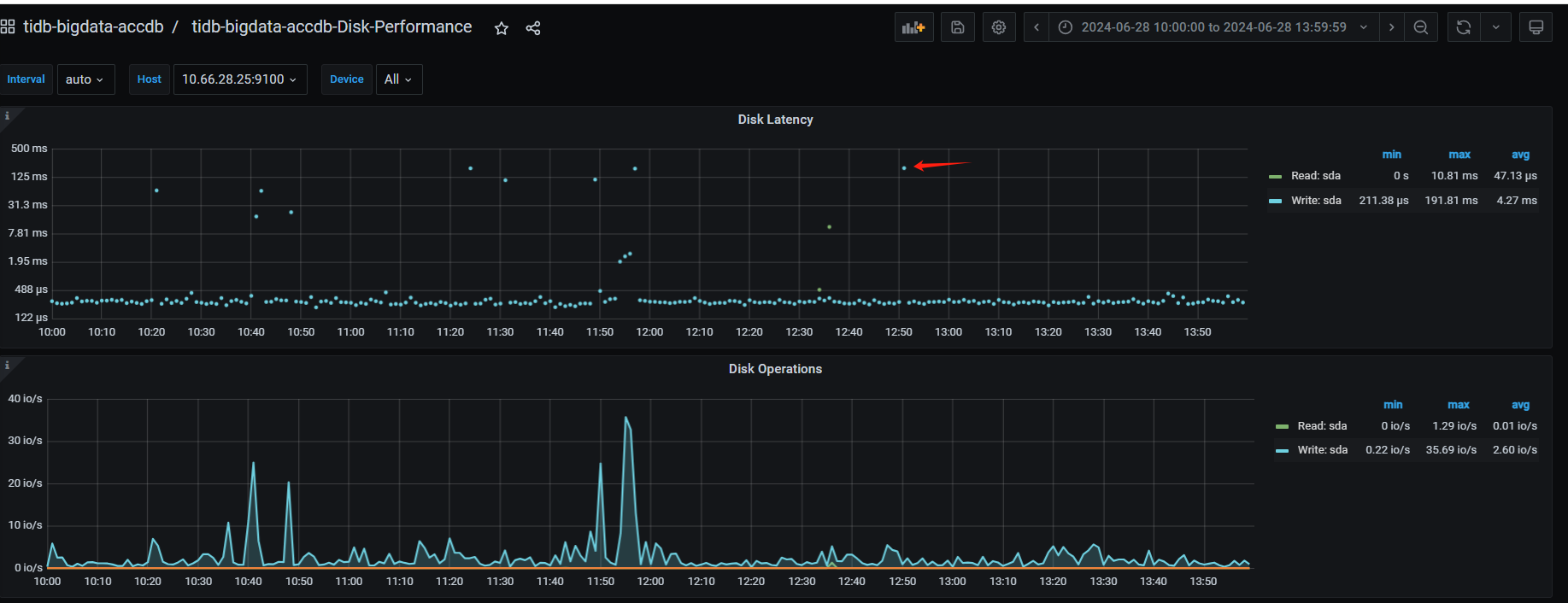
磁盘
25的磁盘
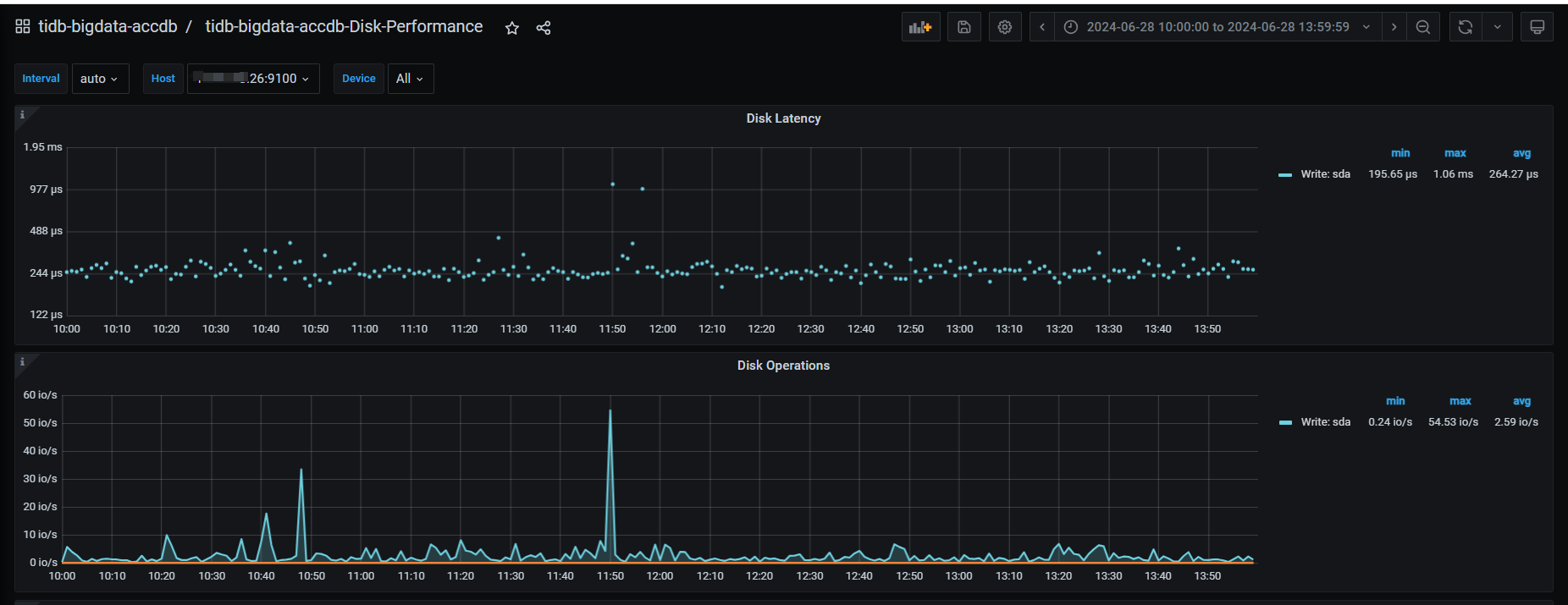
26的磁盘
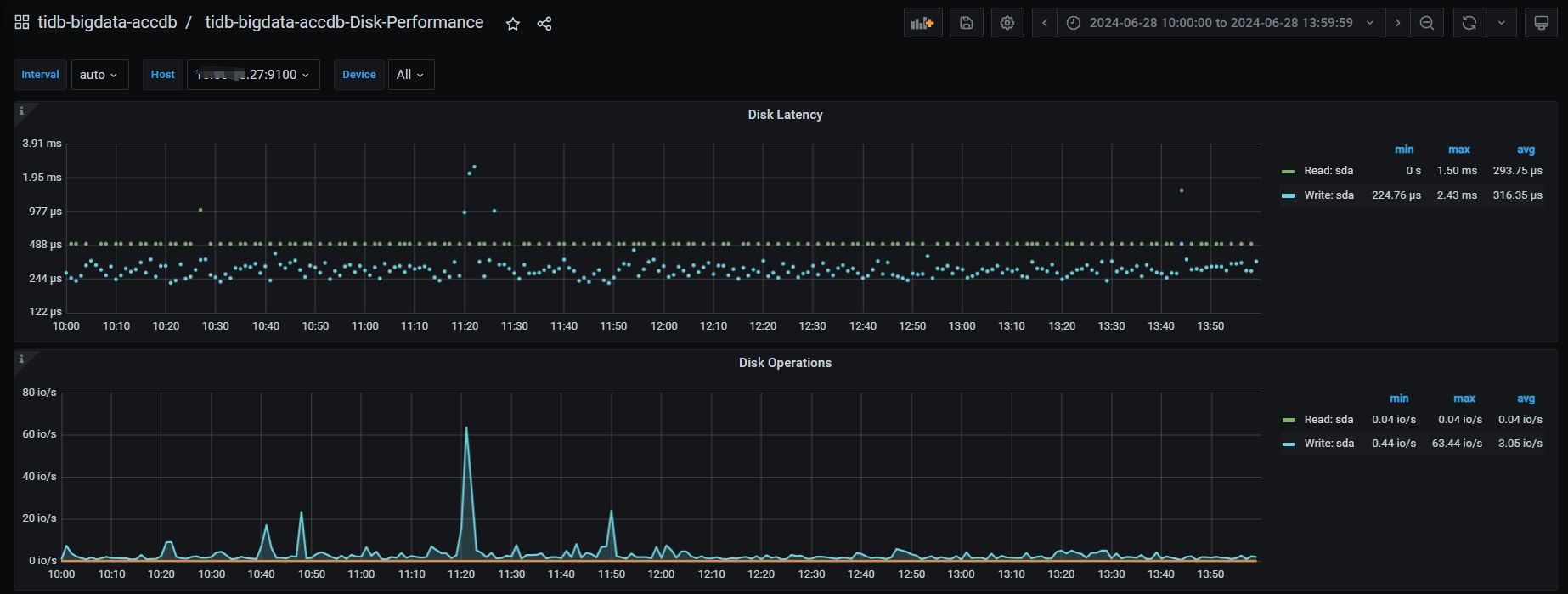
27的磁盘
日志
logs-tikv_10.66.28.25_20160.zip (3.3 KB)
锁的统计信息