【 TiDB 使用环境】生产环境
【 TiDB 版本】V6.3.0
求救求救!!!
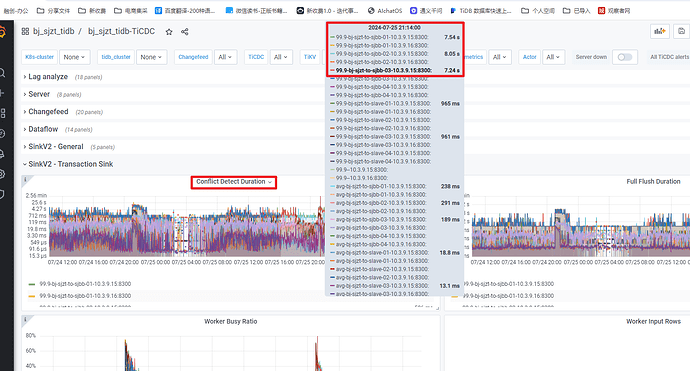
我们的TiCDC在同步到下游的TiDB集群的时候同步速率过慢,看监控发现有一个指标很异常,就是下图中的冲突检测耗时时间有十几秒,这是为什么呢?Ps.我们的同步表是一个3亿数据的大表
【 TiDB 使用环境】生产环境
【 TiDB 版本】V6.3.0
求救求救!!!
我们的TiCDC在同步到下游的TiDB集群的时候同步速率过慢,看监控发现有一个指标很异常,就是下图中的冲突检测耗时时间有十几秒,这是为什么呢?Ps.我们的同步表是一个3亿数据的大表
看下 cdc 日志。可能任务配置的表有重叠,或者有数据冲突。
看看 cdc 日志里面一些 WARN 或者 ERROR 日志吧。
系统中有大量的如下报警
[2024/06/25 21:02:58.717 +08:00] [WARN] [system.go:578] [“actor poll received messages too slow”] [duration=1.929320332s] [id=6] [name=sorter-compactor]
[2024/06/25 21:03:02.853 +08:00] [WARN] [pd.go:152] [“get timestamp too slow”] [“cost time”=50.068307ms]
[2024/06/25 21:03:09.157 +08:00] [WARN] [pd.go:152] [“get timestamp too slow”] [“cost time”=353.648823ms]
cdc中的日志中如如下大量报警
[2024/06/25 21:02:58.717 +08:00] [WARN] [system.go:578] [“actor poll received messages too slow”] [duration=1.929320332s] [id=6] [name=sorter-compactor]
[2024/06/25 21:03:02.853 +08:00] [WARN] [pd.go:152] [“get timestamp too slow”] [“cost time”=50.068307ms]
[2024/06/25 21:03:09.157 +08:00] [WARN] [pd.go:152] [“get timestamp too slow”] [“cost time”=353.648823ms]
额 你是是不是资源使用率很高啊。看起来 get tso 和排序数据时间都挺久的。
对 就是排序时间比较久,但是cdc的内存,io和cpu都不高,也不知道到底瓶颈在哪里
我看了下,确实tso比较高,这个tso会受什么的影响,这个不就是从pd获取时间戳吗,怎么变慢呢
PD服务器很繁忙吗
没有其他日志了么?
集群负载如何?比如内存使用率、CPU使用率?是不是集群负载太高了
你这是写入长时间没有提交,回滚了看起来。然后不停重试啊 ![]() 。
。
是的,怎么会出现这种情况呢
你去下游 tidb 分析下 SQL 执行慢在哪里。