应该就是测试环境,生产环境谁会节省这点资源 ![]()
![]() 弹药充足要运维干什么,就是得有点难度,才能彰显运维的能力
弹药充足要运维干什么,就是得有点难度,才能彰显运维的能力
可以,但是生产环境不建议。毕竟生产环境也不会在乎这点资源了。
这些不好用吗 挺好的啊 就算不用,也没必要停掉啊
关了这些不就裸奔了吗,出问题没办法报警
理论上当然可行,这些都是监控用组件,关键是关闭了拿什么来监控啊
真是什么需求都有啊,这么方便的开箱即用,为啥非要去掉呢,即使不是生产环境也不建议去掉
日志应该还是有吧,可以监控日志。
prometheus、grafana监控最好还是保留,运维还是经常用到的,alertmanager可以缩容
可以,这些不是集群的必须组件,只是监控和运维组件,但是一般还是保留比较好,集群出问题方便排查异常信息
监控组件是TiDB集群的一个优势之一,没必要为了省这点资源关闭
资源占用不大,感觉没有必要,确实要的话,就缩容或者直接通过tiup cluster stop tidb-lhf --node prometheus节点的IP:端口 进行关闭
测试环境无所谓,生产环境还是高标准要求
可以,不过会影响运维效率
可以关掉。tidb太稳了
可以了吗,就是缺少监控了
监控dashboard上也有 top sql 热力图都有,但报警没了。你自己评估。如果tidb是高配置的,或者是自动伸缩的。都可以去掉监控。
我这里简单贴点代码
做好2点。
一个计算层自动扩容
一个存储层自动扩容
根据io自动扩容
import boto3
配置您的 AWS 访问密钥和区域
aws_access_key_id = 'YOUR_ACCESS_KEY'
aws_secret_access_key = 'YOUR_SECRET_KEY'
region_name = 'YOUR_REGION'
初始化 Boto3 客户端
autoscaling_client = boto3.client(
'autoscaling',
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=region_name
)
cloudwatch_client = boto3.client(
'cloudwatch',
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=region_name
)
定义 Auto Scaling 组的名称和最小/最大实例数
autoscaling_group_name = 'your-auto-scaling-group-name'
min_size = 1
max_size = 5
更新 Auto Scaling 组的最小和最大大小
response = autoscaling_client.update_auto_scaling_group(
AutoScalingGroupName=autoscaling_group_name,
MinSize=min_size,
MaxSize=max_size
)
定义扩展策略的参数
scaling_policy_name = 'io-based-scaling-policy'
namespace = 'AWS/EC2'
metric_name = 'VolumeReadBytes'
dimensions = [
{
'Name': 'AutoScalingGroupName',
'Value': autoscaling_group_name
}
]
创建 CloudWatch 告警,当磁盘 I/O 超过阈值时触发
alarm_name = 'high-io-alarm'
comparison_operator = 'GreaterThanThreshold'
evaluation_periods = 1
period = 60 # 60 秒
threshold = 600 * 1024 * 1024 # 600MB
alarm_action = 'arn:aws:autoscaling:::scalingPolicy:' + scaling_policy_name
cloudwatch_client.put_metric_alarm(
AlarmName=alarm_name,
AlarmDescription='Scale-up when disk I/O is high',
MetricName=metric_name,
Namespace=namespace,
Statistic='Sum',
Dimensions=dimensions,
Period=period,
EvaluationPeriods=evaluation_periods,
Threshold=threshold,
ComparisonOperator=comparison_operator,
AlarmActions=[alarm_action],
Unit='Bytes'
)
创建 Application Auto Scaling 策略
response = autoscaling_client.put_scaling_policy(
PolicyName=scaling_policy_name,
PolicyType='SimpleScaling',
AdjustmentType='ChangeInCapacity',
AutoScalingGroupName=autoscaling_group_name,
ScalingAdjustment=1, # 增加的实例数
Cooldown=300
)
print(response)
import boto3
创建boto3客户端
cloudwatch = boto3.client('cloudwatch')
autoscaling = boto3.client('autoscaling')
创建CloudWatch Alarm
alarm_name = 'HighDiskIOAlarm'
comparison_operator = 'GreaterThanThreshold'
evaluation_periods = 1
metric_name = 'DiskReadBytes+DiskWriteBytes'
namespace = 'AWS/EC2'
period = 60 # 60 seconds
statistic = 'Sum'
threshold = 600 * 1024 * 1024 # 600MB
alarm_description = 'Alarm if disk IO is high'
unit_of_measure = 'Bytes'
response = cloudwatch.put_metric_alarm(
AlarmName=alarm_name,
EvaluationPeriods=evaluation_periods,
AlarmActions=['arn:aws:sns:region:account-id:sns-topic'],
AlarmDescription=alarm_description,
ComparisonOperator=comparison_operator,
MetricName=metric_name,
Namespace=namespace,
Period=period,
Statistic=statistic,
Threshold=threshold,
Unit=unit_of_measure
)
创建Scaling Policy
policy_name = 'ScaleUpPolicy'
scaling_adjustment = 1 # 增加的实例数量
adjustment_type = 'ChangeInCapacity'
policy_response = autoscaling.put_scaling_policy(
AutoScalingGroupName='your-asg-name',
PolicyName=policy_name,
PolicyType='Simple',
ScalingAdjustment=scaling_adjustment,
AdjustmentType=adjustment_type
)
将Alarm和Scaling Policy关联(需要使用CloudWatch Alarm的ARN和SNS Topic)
alarm_arn = response['AlarmArn']
sns_topic_arn = 'arn:aws:sns:region:account-id:sns-topic'
根据计算自动扩容
------------------创建auto scaling-------
import boto3
import time
import yaml
import subprocess
# 创建 EC2 客户端
ec2_client = boto3.client('ec2', region_name='ap-northeast-1')
autoscaling_client = boto3.client('autoscaling', region_name='ap-northeast-1')
# 创建启动配置
launch_configuration_name = 'my-launch-configuration'
autoscaling_client.create_launch_configuration(
LaunchConfigurationName=launch_configuration_name,
ImageId='ami-0a0b7b240264a48d7', # 替换为 Ubuntu 2024 的 AMI ID
KeyName='dba-used-key-pair',
InstanceType='t2.large',
# SecurityGroups=['launch-wizard-3'],
)
# 创建 Auto Scaling 组
autoscaling_group_name = 'my-auto-scaling-group'
autoscaling_client.create_auto_scaling_group(
AutoScalingGroupName=autoscaling_group_name,
LaunchConfigurationName=launch_configuration_name,
MinSize=1,
MaxSize=2,
DesiredCapacity=1,
VPCZoneIdentifier='subnet-05f2763471de42b2a,subnet-00a7f63247b5824d4', # 替换为你的子网 ID
Tags=[
{
'Key': 'Name',
'Value': 'my-spot-instance'
}
]
)
创建 ALB
load_balancer_name = 'my-load-balancer'
load_balancer = elbv2_client.create_load_balancer(
Name=load_balancer_name,
Subnets=['subnet-05f2763471de42b2a','subnet-00a7f63247b5824d4'], # 替换为有效的子网 ID 列表
#SecurityGroups=[...], # 替换为有效的安全组 ID 列表
Scheme='internet-facing', # 或者 'internal',取决于您的需要
Type='application', # 'application' 或 'network'
)
获取 VPC ID
vpc_id = load_balancer['VpcId']
创建目标组
target_group_name = 'my-target-group'
target_group = elbv2_client.create_target_group(
Name=target_group_name,
Port=4000, # 目标端口
Protocol='HTTP',
VpcId=vpc_id,
TargetType='instance', # 'instance' 或 'ip'
)
target_group_arn = target_group['TargetGroupArn']
创建监听器
listener_port = 4000 # 监听器端口
listener_protocol = 'HTTP' # 'HTTP' 或 'HTTPS'
default_action = {
'Type': 'forward',
'TargetGroupArn': target_group_arn,
'ForwardConfig': {
'TargetGroups': [
{
'TargetGroupArn': target_group_arn,
'Weight': 1
}
],
'TargetGroupStickinessConfig': {
'Enabled': False
}
}
}
listener = elbv2_client.create_listener(
LoadBalancerArn=load_balancer['LoadBalancerArn'],
Port=listener_port,
Protocol=listener_protocol,
DefaultActions=[default_action]
)
等待 Auto Scaling 组至少有一个健康的实例
print("Waiting for at least one healthy instance in the Auto Scaling group...")
waiter = autoscaling_client.get_waiter('instance_in_service')
waiter.wait(AutoScalingGroupNames=[autoscaling_group_name], WaiterConfig={
'MaxAttempts': 60,
'Delay': 30
})
关联 Auto Scaling 组和目标组
autoscaling_client.attach_load_balancer_target_groups(
AutoScalingGroupName=autoscaling_group_name,
TargetGroupARNs=[target_group_arn]
)
------------------自动扩容监控脚本-------
import boto3
import time
import yaml
import subprocess
autoscaling_group_name = 'my-auto-scaling-group'
# 创建扩展策略
scale_out_policy = autoscaling_client.put_scaling_policy(
AutoScalingGroupName=autoscaling_group_name,
PolicyName='scale-out',
AdjustmentType='ChangeInCapacity',
ScalingAdjustment=1,
Cooldown=30
)
# 创建缩减策略
scale_in_policy = autoscaling_client.put_scaling_policy(
AutoScalingGroupName=autoscaling_group_name,
PolicyName='scale-in',
AdjustmentType='ChangeInCapacity',
ScalingAdjustment=-1,
Cooldown=30
)
def run_shell_addcommand(ip_address):
command = f"tiup cluster scale-out tidb-test ./deploybackup.yaml --user ubuntu -i dba.pem -y"
subprocess.run(command, shell=True)
def run_shell_removecommand(ip_address):
command = f"tiup cluster scale-in tidb-test -N '{ip_address}:20160'"
subprocess.run(command, shell=True)
# 创建 CloudWatch 警报
cloudwatch_client = boto3.client('cloudwatch', region_name='ap-northeast-1')
# 扩展警报
cloudwatch_client.put_metric_alarm(
AlarmName='scale-out-alarm',
MetricName='CPUUtilization',
Namespace='AWS/EC2',
Statistic='Average',
Period=60, # 1 小时
EvaluationPeriods=1, # 2 小时
Threshold=10.0,
ComparisonOperator='GreaterThanOrEqualToThreshold',
# ComparisonOperator='LessThanOrEqualToThreshold',
AlarmActions=[scale_out_policy['PolicyARN']],
Dimensions=[
{
'Name': 'AutoScalingGroupName',
'Value': autoscaling_group_name
}
]
)
# 缩减警报
cloudwatch_client.put_metric_alarm(
AlarmName='scale-in-alarm',
MetricName='CPUUtilization',
Namespace='AWS/EC2',
Statistic='Average',
# Period=86400, # 24 小时
Period=86400, # 24 小时
EvaluationPeriods=1,
Threshold=10.0,
ComparisonOperator='LessThanOrEqualToThreshold',
AlarmActions=[scale_in_policy['PolicyARN']],
Dimensions=[
{
'Name': 'AutoScalingGroupName',
'Value': autoscaling_group_name
}
]
)
# 更新 deploy.yaml 文件
def update_deploy_yaml(action, instance_ip):
with open('deploy.yaml', 'r') as file:
deploy_config = yaml.safe_load(file)
# instance = ec2_client.describe_instances(InstanceIds=[instance_id])
# instance_ip = instance['Reservations'][0]['Instances'][0]['PrivateIpAddress']
if action == 'add':
deploy_config['tikv_servers'].append({'host': instance_ip})
deploy_config['tikv_servers'] = [server for server in deploy_config['tikv_servers'] if server['host'] != '1.1.1.1']
with open('deploybackup.yaml', 'w') as file:
yaml.safe_dump(deploy_config, file)
# 触发扩容后立即执行 Python 脚本
def execute_scale_out_script():
print("扩容触发,执行脚本...")
# 获取新增实例的 ID
response = autoscaling_client.describe_auto_scaling_groups(AutoScalingGroupNames=[autoscaling_group_name])
instance_ids = [instance['InstanceId'] for instance in response['AutoScalingGroups'][0]['Instances'] if instance['LifecycleState'] == 'InService']
for instance_id in instance_ids:
# 描述实例以获取网络接口信息
describe_instances_response = ec2_client.describe_instances(InstanceIds=[instance_id])
instance_data = describe_instances_response['Reservations'][0]['Instances'][0]
for network_interface in instance_data['NetworkInterfaces']:
if network_interface['NetworkInterfaceId'] == instance_data['NetworkInterfaces'][0]['NetworkInterfaceId']:
private_ip = network_interface['PrivateIpAddress']
print(f"Instance ID: {instance_id}, Private IP: {private_ip}")
update_deploy_yaml('add', private_ip) # 假设
run_shell_addcommand(private_ip)
print(private_ip)
# 触发缩减后立即执行 Python 脚本
def execute_scale_in_script():
print("缩减触发,执行脚本...")
# 获取被移除实例的 ID
response = autoscaling_client.describe_auto_scaling_groups(AutoScalingGroupNames=[autoscaling_group_name])
instance_ids = [instance['InstanceId'] for instance in response['AutoScalingGroups'][0]['Instances'] if instance['LifecycleState'] == 'Terminating']
for instance_id in instance_ids:
update_deploy_yaml('remove', instance_id)
run_shell_removecommand(ip_address)
# 模拟扩容和缩减触发
while True:
# 检查扩展警报状态
alarms = cloudwatch_client.describe_alarms(AlarmNames=['scale-out-alarm'])
for alarm in alarms['MetricAlarms']:
if alarm['StateValue'] == 'ALARM':
execute_scale_out_script()
# 检查缩减警报状态
alarms = cloudwatch_client.describe_alarms(AlarmNames=['scale-in-alarm'])
for alarm in alarms['MetricAlarms']:
if alarm['StateValue'] == 'ALARM':
execute_scale_in_script()
time.sleep(60) # 每 5 分钟检查一次
执行效果如下
果如下
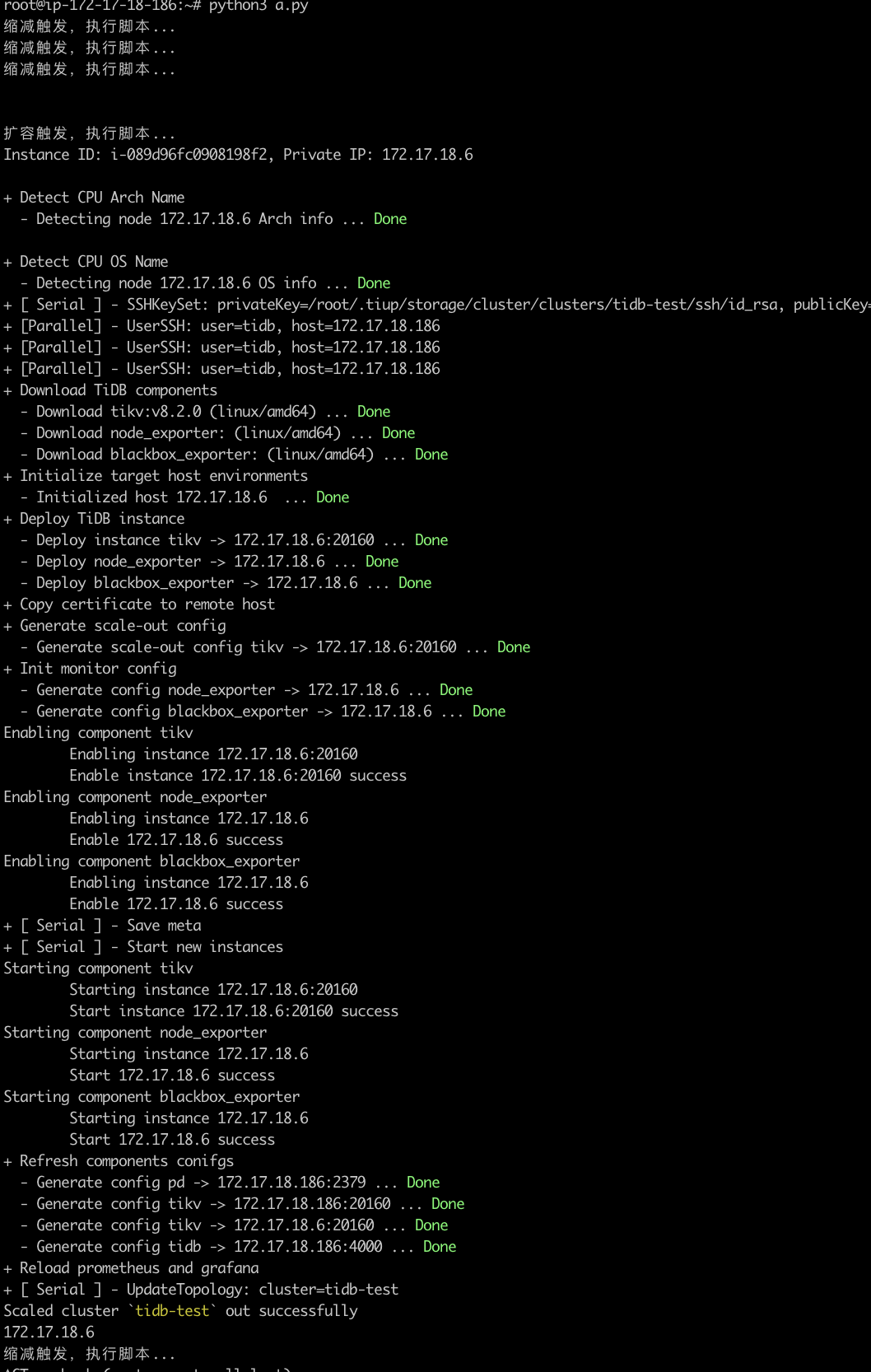
Tidb的监控是对DBA很好的管理方式。不建议关闭
应该是缩容操作吧
当然可以了。不过关闭后就没有办法观察组件的报警信息了