panqiao
(Ti D Ber Qb358ha7)
1
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】6.5.5
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
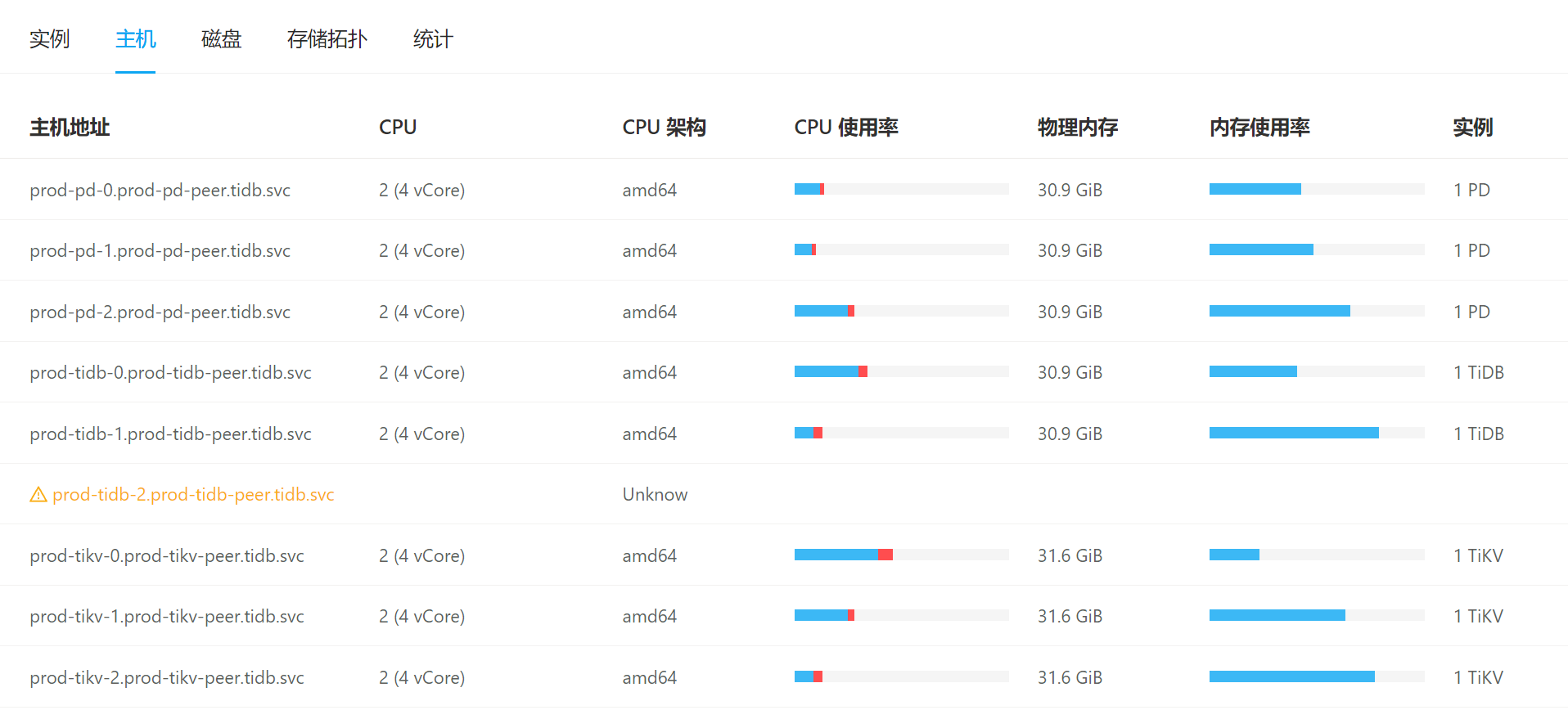
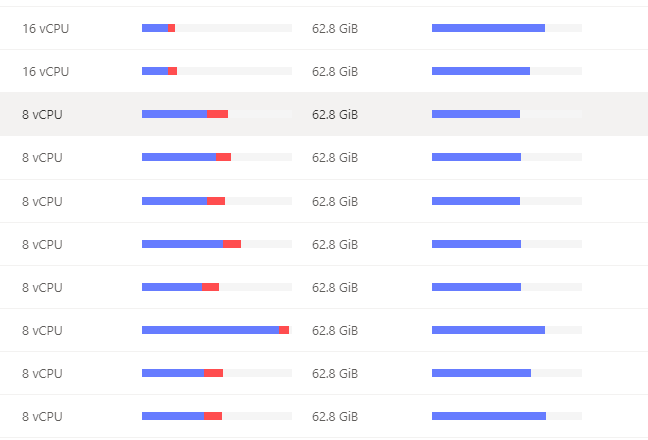
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
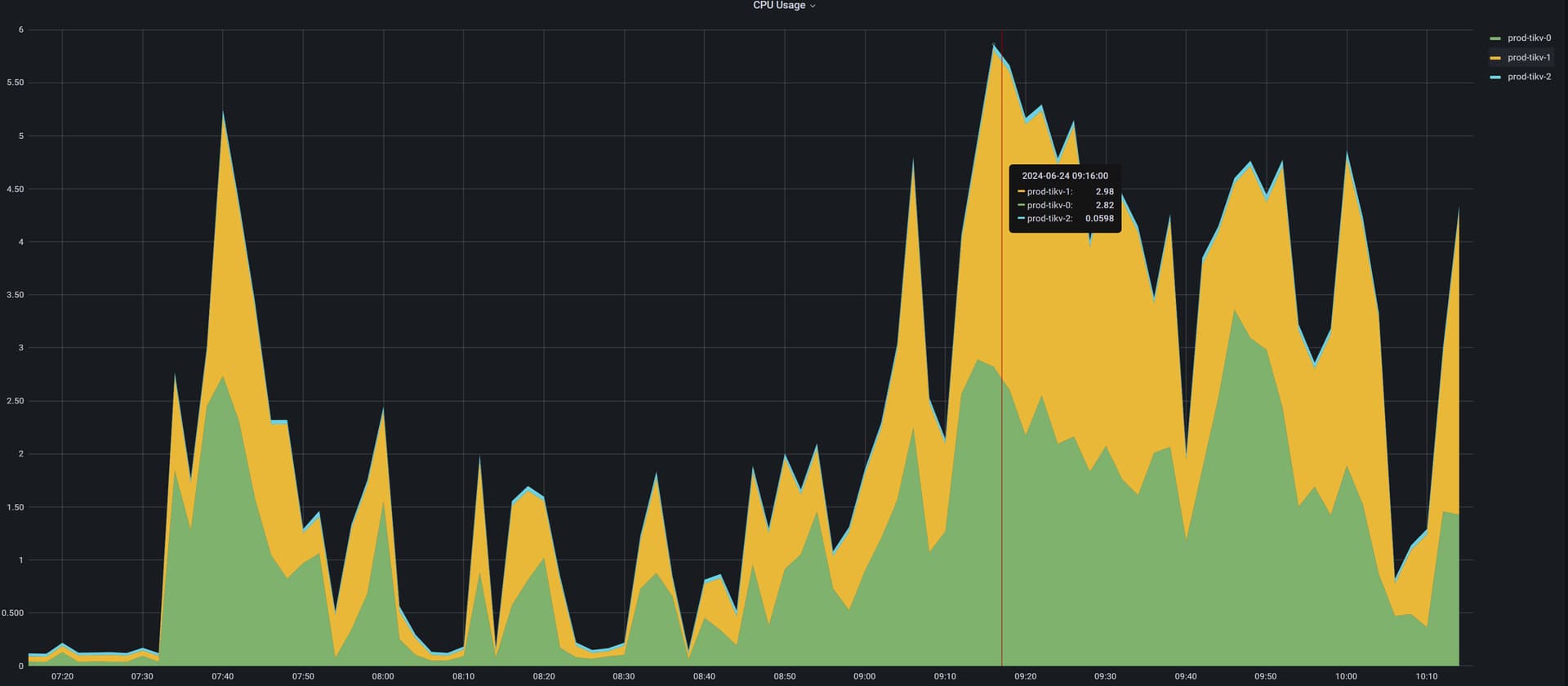
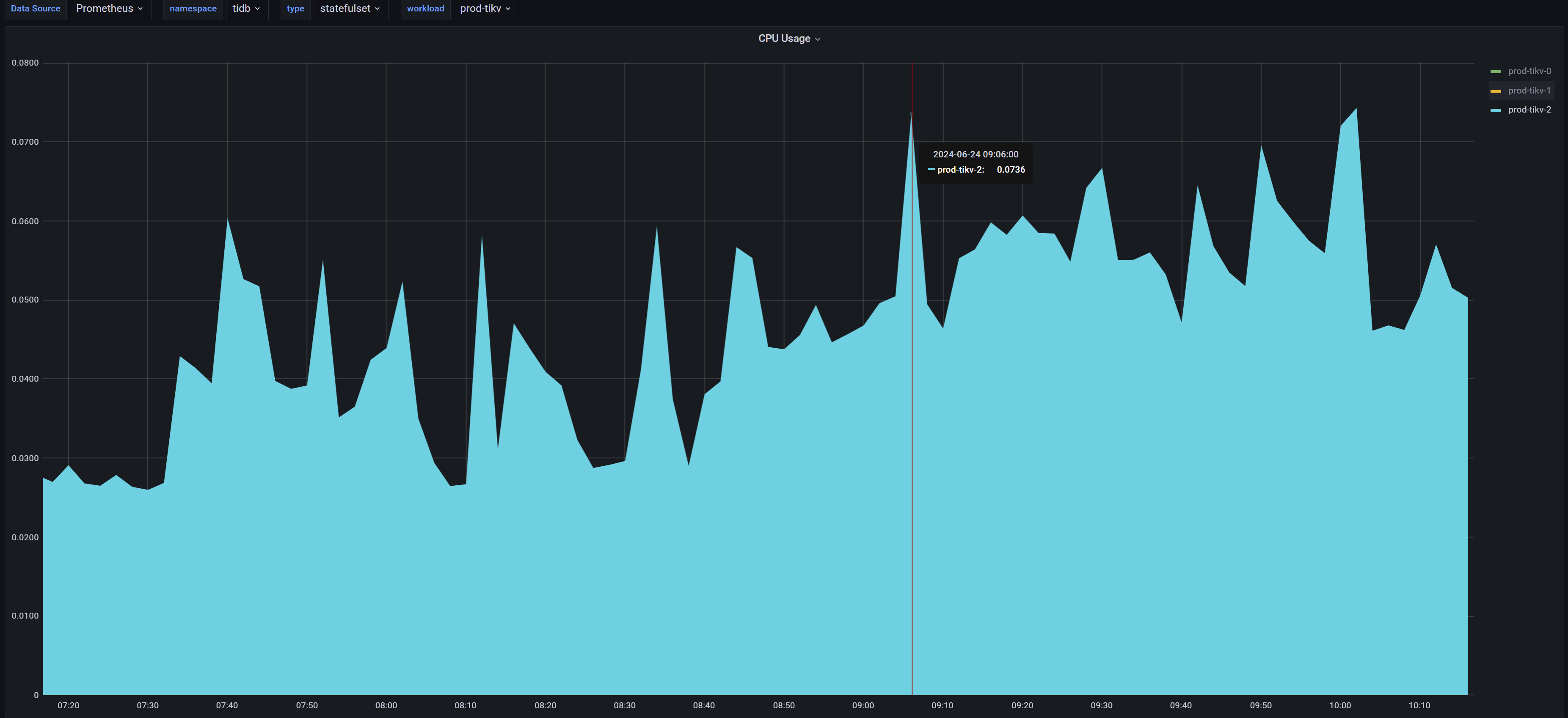
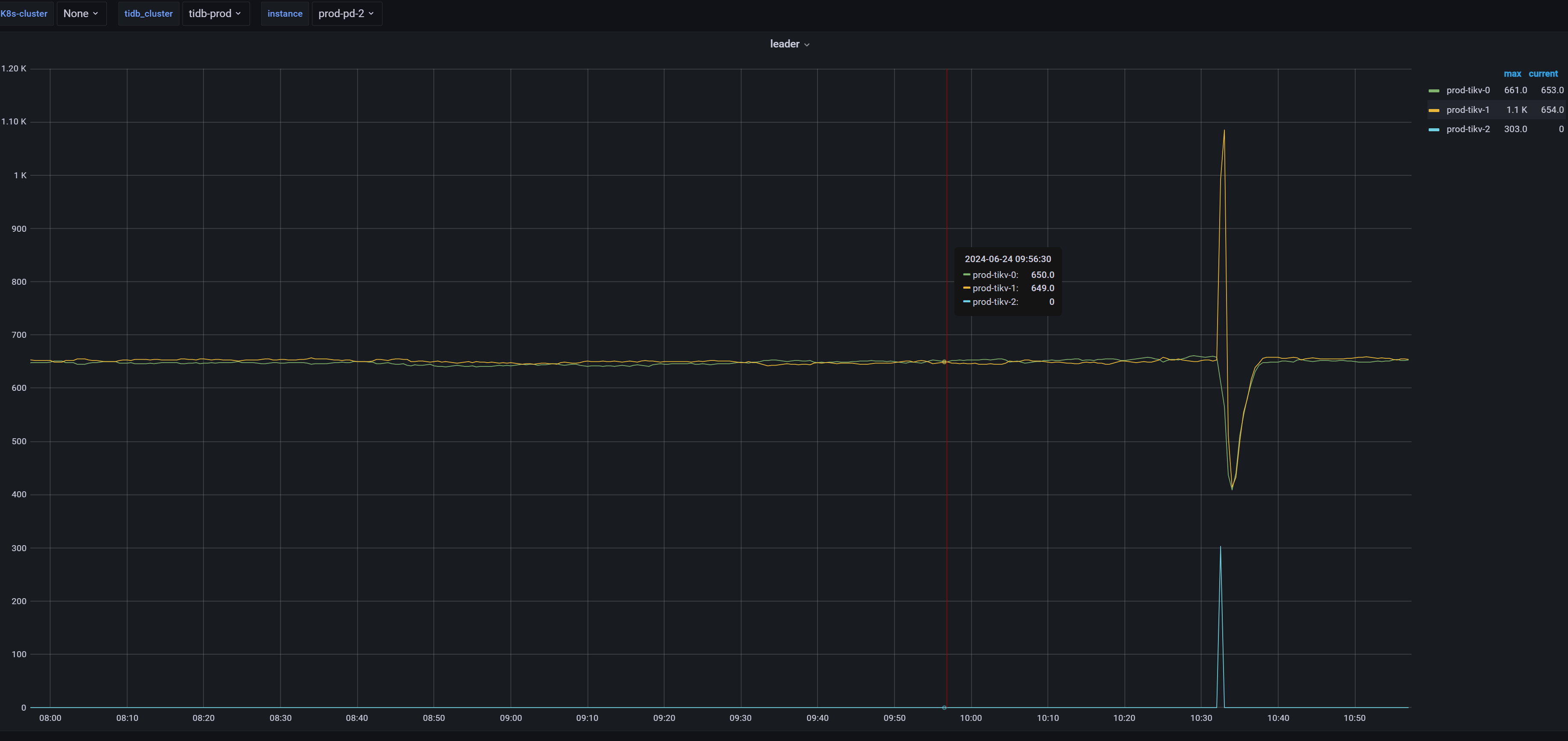
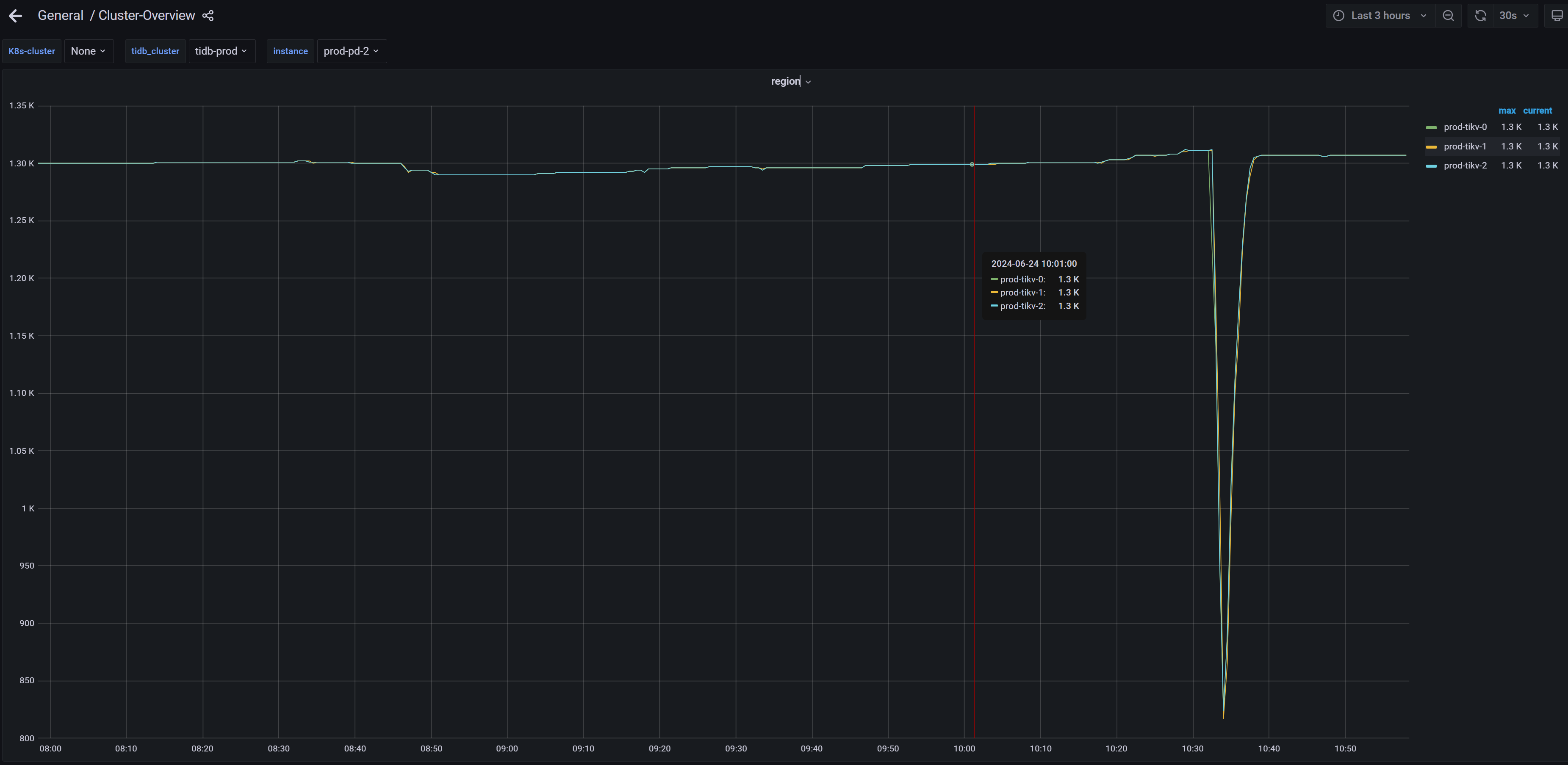
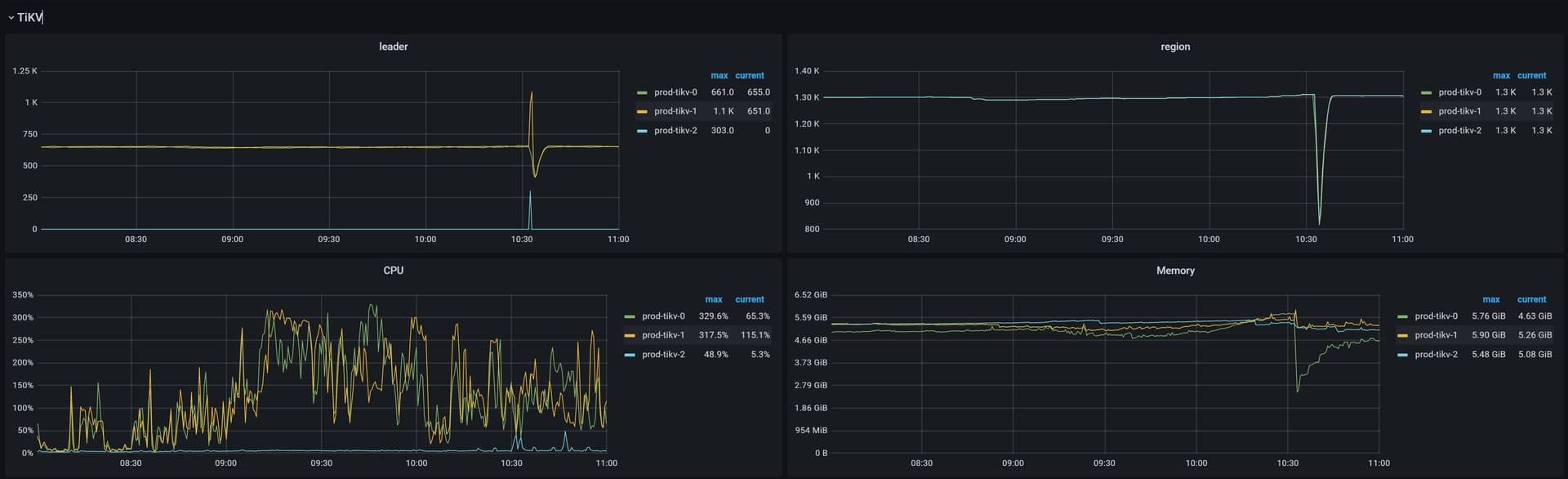
系统很慢,然后查看数据库有很多慢查询,tikv节点所在的cpu使用率都超过百分之80,但有一个tikv节点,全程cpu几乎没使用过,感觉负载严重不均衡。我的tikv节点是所在的是4核,部署在k8s上。
单独看下tikv-2,几乎全程在划水
panqiao
(Ti D Ber Qb358ha7)
2
看了下对应的tikv日志,并没有错误日志,都是info
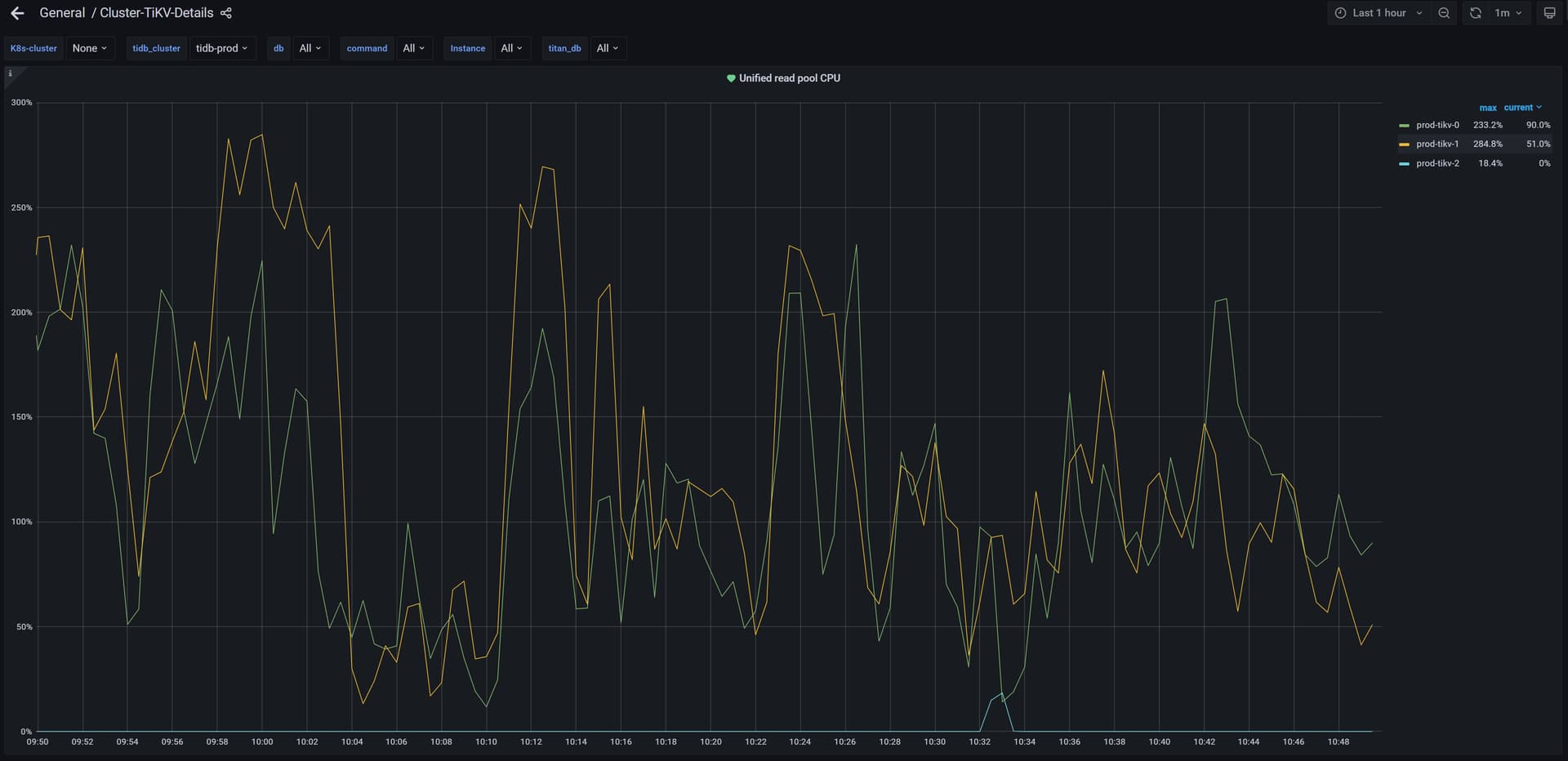
使用TiDB的监控工具(如Grafana)和诊断日志来检查TiKV节点的负载情况、数据分布和GC状态。
舞动梦灵
(Ti D Ber Nckmz Hmh)
7
你打开 tidb dashboard 集群信息 主机 看看这个图,看看他的平均cpu使用率和使用的内存 ,如果一个特别高,一个特别低,基本上leader和follower。如果999耗时很低,可以不用处理
看下你的热点的表分布在,那个节点上。通过TIDB dashboard分析下sql.
panqiao
(Ti D Ber Qb358ha7)
14
热力图的监控在哪块儿呀,监控太多了,我实在是没找到
WalterWj
(王军 - PingCAP)
16
对应节点没 leader,检查下 pd-ctl 里面的调度规则,是不是加了 >> scheduler add evict-leader-scheduler 1 // 把 store 1 上的所有 Region 的 leader 从 store 1 调度出去.类似这种
1 个赞
panqiao
(Ti D Ber Qb358ha7)
17
我刚刚排查到这了,确实是有这个驱逐的规则
/ # ./pd-ctl -i -u http://127.0.0.1:2379
» scheduler show
[
“split-bucket-scheduler”,
“evict-leader-scheduler”,
“balance-hot-region-scheduler”,
“balance-leader-scheduler”,
“balance-region-scheduler”
]
» scheduler remove evict-leader-scheduler
Success!
» scheduler show
[
“balance-region-scheduler”,
“split-bucket-scheduler”,
“balance-hot-region-scheduler”,
“balance-leader-scheduler”
]
» scheduler show
[
“balance-region-scheduler”,
“split-bucket-scheduler”,
“evict-leader-scheduler”,
“balance-hot-region-scheduler”,
“balance-leader-scheduler”
]
但是我删了不到5秒钟,自己又加回来了
vincentLi
(Ti D Ber X5 H Em4hc)
19
mark,你这个是单机测试环境吧。是不是有什么label规则导致region分布有问题?
小龙虾爱大龙虾
(Minghao Ren)
20
估计得整体分析下了,正常来说驱逐 leader 调度不会随便加的,可能是 tidb operator 搞的,可以看下它的日志,另外你这个 k8s 单个 tikv 节点资源也太少了吧,建议按官方的推荐配置来,参考:https://docs.pingcap.com/zh/tidb/stable/hardware-and-software-requirements#生产环境