【 TiDB 使用环境】生产环境
【 TiDB 版本】v8.1.0
【复现路径】无
【遇到的问题:问题现象及影响】
一、现象
新搭建的集群(3 台机器,4c 32G),稳定运行四天左右。2024-06-17 9点多反馈应用查询卡顿,当时查看CPU和内存,其中两个节点内存快接近100%, 重启机器、修改tikv内存后故障消除。
二、问题
-
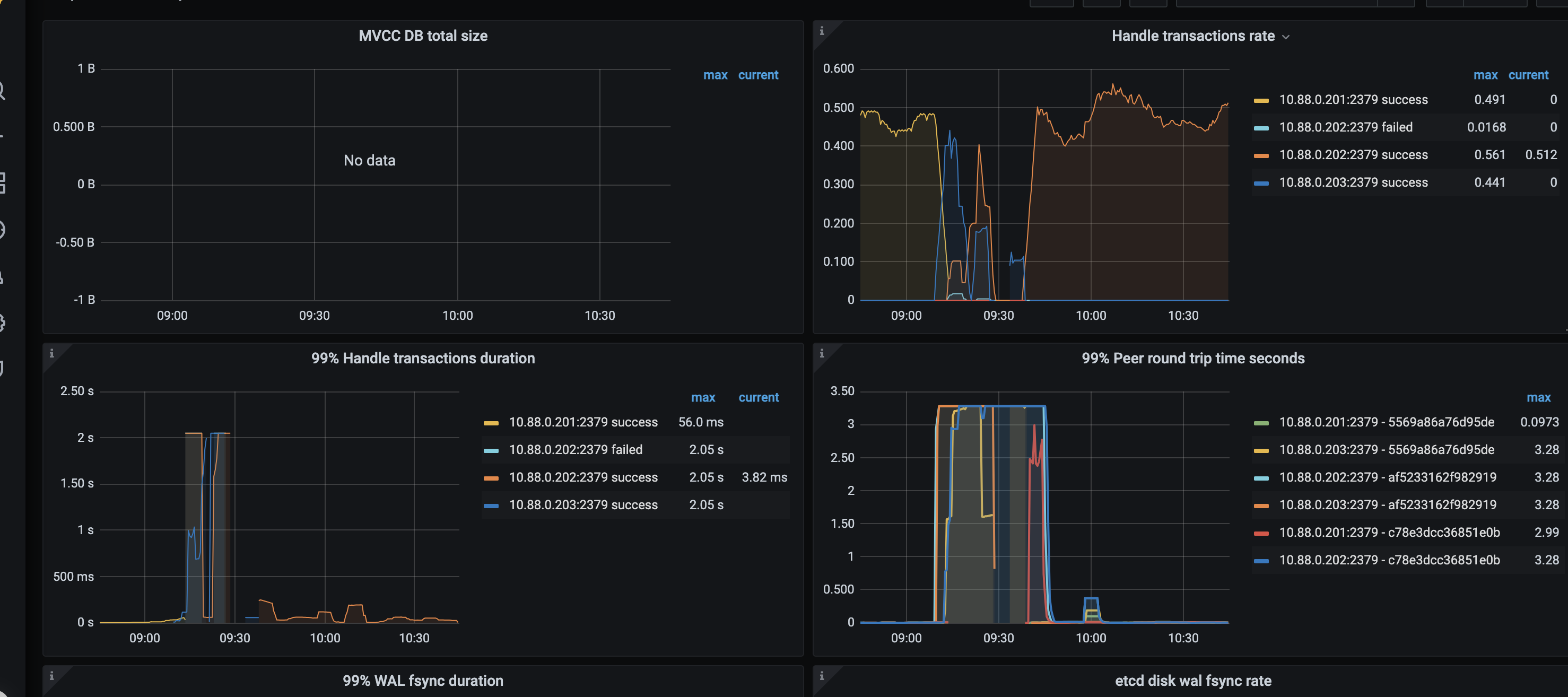
看PD日志在 9:09三台机器大量出现etcd访问错误 (看日志 2024.6.12也出现类似错误,一样的表现)
[2024/06/17 09:09:03.365 +08:00] [WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=etcd-endpoints://0xc001590000/10.88.0.202:2379] [attempt=0] [error=“rpc error: code = Unavailable desc = etcdserver: leader changed”]
[2024/06/17 09:09:03.365 +08:00] [WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=etcd-endpoints://0xc0015901e0/10.88.0.202:2379] [attempt=0] [error=“rpc error: code = Unavailable desc = etcdserver: leader changed”]
[2024/06/17 09:09:05.082 +08:00] [WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=etcd-endpoints://0xc001590780/10.88.0.201:2379] [attempt=0] [error=“rpc error: code = Unavailable desc = keepalive ping failed to receive ACK within timeout”]
[2024/06/17 09:09:05.082 +08:00] [WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=etcd-endpoints://0xc0016761e0/10.88.0.201:2379] [attempt=0] [error=“rpc error: code = Unavailable desc = keepalive ping failed to receive ACK within timeout”] -
PD监控
-
etcd监控
-
主机资源

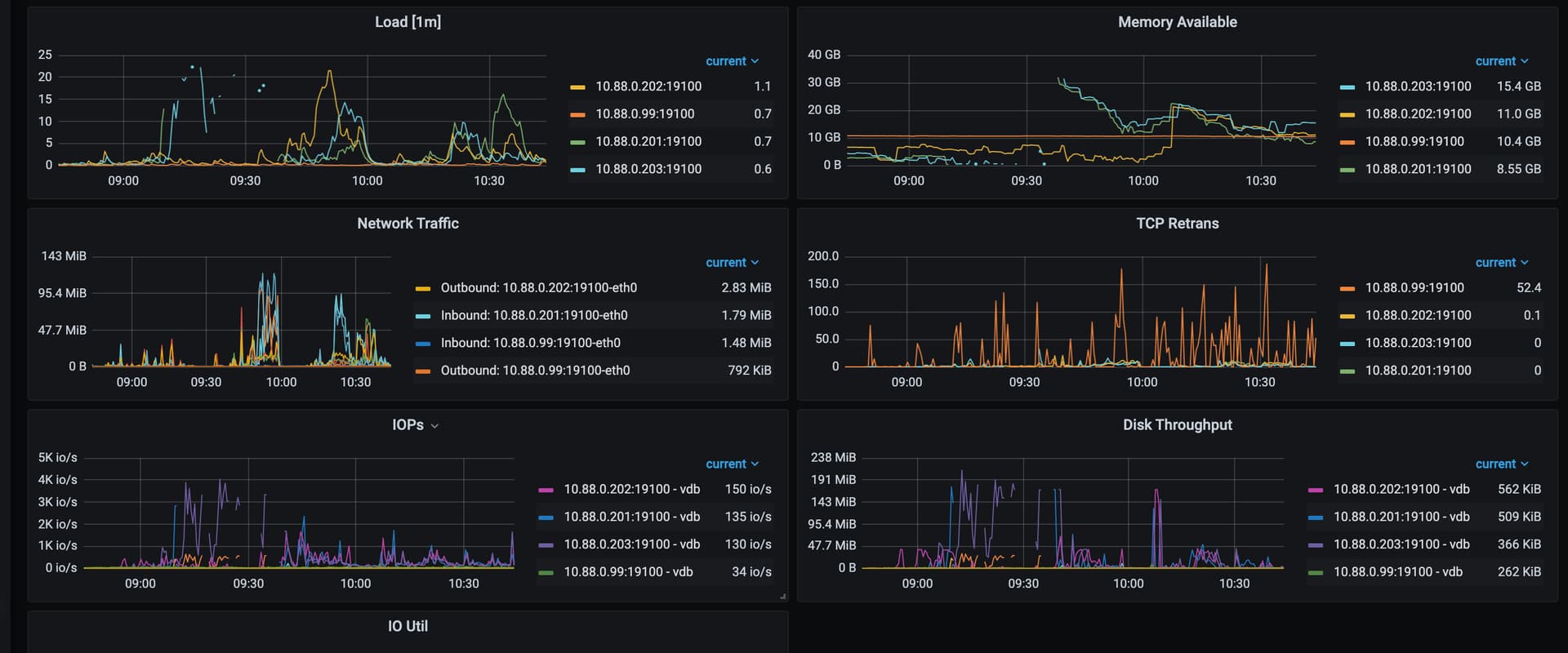
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】