【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.0.6
【 问题现象】
报错时写入kafka异常,然后修改下kafka的参数max-message-bytes 就可以恢复,再出现同样的问题时也需要修改 kafka 的max-message-bytes参数,不论改大或者改小max-message-bytes参数都可以恢复同步
【 报错信息】
[2024/06/03 20:59:52.366 +08:00] [WARN] [json.go:404] [“Single message too large”] [max-message-size=10485880] [length=10560460] [table=db_name.table_name]
[2024/06/03 20:59:52.443 +08:00] [ERROR] [processor.go:305] [“error on running processor”] [capture=xx.xx.xx.xx:8300] [changefeed=task-xxx-xxx-kafka-v2] [error=“[CDC:ErrJSONCodecRowTooLarge]json codec single row too large”] [errorVerbose=“[CDC:ErrJSONCodecRowTooLarge]json codec single row too large\ngithub.com/pingcap/errors.AddStack\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/errors.go:174\ngithub.com/pingcap/errors.(*Error).GenWithStackByArgs\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/normalize.go:156\ngithub.com/pingcap/tiflow/cdc/sink/codec.(*JSONEventBatchEncoder).AppendRowChangedEvent\n\tgithub.com/pingcap/tiflow@/cdc/sink/codec/json.go:406\ngithub.com/pingcap/tiflow/cdc/sink.(*mqSink).runWorker\n\tgithub.com/pingcap/tiflow@/cdc/sink/mq.go:353\ngithub.com/pingcap/tiflow/cdc/sink.(*mqSink).run.func1\n\tgithub.com/pingcap/tiflow@/cdc/sink/mq.go:282\ngolang.org/x/sync/errgroup.(*Group).Go.func1\n\tgolang.org/x/sync@v0.0.0-20201020160332-67f06af15bc9/errgroup/errgroup.go:57\nruntime.goexit\n\truntime/asm_amd64.s:1357”]
[2024/06/03 20:59:52.443 +08:00] [ERROR] [processor.go:144] [“run processor failed”] [changefeed=task-xxx-xxx-kafka-v2] [capture=xx.xx.xx.xx:8300] [error=“[CDC:ErrJSONCodecRowTooLarge]json codec single row too large”] [errorVerbose=“[CDC:ErrJSONCodecRowTooLarge]json codec single row too large\ngithub.com/pingcap/errors.AddStack\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/errors.go:174\ngithub.com/pingcap/errors.(*Error).GenWithStackByArgs\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/normalize.go:156\ngithub.com/pingcap/tiflow/cdc/sink/codec.(*JSONEventBatchEncoder).AppendRowChangedEvent\n\tgithub.com/pingcap/tiflow@/cdc/sink/codec/json.go:406\ngithub.com/pingcap/tiflow/cdc/sink.(*mqSink).runWorker\n\tgithub.com/pingcap/tiflow@/cdc/sink/mq.go:353\ngithub.com/pingcap/tiflow/cdc/sink.(*mqSink).run.func1\n\tgithub.com/pingcap/tiflow@/cdc/sink/mq.go:282\ngolang.org/x/sync/errgroup.(*Group).Go.func1\n\tgolang.org/x/sync@v0.0.0-20201020160332-67f06af15bc9/errgroup/errgroup.go:57\nruntime.goexit\n\truntime/asm_amd64.s:1357”]
表的行宽有超过限制吗?
表定义有两个 longtext和三个 text 字段
该问题的核心就是,用户没有配置 max-message-bytes 参数,老版本上默认为 10mb,你这里同步的消息大小,超过了该值,自然就报错了。
符合预期。
https://docs.pingcap.com/zh/tidb/stable/ticdc-sink-to-kafka#最佳实践
你的问题是什么呢?
max-message-bytes 这个参数 kafka 配置了,用户推送 kafka 也配置了,用户配置的跟 kafka 配置的都是一样的
Ticdc 推送 kafka 报错 [CDC:ErrJSONCodecRowTooLarge]json codec single row too large
这个报错是指 TiCDC 在将变更数据写入 Kafka 时,发现单行数据的 JSON 编码过大,导致无法正常写入。通常情况下,这可能是由于单行数据中包含了过多的字段或者字段值太大,超出了 Kafka 的消息大小限制所导致的。
针对这个问题,你可以考虑以下几点解决方法:
1. 检查表结构设计
检查相关表的设计,尤其是 VARCHAR、TEXT 或 BLOB 类型的字段是否包含过大的数据。如果是,可以考虑优化数据存储方式,例如将大数据拆分存储在其他地方,并在主表中保留引用或者摘要等信息。
2. 缩减字段
如果单行数据中包含了过多的字段,可以考虑是否所有字段都需要被同步到 Kafka 中。可以根据实际需求选择性同步必要的字段,减少单行数据的大小。
3. 使用 Avro 格式
考虑使用 Avro 格式代替 JSON 格式进行数据编码。Avro 格式通常比 JSON 更紴紧,可以减少数据传输时的大小。
4. 调整 CDC 配置
在 TiCDC 的配置中,可以调整 sink 对应的 JSON 编码参数,例如 max-message-bytes 参数,适当增大单条消息的大小限制。
5. 增加分区
如果单行数据较大,可以考虑增大 Kafka Topic 的分区数,以便更细粒度地划分数据,从而降低单个分区的压力。
6. 分批处理
在 TiCDC 中可以设置合适的数据分批策略,将大数据按照一定规则分批处理,避免单行数据过大导致的问题。
7. 监控数据变化
定期监控表数据的变化情况,特别是字段值的大小变化,及时发现并处理潜在问题。
感觉像是kafka配置有问题。能贴一下你修改的配置吗
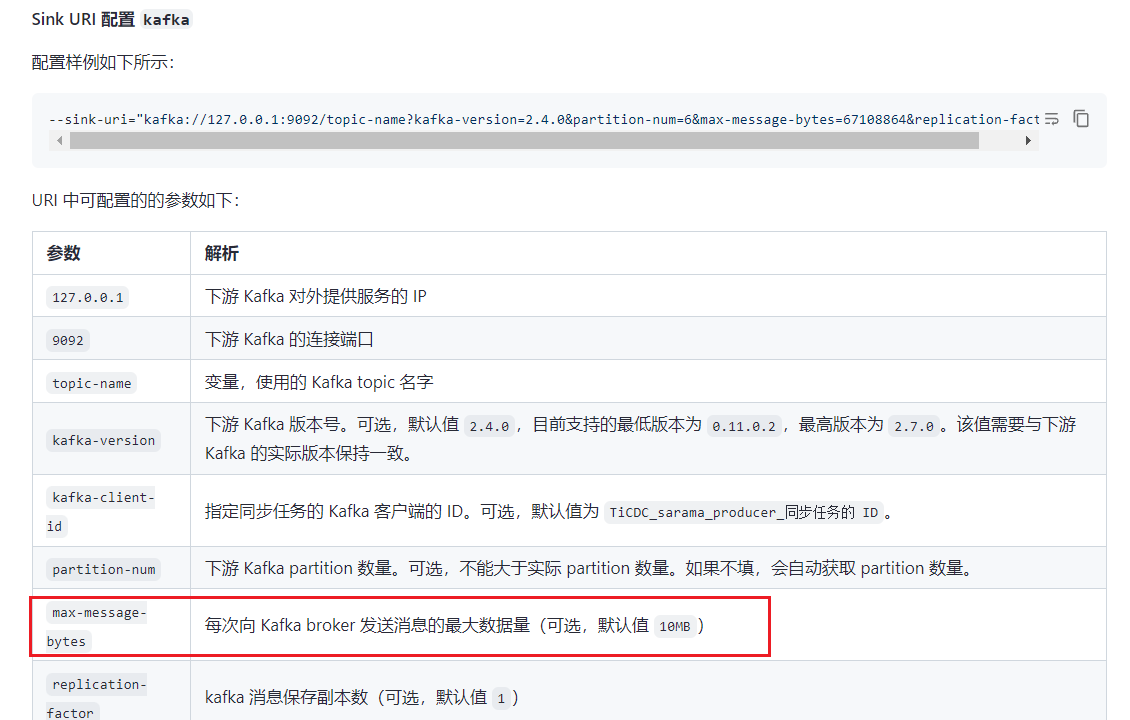
学习了,max-message-bytes参数配置