panqiao
(Ti D Ber Qb358ha7)
1
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
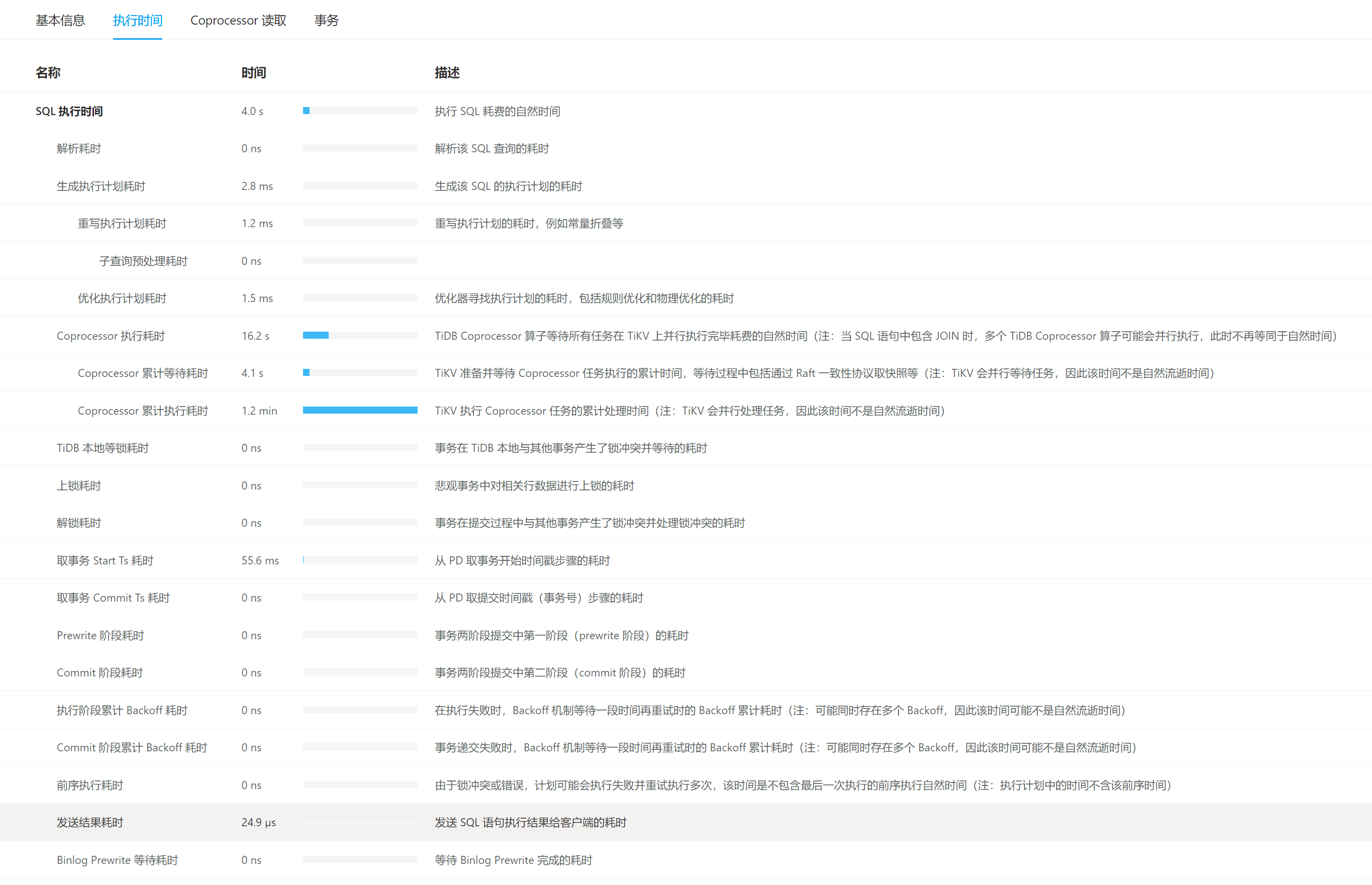
【遇到的问题:问题现象及影响】生产环境中,透过Tidb Dashboard 可以看到很多慢查询,其中很多都是Coprocessor 执行耗时 很长,并且一旦有Coprocessor 执行耗时 很长的sql出现时,tikv节点对应的CPU就会被拉的很高,这个要怎么优化?为什么Coprocessor 执行耗时 很长?
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
几乎每条慢sql的这个步骤都很长时间,该怎么优化?
以前也遇到过,网上找到的 这个:
TiDB中Coprocessor执行耗时很长可能由多种因素导致。以下是一些可能的原因和相应的分析,以及如何解决或优化的建议:
1. 索引问题
- 问题描述:查询语句没有有效利用索引,导致Coprocessor需要扫描大量数据。
- 解决方案:
- 检查查询语句,确保它使用了适当的索引。
- 对于经常查询的列,考虑添加索引。
- 使用
EXPLAIN语句分析查询计划,查看索引是否被正确使用。
2. 数据量问题
- 问题描述:查询的数据量过大,导致Coprocessor需要处理更多数据。
- 解决方案:
- 优化查询语句,减少不必要的数据扫描。
- 考虑使用分页查询,减少单次查询的数据量。
- 如果可能,将数据分区或分片,以提高查询性能。
3. Coprocessor 并发度设置
- 问题描述:Coprocessor的并发度设置不当,可能导致某些查询等待时间过长。
- 解决方案:
- 调整TiDB的配置参数,如
tidb_distsql_scan_concurrency和tidb_index_lookup_concurrency,以优化查询性能。
- 根据系统负载和硬件资源,合理配置并发度。
4. 系统资源瓶颈
- 问题描述:CPU、内存或磁盘I/O等资源不足,导致Coprocessor执行缓慢。
- 解决方案:
- 监控系统资源使用情况,确保TiDB有足够的资源运行。
- 升级硬件资源,如增加CPU核心数、扩大内存容量或使用高性能的磁盘。
- 使用SSD等高性能存储设备,提高磁盘I/O性能。
5. 查询优化
- 问题描述:查询语句本身存在问题,如使用了复杂的子查询、JOIN操作等。
- 解决方案:
- 简化查询语句,避免使用复杂的子查询和JOIN操作。
- 使用
EXPLAIN ANALYZE语句分析查询性能,找出性能瓶颈并进行优化。
- 考虑使用TiDB的SQL优化器或其他工具来优化查询语句。
6. 版本和配置问题
- 问题描述:TiDB版本过旧或配置不当可能导致性能问题。
- 解决方案:
- 升级到最新版本的TiDB,以获得更好的性能和稳定性。
- 检查TiDB的配置文件(如
tidb.toml和tikv.toml),确保配置正确并符合硬件资源的实际情况。
7. 集群状态
- 问题描述:TiDB集群的状态可能影响到Coprocessor的执行性能。
- 解决方案:
- 定期检查TiDB集群的状态,确保所有节点都处于正常状态。
- 使用TiDB的监控工具(如Grafana)来监控集群的性能指标,如CPU使用率、内存占用、磁盘I/O等。
- 根据监控结果进行相应的优化和调整。
总结
Coprocessor执行耗时很长可能由多种因素导致,包括索引问题、数据量问题、并发度设置、系统资源瓶颈、查询优化、版本和配置问题以及集群状态等。为了解决这个问题,需要根据实际情况进行逐一排查和优化。
有猫万事足
3
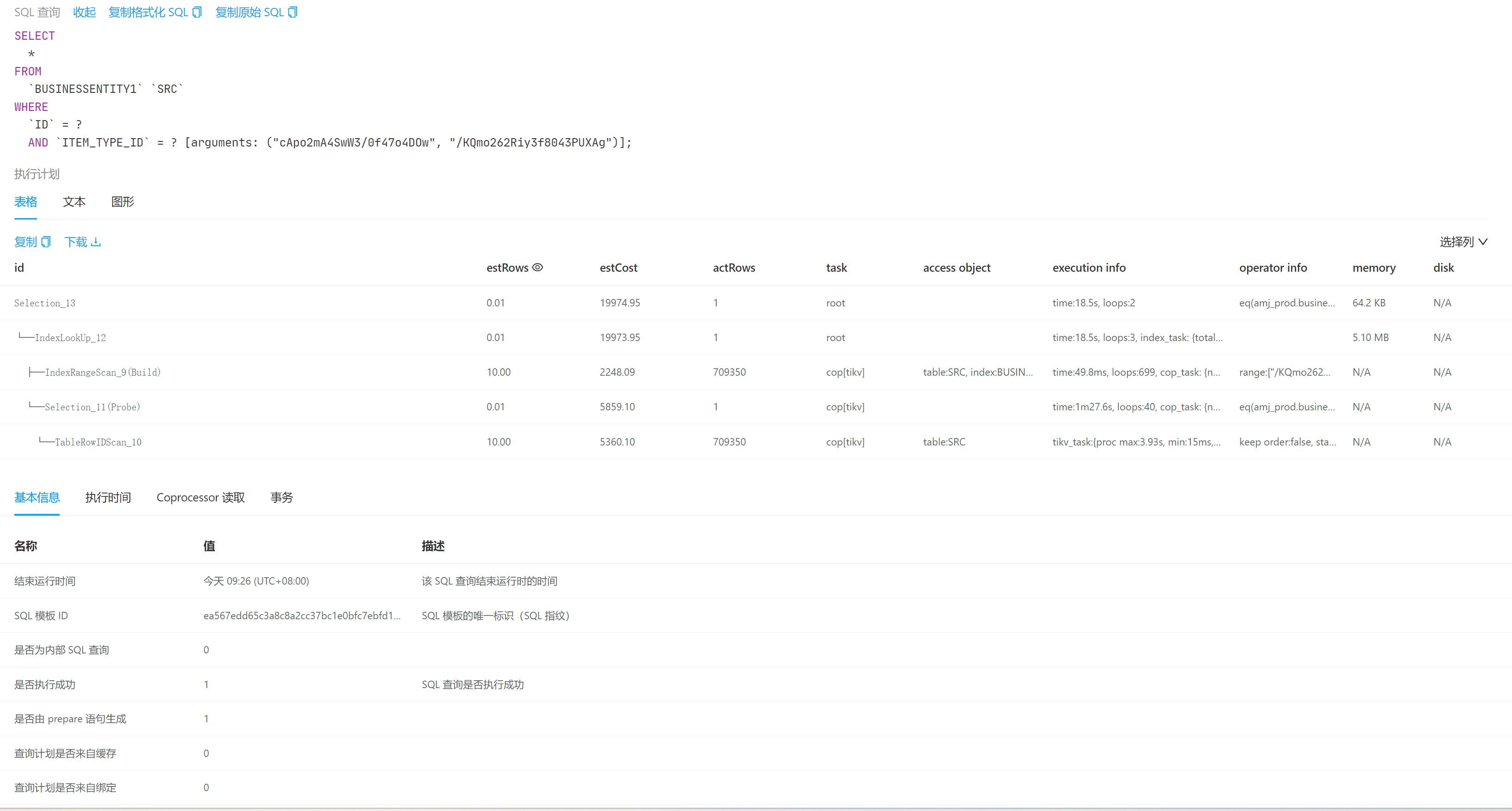
最好给出执行计划。不能只能靠猜。
从经验的角度说,这一般是没走索引。导致全表扫描。
panqiao
(Ti D Ber Qb358ha7)
5
下面我发了更详细的信息,能帮忙分析下具体大概是什么原因嘛
explain analyze sql看一下实际的执行计划,看看慢在哪
panqiao
(Ti D Ber Qb358ha7)
11
和上面的好像信息是一样的,不过这会而这条sql没有这么夸张了,但还是要5s
lemonade010
(Ti D Ber Sd Dr Zqk O)
12
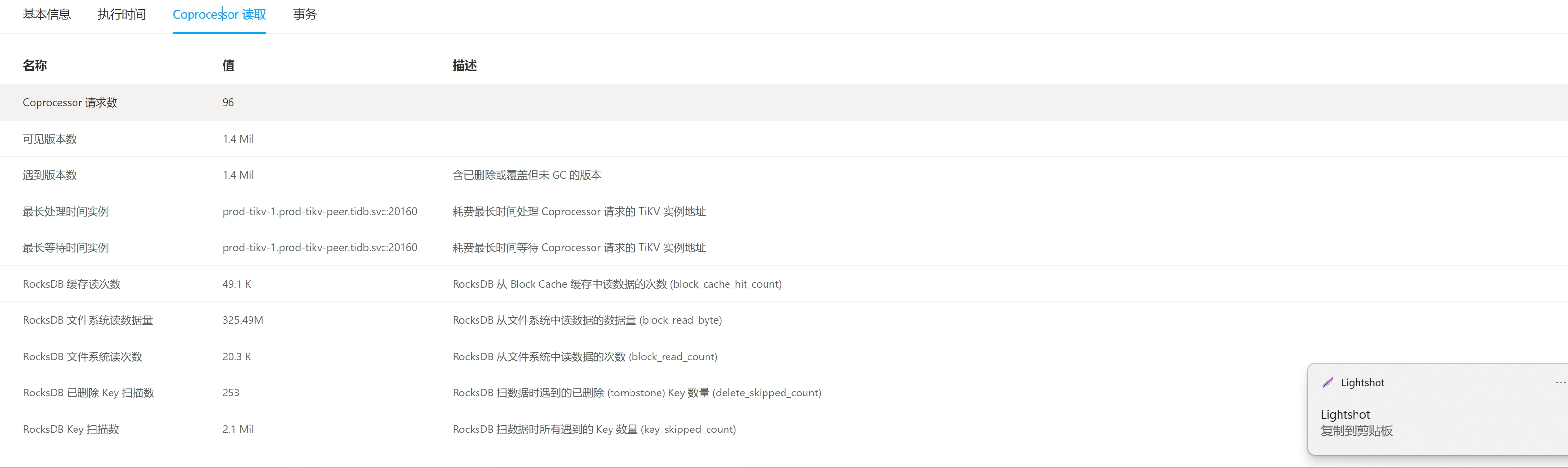
Coprocessor自行时间长,是扫描tikv,而且索引还走了item_type_id,建个ID和item_type_id,会好很多
lemonade010
(Ti D Ber Sd Dr Zqk O)
13
你的统计信息是不是没有正常收集啊,怎么差异那么大啊,也做个统计分析吧,
panqiao
(Ti D Ber Qb358ha7)
14
大佬从哪看出我的统计信息差异大的呀?而且统计信息按道理来说不应该是tidb定时自动收集吗?收集信息是使用analyze 表 吗?如果是这样的话,我们系统有13000个表啊
h5n1
(H5n1)
15
看上去选择的索引效率不高啊,表结构看下,整个组合索引
你的统计信息肯定不准,
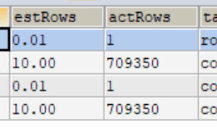
预估10行,实际70万,肯定快不了。。。