【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.0
我们有2个生产环境,每个环境的TiDB 的拓扑是一样的,资源规格也是一样的(都是通过operatopr 部署在K8S 中的);数据量、查询的QPS 等也差不多。但是其中一个环境BR 备份只要 37分钟,而另一个环境却要6小时,
请问有什么排查思路呢?
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.0
我们有2个生产环境,每个环境的TiDB 的拓扑是一样的,资源规格也是一样的(都是通过operatopr 部署在K8S 中的);数据量、查询的QPS 等也差不多。但是其中一个环境BR 备份只要 37分钟,而另一个环境却要6小时,
请问有什么排查思路呢?
备份的数据量,网络情况是否一样
数据量在一个量级,备份慢(6小时)的这个集群备份到对象存储后有35GB, 备份快的这个集群(37分钟)备份到对象存储后有24.5GB。
网络状况都是一样的,快的这个集群是阿里云,备份到OSS;慢的集群是在AWS 上,备份到S3。我觉得不会存在网络瓶颈。
而且,备份慢的这个集群,也是最近半个月才开始变慢的。
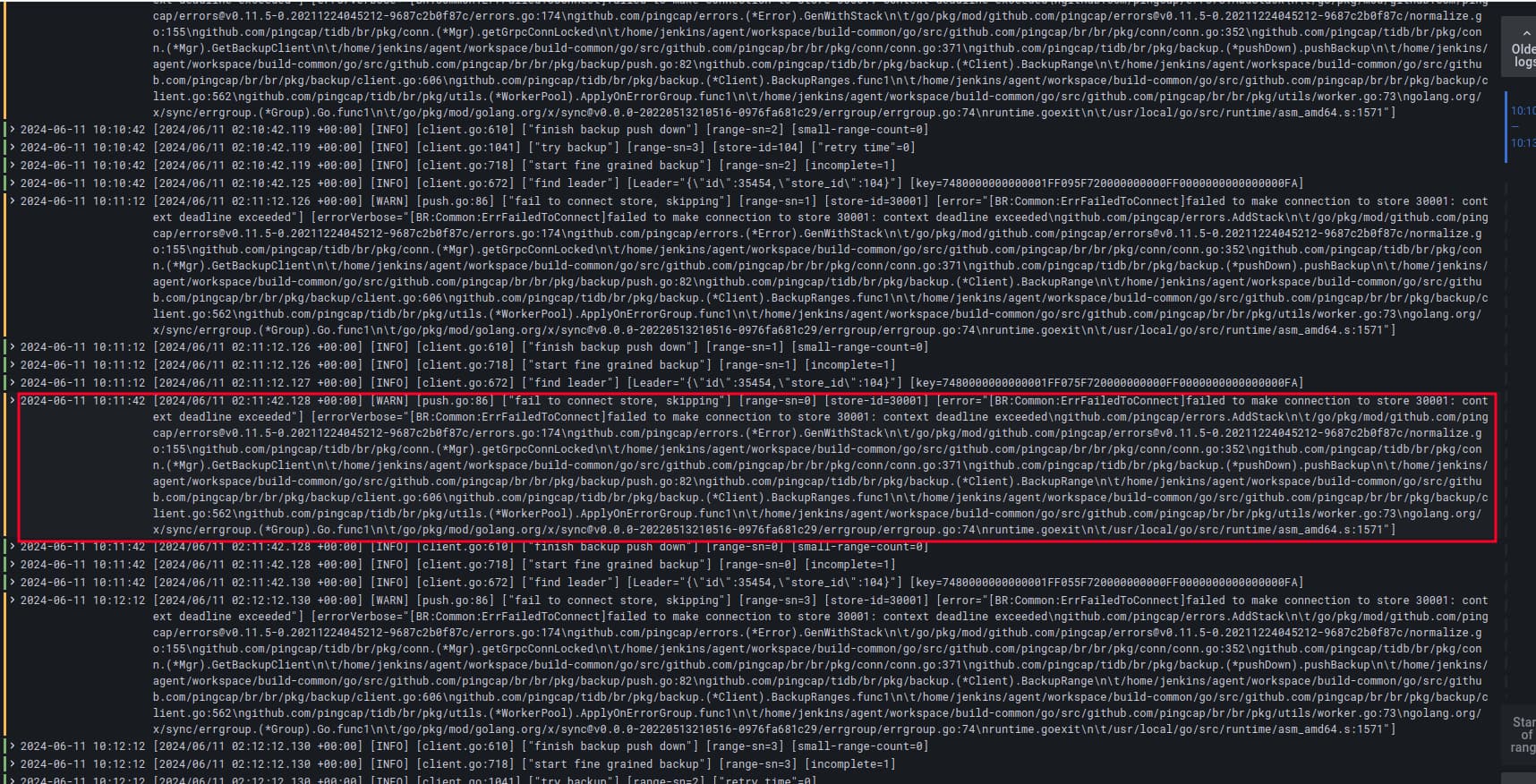
我们在AWS 的集群,TiKV 设置的是2个实例,但是世纪上由于一些异常,导致tikv 有4个示例,其中有一个实例是挂掉的,导致br 在备份时有一些 warn 级别的告警,不知道是不是这个原因导致的
目前tikv 的store 分布如下:
tikv:
bootStrapped: true
failoverUID: 186982df-36ba-4391-b21b-40bba57a2222
failureStores:
"104":
createdAt: "2023-11-29T14:39:14Z"
podName: basicai-tikv-2
storeID: "104"
image: pingcap/tikv:v6.1.0
phase: Scale
statefulSet:
collisionCount: 0
currentReplicas: 3
currentRevision: basicai-tikv-654cf466dd
observedGeneration: 8
readyReplicas: 3
replicas: 3
updateRevision: basicai-tikv-654cf466dd
updatedReplicas: 3
stores:
"1":
id: "1"
ip: basicai-tikv-0.basicai-tikv-peer.tidb-cluster.svc
lastTransitionTime: "2024-06-05T13:56:51Z"
leaderCount: 1030
podName: basicai-tikv-0
state: Up
"6":
id: "6"
ip: basicai-tikv-1.basicai-tikv-peer.tidb-cluster.svc
lastTransitionTime: "2024-06-05T13:55:12Z"
leaderCount: 1030
podName: basicai-tikv-1
state: Up
"104":
id: "104"
ip: basicai-tikv-2.basicai-tikv-peer.tidb-cluster.svc
lastTransitionTime: "2024-06-07T15:38:32Z"
leaderCount: 1037
podName: basicai-tikv-2
state: Up
"30001":
id: "30001"
ip: basicai-tikv-3.basicai-tikv-peer.tidb-cluster.svc
lastTransitionTime: "2023-12-04T13:44:47Z"
leaderCount: 0 <----------- basicai-tikv-3 这个POD 本身不存在,但是却有 3001 这个store
podName: basicai-tikv-3
state: Down
用的什么盘?
OSS就考试网络问题。
网络没问题吗
优秀。
优秀,自问自
学习下
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。