【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.0
【复现路径】 设置开启自动analyze相关参数后,发现并没有触发自动优化。
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.0
【复现路径】 设置开启自动analyze相关参数后,发现并没有触发自动优化。
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
来看这儿的介绍:https://docs.pingcap.com/zh/tidb/stable/sql-faq#在-tidb-中-auto-analyze-的触发策略是怎样的
另外还有补充推荐你阅览的文章:
写得相当不错的,期待你能获得想要的答案!
好的,我先看看您推荐的这两个文档。最近,这个问题比较困扰我。
是有触发条件的。没触发。挺好。说明你目前可以天天安稳睡觉! ![]()
还得等满足触发条件
当一张表或分区表的单个分区达到 1000 条记录,且表或分区的(修改数/当前总行数)比例大于 tidb_auto_analyze_ratio 的时候,会自动触发 ANALYZE 语句。
tidb_auto_analyze_ratio 的默认值为 0.5,即默认开启触发 auto analyze。注意该变量值不建议大于等于 pseudo-estimate-ratio(默认值为 0.8),否则优化器可能会使用 pseudo 统计信息。TiDB 从 v5.3.0 开始引入 tidb_enable_pseudo_for_outdated_stats 变量,当设置为 OFF 时,即使统计信息过期也不会使用 pseudo 统计信息。
但是,我通过查看健康度,低于50的有好多表,说明健康度越低,对应的表数据变更的越高。理论上,当表中超过 50% 的行被修改时,触发自动 ANALYZE 更新。
### `tidb_auto_analyze_ratio`
* 作用域:GLOBAL
* 是否持久化到集群:是
* 默认值:`0.5`
* 这个变量用来设置 TiDB 在后台自动执行 [`ANALYZE TABLE`](https://docs.pingcap.com/zh/tidb/v6.5/sql-statement-analyze-table) 更新统计信息的阈值。`0.5` 指的是当表中超过 50% 的行被修改时,触发自动 ANALYZE 更新。可以指定 `tidb_auto_analyze_start_time` 和 `tidb_auto_analyze_end_time` 来限制自动 ANALYZE 的时间
在测试环境库,找了一张表,表数据量有1.24w+,对表进行克隆创建,并将数据插入到新表中。然后,对新表进行全表数据的更新操作。经过观察,并没有触发自动analyze对表的收集操作。
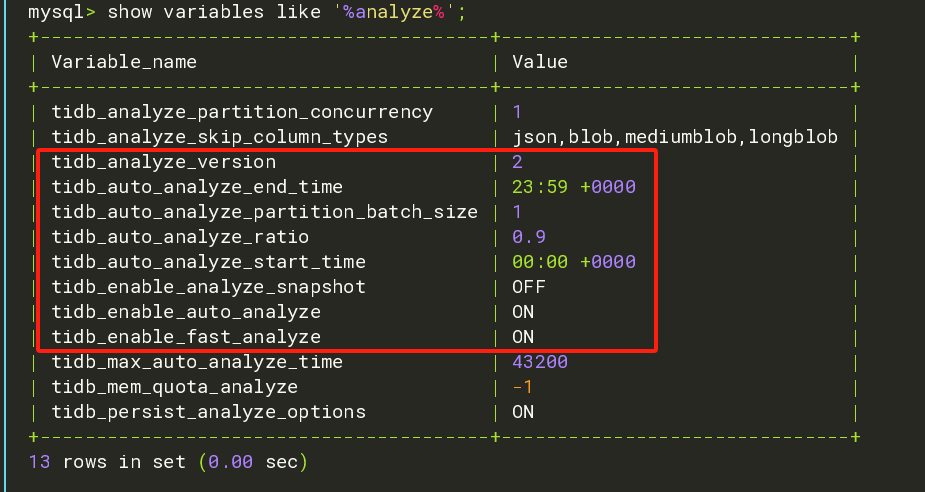
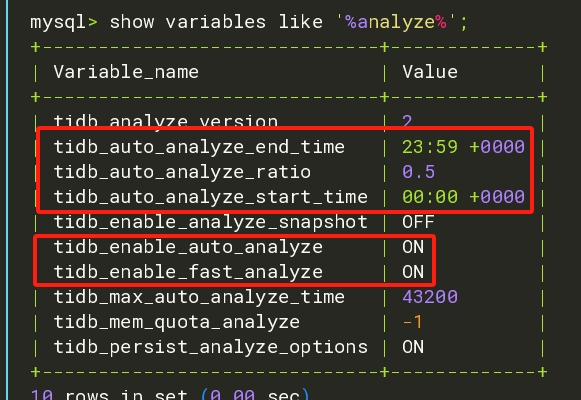
MySQL [maindb]> show variables like '%analyze%';
+------------------------------+-------------+
| Variable_name | Value |
+------------------------------+-------------+
| tidb_analyze_version | 2 |
| tidb_auto_analyze_end_time | 23:59 +0000 |
| tidb_auto_analyze_ratio | 0.5 |
| tidb_auto_analyze_start_time | 00:00 +0000 |
| tidb_enable_analyze_snapshot | OFF |
| tidb_enable_auto_analyze | ON |
| tidb_enable_fast_analyze | ON |
| tidb_max_auto_analyze_time | 43200 |
| tidb_mem_quota_analyze | -1 |
| tidb_persist_analyze_options | ON |
+------------------------------+-------------+
10 rows in set (0.00 sec)
MySQL > create table xxl_job_log_20240611_bk like xxl_job_log;
Query OK, 0 rows affected (0.51 sec)
MySQL > insert into xxl_job_log_20240611_bk select * from xxl_job_log;
Query OK, 12645 rows affected (0.54 sec)
Records: 12645 Duplicates: 0 Warnings: 0
MySQL > select count(*) from xxl_job_log_20240611_bk;
+----------+
| count(*) |
+----------+
| 12645 |
+----------+
1 row in set (0.01 sec)
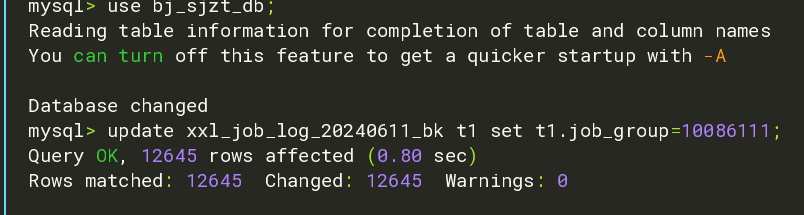
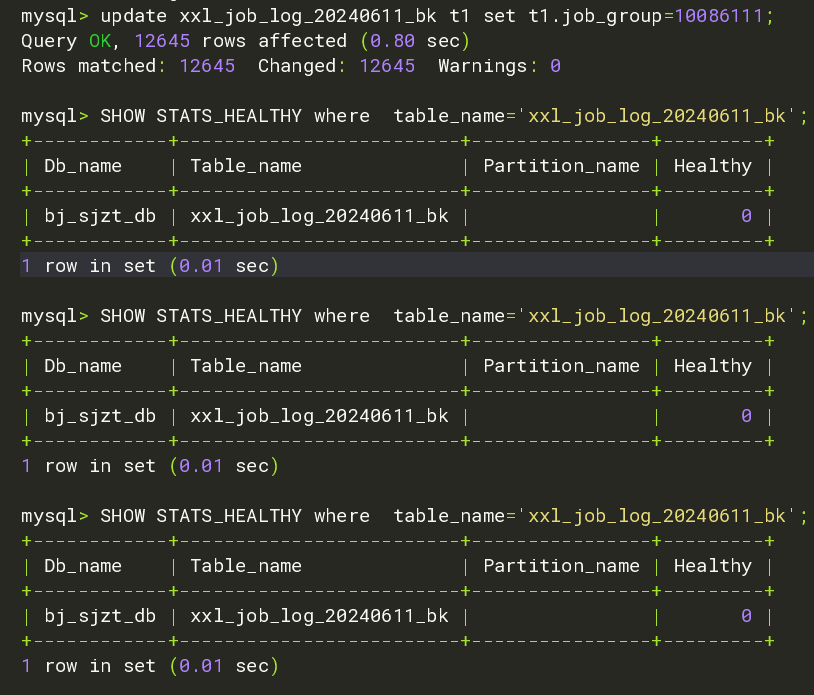
MySQL > update xxl_job_log_20240611_bk t1 set t1.job_group=10086;
Query OK, 12645 rows affected (0.22 sec)
Rows matched: 12645 Changed: 12645 Warnings: 0
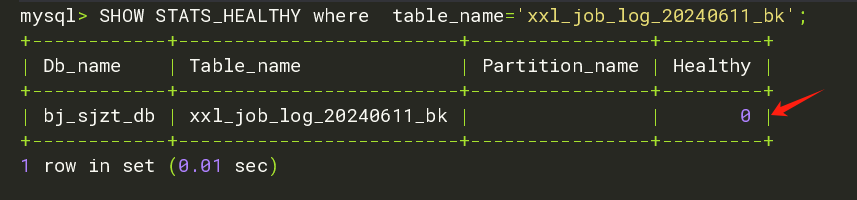
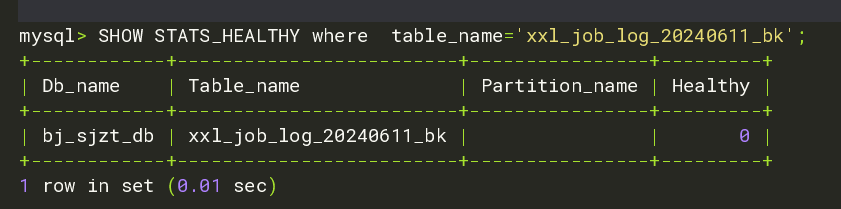
MySQL [maindb]> SHOW STATS_HEALTHY where table_name='xxl_job_log_20240611_bk';
+---------+-------------------------+----------------+---------+
| Db_name | Table_name | Partition_name | Healthy |
+---------+-------------------------+----------------+---------+
| test | xxl_job_log_20240611_bk | | 63 |
+---------+-------------------------+----------------+---------+
1 row in set (0.00 sec)
| tidb_auto_analyze_ratio | 0.5
+---------+-------------------------+----------------+---------+
| Db_name | Table_name | Partition_name | Healthy |
+---------+-------------------------+----------------+---------+
| test | xxl_job_log_20240611_bk | | 63 |
+---------+-------------------------+----------------+---------+
0.5 < 0.63 …
SHOW STATS_HEALTHY 语句可以预估统计信息的准确度,也就是健康度。健康度低的表可能会生成次优查询执行计划。
当表的健康度下降到低于 tidb_auto_analyze_ratio 时,则会自动执行 ANALYZE 语句。
参考这儿:
https://docs.pingcap.com/zh/tidb/stable/sql-statement-show-stats-healthy#show-stats_healthy
1、 在 TiDB 中 auto analyze 的触发策略是怎样的?
参考链接:https://docs.pingcap.com/zh/tidb/stable/sql-faq#在-tidb-中-auto-analyze-的触发策略是怎样的
2、 当表的健康度下降到低于 tidb_auto_analyze_ratio 时,则会自动执行 ANALYZE 语句。
参考链接:
https://docs.pingcap.com/zh/tidb/stable/sql-statement-show-stats-healthy#show-stats_healthy
怎么感觉这两个文档的说明,有点相互矛盾呢?我又重新调整测试了下,还是不能触发自动analyze收集。
1、当前自动分析的相关参数如下:
2、表当前的健康度:
3、批量全表更新数据:
4、再次查看表的健康度:
此时,健康度为0,远小于 tidb_auto_analyze_ratio=0.9,但是,并没有触发自动收集。
自动收集开始时间、结束时间 设置成 时间+0800 试试呢
手工analyze table 能提升健康度么?
另外应该不至于是这个version导致的吧?
确实,看下是否是收集统计信息的任务失败了
mysql> show analyze status where table_name ='xxl_job_log_20240611_bk';
+--------------+-------------------------+----------------+-------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------+---------------+------------+-------------------+----------+----------------------+
| Table_schema | Table_name | Partition_name | Job_info | Processed_rows | Start_time | End_time | State | Fail_reason | Instance | Process_ID | Remaining_seconds | Progress | Estimated_total_rows |
+--------------+-------------------------+----------------+-------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------+---------------+------------+-------------------+----------+----------------------+
| bj_sjzt_db | xxl_job_log_20240611_bk | | auto analyze table all columns with 256 buckets, 500 topn, 1 samplerate | 12645 | 2024-06-11 17:12:46 | 2024-06-11 17:12:53 | finished | NULL | 10.3.9.9:4000 | NULL | NULL | NULL | NULL |
+--------------+-------------------------+----------------+-------------------------------------------------------------------------+----------------+---------------------+---------------------+----------+-------------+---------------+------------+-------------------+----------+----------------------+
1 row in set (0.02 sec)
通过查看analyze状态,发现触发了自动收集。时间上,并不是在手动更新后,立马就触发自动收集。
问题解决了吗?这个问题是比较复杂的。
算是解决了,触发精准度时间会有延迟,不过,不影响自动收集就行。目前,我们配置的是每天的凌晨0点到8点,进行自动收集。