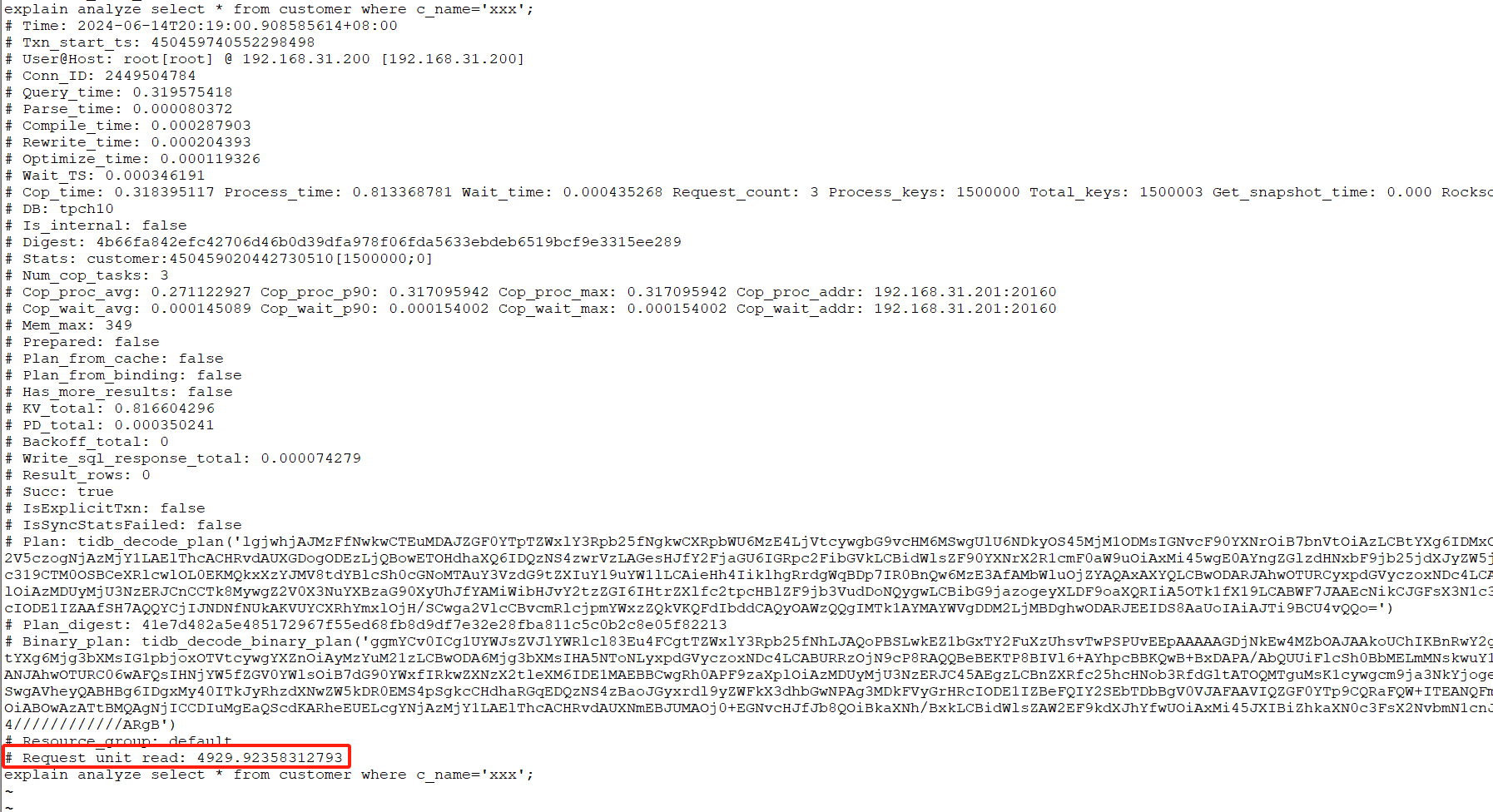
从文档来看 Runaway Queries只支持对当前查询执行时间(EXEC_ELAPSED)超限制的识别,但是在故障场景下如果存在多个并发慢语句,对应的ACTION可能会出现的问题:
1、设置为COOLDOWN,可能会打爆应用连接池,一般在故障场景不会采用,只有仅仅1-2条占用资源非常多的批次语句跑到业务时段时为避免业务正常运行,此方案较为有用。
2、设置为KILL,这是在日常业务时段出现大量并发“慢语句”的最优处理手段。
当选择了action=kill后,假设watch的匹配方式选择:
- EXACT:
只有超过EXEC_ELAPSED时间的语句才会被杀掉。
优点:非绑定变量的SQL业务时段的TP查询语句大多不会被杀掉(即使个别语句执行耗时延迟很大,被杀掉也不影响整体)。
缺点:绑定变量的SQL可能会被统一杀掉,且对于非绑定变量的SQL只有超过EXEC_ELAPSED才会杀掉,因此假设前端应用不断发交易,还是会导致数据库耗时非常高。因此此设置在故障处理场景几乎不会采用。
- SIMILAR:
当被RUNAWAY_WATCHES抓到后,具有相同SQL指纹的在指定时间段内均被阻断执行。
优点:对于耗时高的语句很容易被标记出来,并且后续的相似SQL会直接阻止运行不占用数据库资源,大大降低数据库的资源占用。
缺点:1、非常容易被RUNAWAY_WATCHES抓到正常的TP语句,常见于几个大查询吃掉了unified readpool,正常的TP语句虽然只是索引回表查询几条记录,但是也可能因为total_suspend_time等待时间太长导致被标记为 超出预期的查询,这样会导致日常的TP查询语句被阻断,导致更大的故障;2、如果慢语句是索引缺失造成的,通过添加索引后会恢复正常,但这里还是会根据SQL指纹一直阻断,因此不如根据PLAN指纹更好。
- PLAN:
当被RUNAWAY_WATCHES抓到后,具有相同执行计划的语句在指定时间段内均被阻断执行。
优点:类似于SIMILAR,而且当通过添加索引或者统计信息搜集等优化执行计划后,执行计划发生改变,不会被阻断执行(但如果此时系统资源依然繁忙,还是会导致因延迟较大被RUNAWAY_WATCHES抓到)。
缺点:如果不同的SQL语句具有相同的PLAN,可能会被误杀(比如下游系统全表扫描抽数被误杀),但是从测试来看不同的SQL语句即使具有相同的执行计划,其planid也是不同,应该不会触发该问题。
因此从整体上来看为避免故障情况下语句堆积,一般可能会选择action=kill且watch=SIMILAR或PLAN,但是不管watch选择哪个,在系统资源紧张的情况下,都有可能在平时耗时非常低的SQL语句也会出现抖动情况导致被抓到后一直被杀掉。
建议:
1、优化语句的可观测行,细化总体执行时间,新增如CPU时间、等待时间(网络等待、tikv的total_suspend_time等待、IO等待等),通过“真正执行时间长且耗资源”的维度如CPU时间来判断更为准确。
2、增加一些二次判断的辅助手段,如:查看近期该语句(如果watch=PLAN,则通过plan进一步再过滤)的平均执行时间情况来辅助决策是否将该语句加入RUNAWAY_WATCHES中。