【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
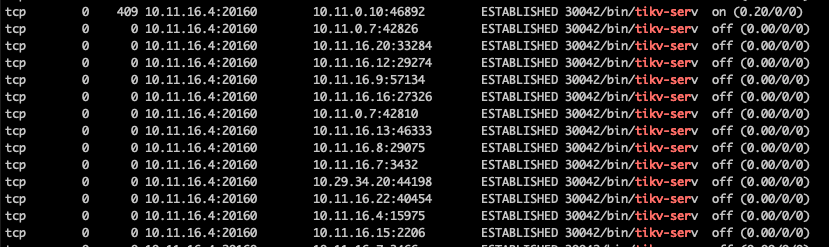
【复现路径】执行netstat -nop|grep -i “tikv-serv”
【遇到的问题:问题现象及影响】
执行netstat -nop|grep -i “tikv-serv”,返回的结果中很多ip主机已经下线,连接状态还是ESTABLISHED
系统已经设置了
net.ipv4.tcp_keepalive_time=60
net.ipv4.tcp_keepalive_intvl=5
net.ipv4.tcp_keepalive_probes=3
但是tikv没有开启tcp_keepalive的功能,无法回收连接
1、请问tikv如何开启tcp_keepalive的功能?
2、请问如何关闭或回收这种连接?(不想重启,不想对业务有影响)
确定僵尸进程的父进程是什么。在ps命令的输出中,PPID(父进程ID)列显示了每个进程的父进程ID。
分析父进程的行为。为什么它没有回收其子进程的资源?可能是因为父进程正在等待某些条件才能回收资源,或者父进程本身已经崩溃或挂起。
xfworld
(魔幻之翼)
3
什么场景会这么玩? 裸 tikv 的应用模式么? 但是 client 端会有连接回收的机制,是不是强制关闭导致的?
没有僵尸进程,是客户端的主机已经下线了,连接还是ESTABLISHED
使用场景是作为juiceFS的元数据存储,是tikv txn的模式,应该是强制关闭进程导致的
1 个赞
不是,用client-go直接连接tikv产生的链接
vincentLi
(Ti D Ber X5 H Em4hc)
8
建议去客户端(第四列)的机器,看看是什么进程连上tikv了。能连tikv的不丹是tidb server。lightning这些工具也可以连。
xfworld
(魔幻之翼)
9
client-go 有异常连接处理的范式吧,是不是漏掉了导致的
产生的连接很明确,是juicefs客户端中的client-go,关键问题是机器已经下线了,连接统计还是ESTABLISHED
xfworld
(魔幻之翼)
12
按节点实例重启咯… 最好有足够的节点来支撑副本数量…
程序的坑,从别的地方找补么? 这感觉比较困难,你也可以多尝试下… 
程序使用不合理,数据库端就不需做自我保护,理论上服务端也应该要有处理的
xfworld
(魔幻之翼)
14
开源社区嘛,目前应该没有这块的能力支持,你可以提个issue,看看是否会有迭代计划
如果有特别强烈功能支持的需求,可以考虑找原厂服务,升级服务等级,或许能有解决方案.
可以先抓包看看,按道理 grpc 也有应用层的 keepalive,不应该会残留链接。