【 TiDB 使用环境】POC
【 TiDB 版本】7.1.5
【复现路径】
date && ./blade create network delay --time 3000 --offset 500 --interface eth0 --local-port 2379
Fri Jun 7 11:35:56 CST 2024
{“code”:200,“success”:true,“result”:“81a33dbacbe665a6”}
【遇到的问题:问题现象及影响】
当对pd server的leader节点模拟网络延迟时,整个集群不可用。同时tiup命令也无法执行。
想了解一下,如果遇到PD Server Leader出现了网络延迟或者丢包,应该如何跟进。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
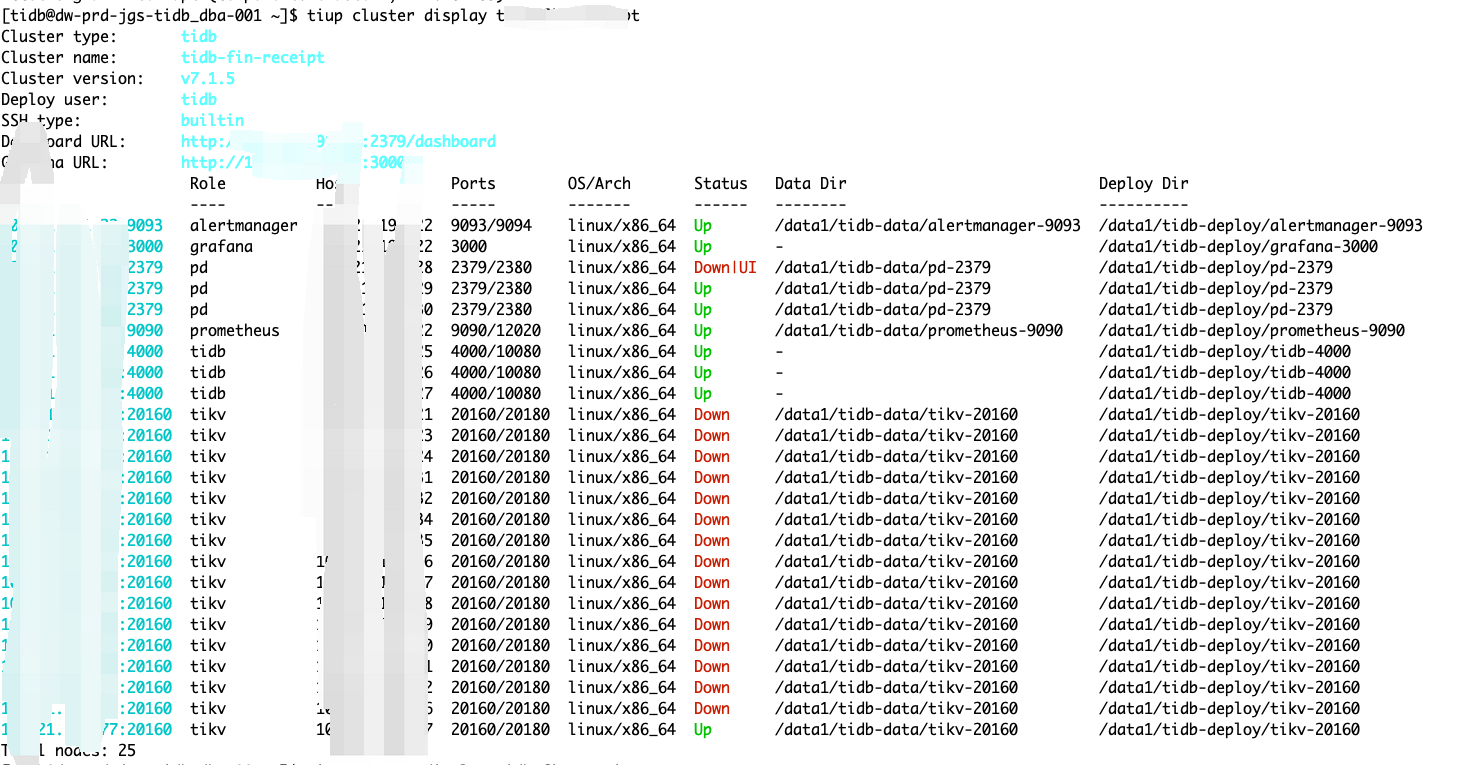
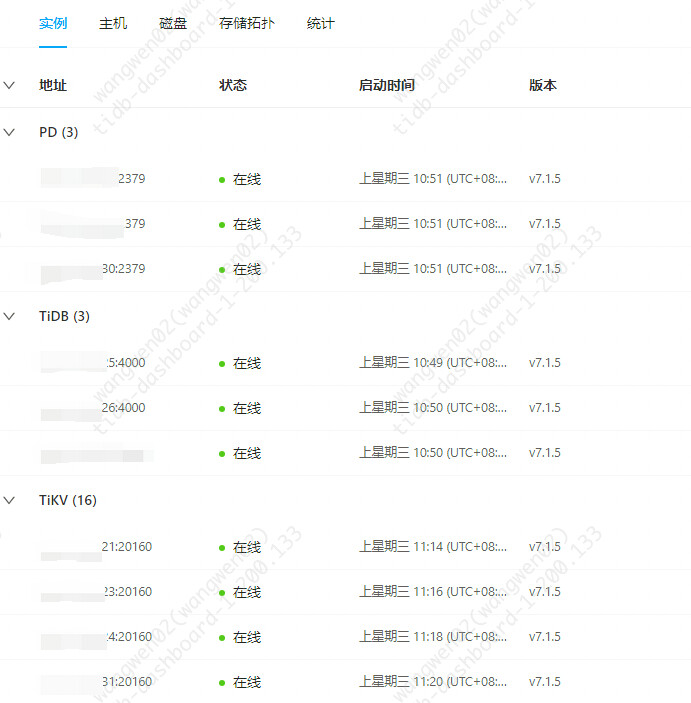
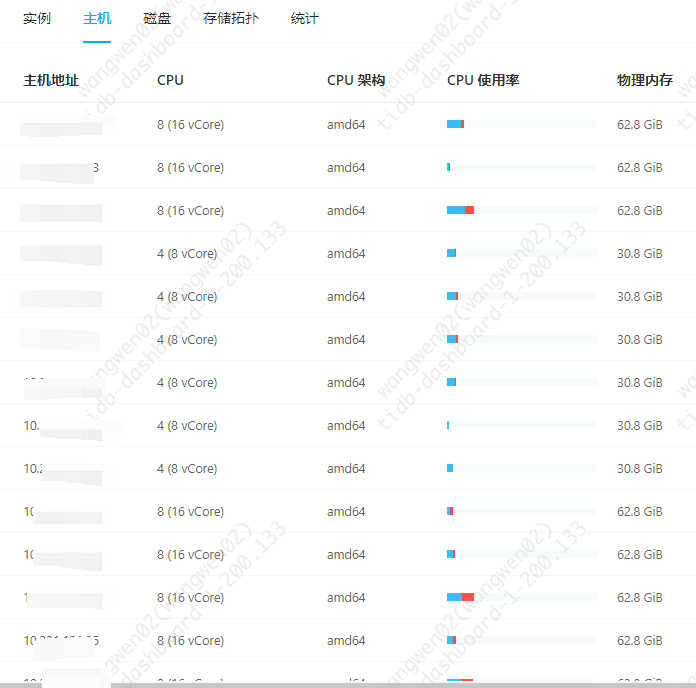
【附件:截图/日志/监控】
PD Server 日志:
[2024/06/07 11:38:07.294 +08:00] [INFO] [operator_controller.go:681] [“send schedule command”] [region-id=1159170] [step=“add learner peer 41444669 on store 3941762”] [source=“active push”]
[2024/06/07 11:38:07.794 +08:00] [INFO] [operator_controller.go:681] [“send schedule command”] [region-id=2215918] [step=“add learner peer 41444617 on store 3941762”] [source=“active push”]
[2024/06/07 11:38:07.794 +08:00] [INFO] [operator_controller.go:681] [“send schedule command”] [region-id=2005331] [step=“add learner peer 41444642 on store 3941763”] [source=“active push”]
[2024/06/07 11:38:07.794 +08:00] [INFO] [operator_controller.go:681] [“send schedule command”] [region-id=889315] [step=“add learner peer 41444654 on store 3941763”] [source=“active push”]
[2024/06/07 11:38:07.794 +08:00] [INFO] [operator_controller.go:681] [“send schedule command”] [region-id=2202636] [step=“add learner peer 41444664 on store 3941763”] [source=“active push”]
[2024/06/07 11:38:07.794 +08:00] [INFO] [operator_controller.go:681] [“send schedule command”] [region-id=233868] [step=“add learner peer 41444657 on store 3941762”] [source=“active push”]
[2024/06/07 11:38:07.794 +08:00] [INFO] [operator_controller.go:681] [“send schedule command”] [region-id=165246] [step=“add learner peer 41444652 on store 3941763”] [source=“active push”]
[2024/06/07 11:38:08.294 +08:00] [INFO] [operator_controller.go:681] [“send schedule command”] [region-id=2136399] [step=“add learner peer 41444667 on store 3941762”] [source=“active push”]
[2024/06/07 11:38:08.294 +08:00] [INFO] [operator_controller.go:681] [“send schedule command”] [region-id=898673] [step=“use joint consensus, promote learner peer 41444668 on store 3941763 to voter, demote voter peer 898676 on store 2 to learner”] [source=“active push”]