【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
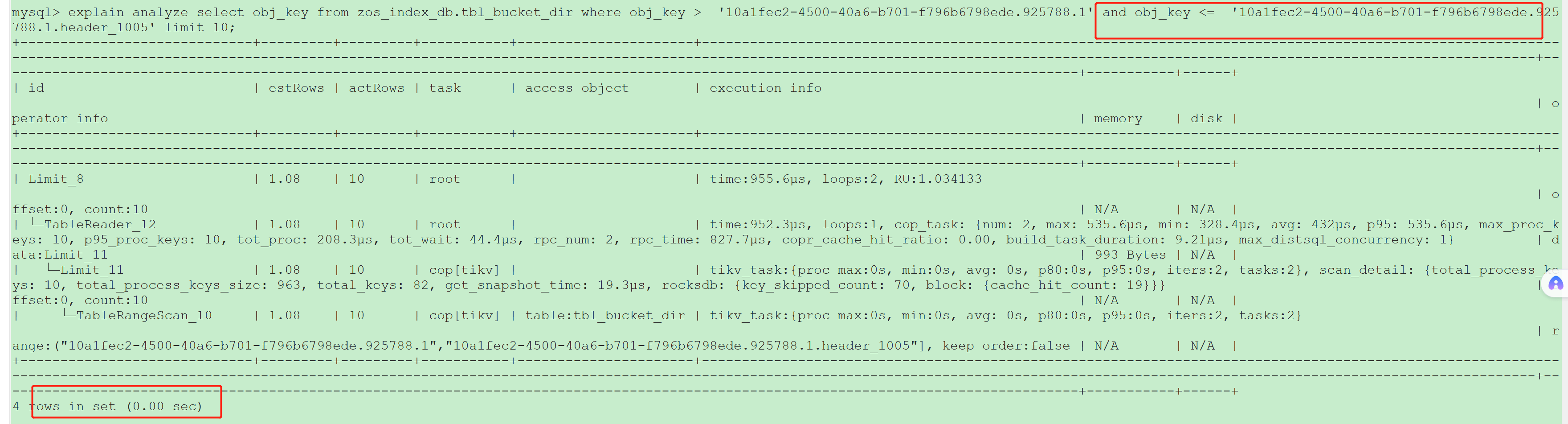
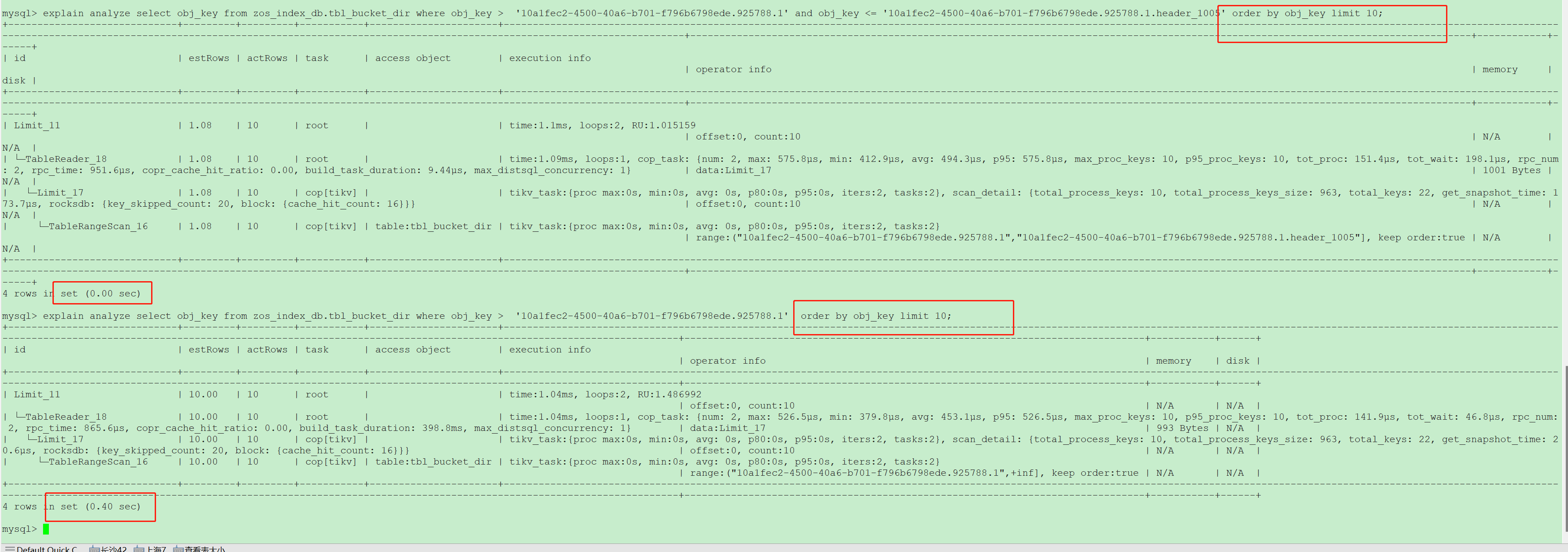
两个范围查询返回相同的数据,一个带有结束范围一个不带结束范围,时延差别巨大。
- 查询范围(start, end)查询返回快
(1) 该范围内只有10条数据;
(2)obj_key是主键;
(3)主键为cluster
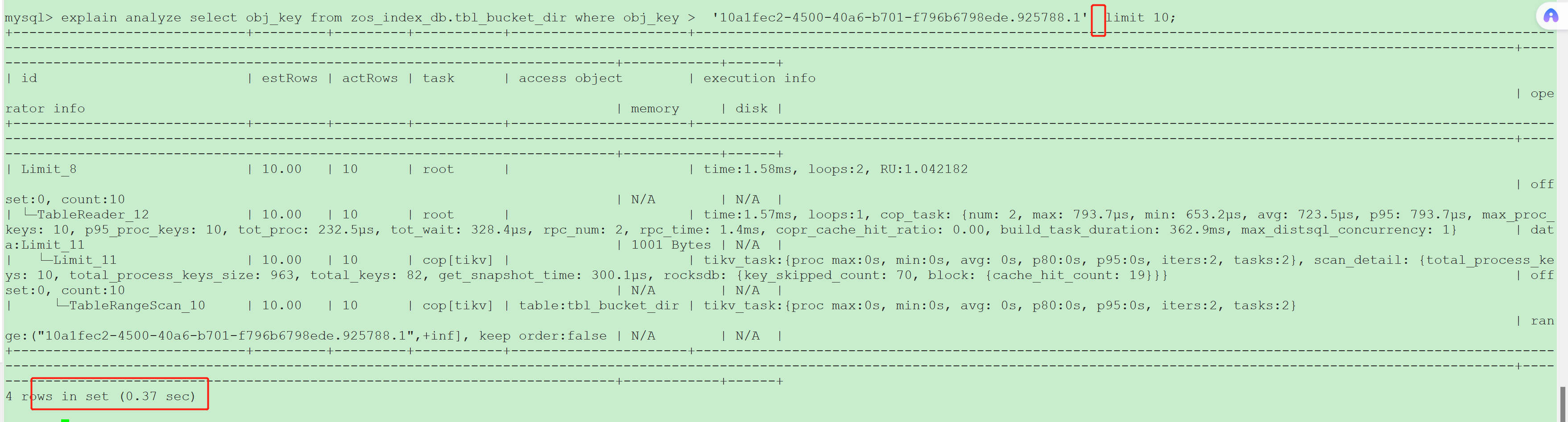
- 查询范围(start, 不指定)查询返回慢
(1) 该范围内有10亿条数据,但limit 10条;
(2)obj_key是主键;
(3)主键为cluster
两种场景的起始范围一样,返回的数据也一样。
多次查询均为该结果(排除内存命中差异)。
为什么时延会有这么大的差异??
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
返回大,扫的数据就会多,limit只是你限制了返回的数据量,不代表扫描的数据量也会被限制。
看前后两个执行计划,一个执行时间接近1ms,一个1.5ms,差别也不是很大吧
1 个赞
Kongdom
(Kongdom)
4
limit是在tidb层聚合的时候limit10,不是取每个tikv节点取数时只取10条,因为是分布式的,每个tikv节点取10条,到tidb层聚合时,可能就比10条少了。
1 个赞
Kongdom
(Kongdom)
6
例如标准部署3tikv节点,90条数据均由分布在3个节点,1-30在节点A,31-60在节点B,61-90在节点C。
集中式数据库,90条数据存储在1个节点。
现在要查limit 10,
集中式数据90条都是存储在1个节点,直接在存储节点取10条数据,返回到客户端。
分布式数据分布在3个节点,需要从每个节点取30条数据,然后再tidb节点汇总90条数据后再排序取前10条。如果每个存储节点取10条,汇总到前端30条,但这30条可能不包含 90条排序的前10条。
1 个赞
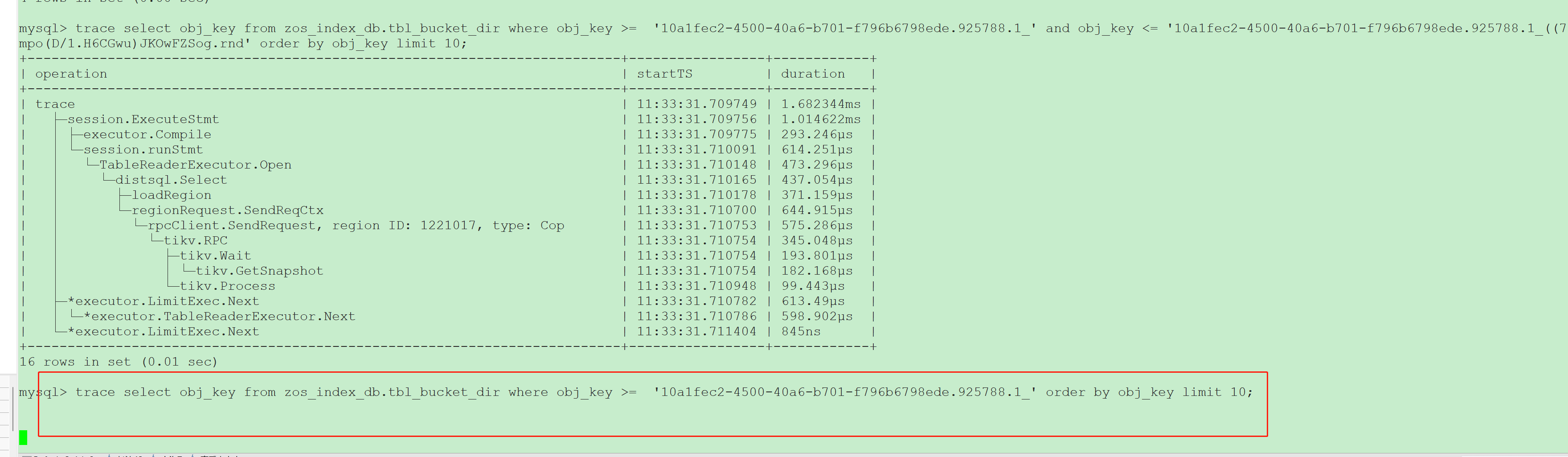
我的数据在tikv上按照主键有序存储的, 这里查询到是10条连续的数据,应该都分布在一个分片上,也就是说从单个tikv返回就行了,不需要到所有的tikv上去查询。
即使从所有的tikv节点查询,再到tidb节点做limit, 时延也不应该差距几十倍上百倍吧?
执行计划上显示的时间一个接近1ms, 一个1.5ms差别不算大,但是:
两个场景最后一行分别显示:
4 rows in set(0.00 sec)
4 rows in set(0.37 sec)
这个表示两查询返回的时延差异很大。
是的, 稳定复现!
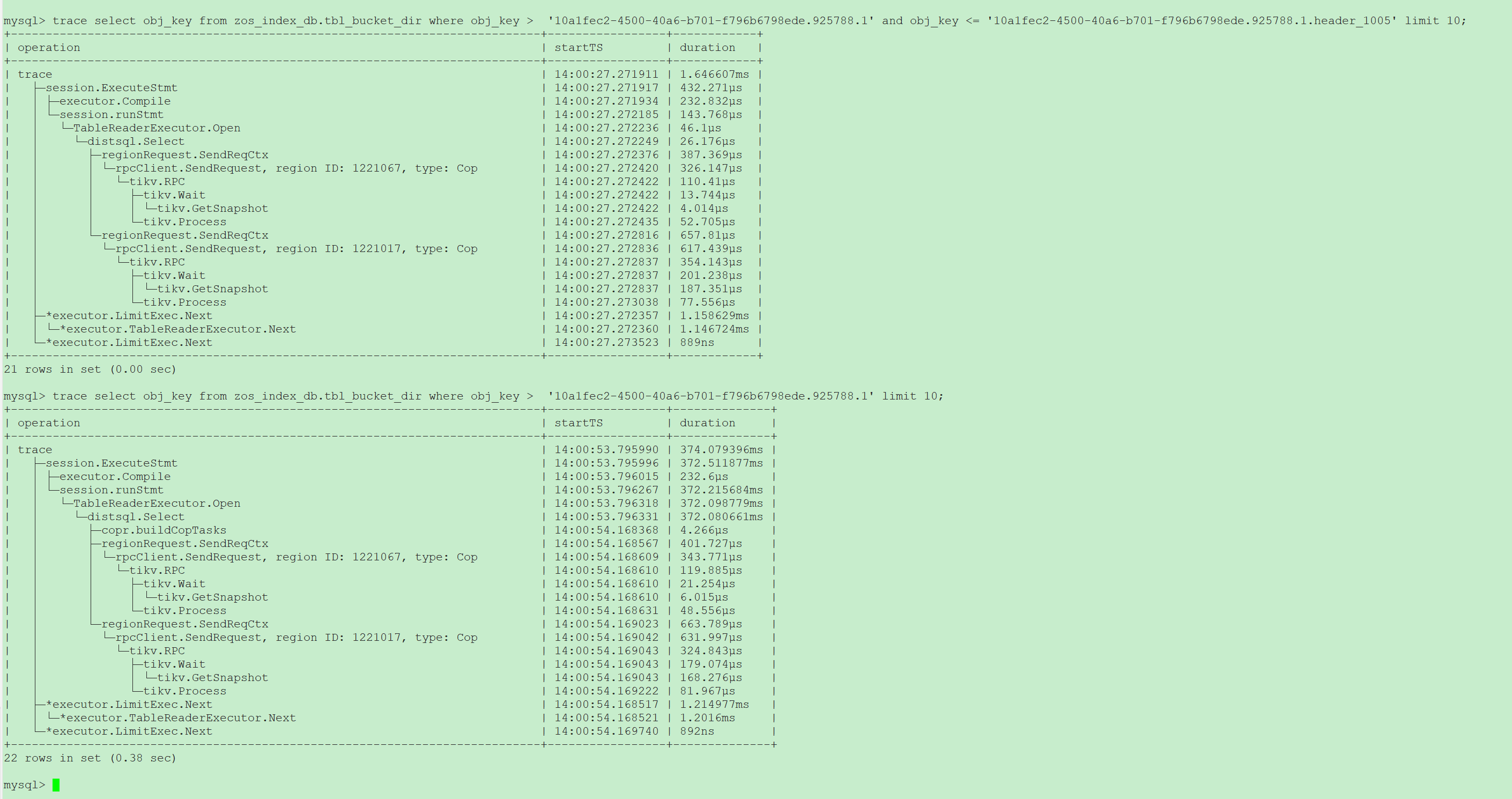
我这边有环境稳定复现,有专家大佬可以远程看一下么,
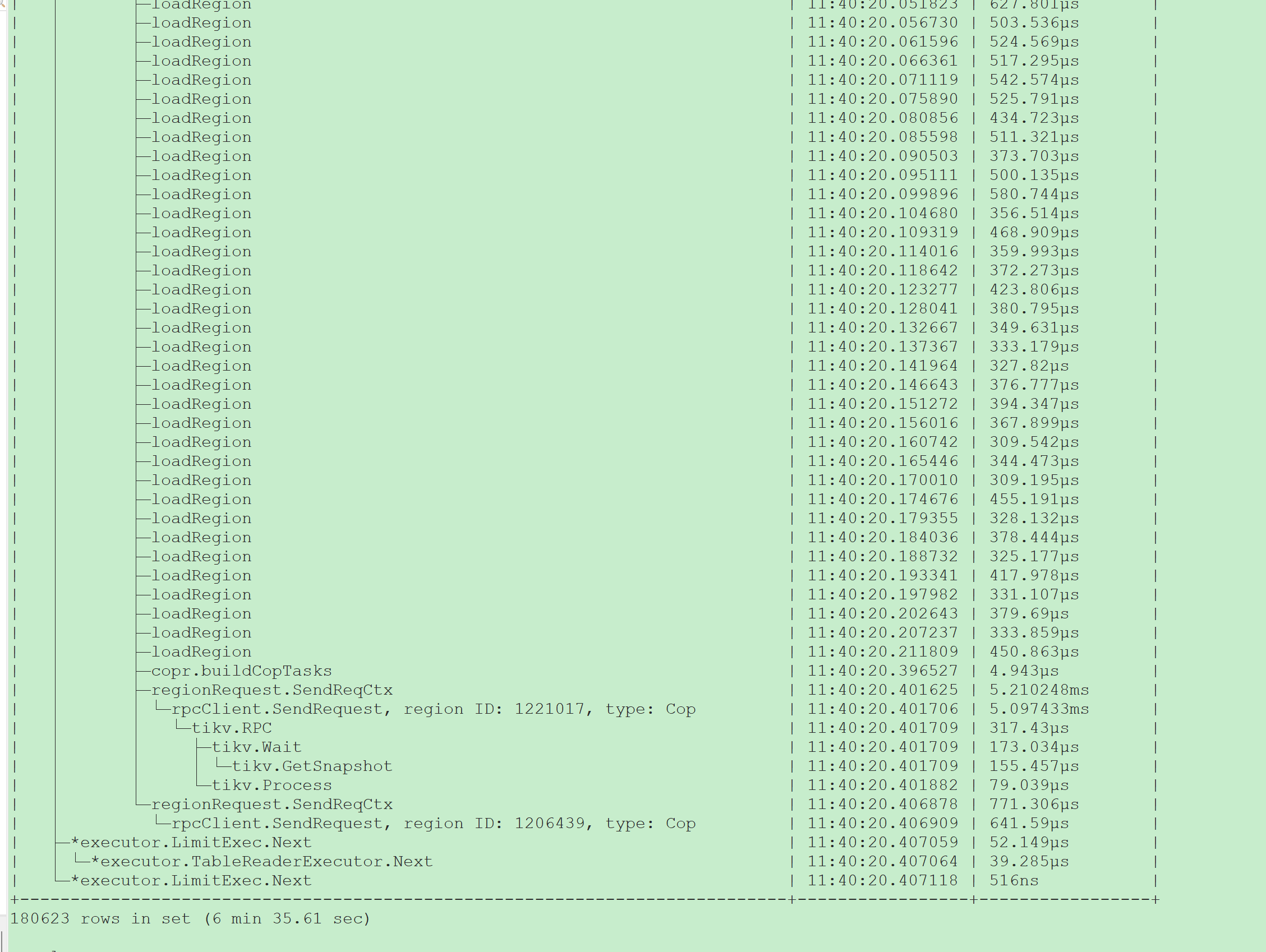
下面这个执行了大概五分钟,刷屏了,满屏打印的 loadRegion
1 个赞
h5n1
(H5n1)
13
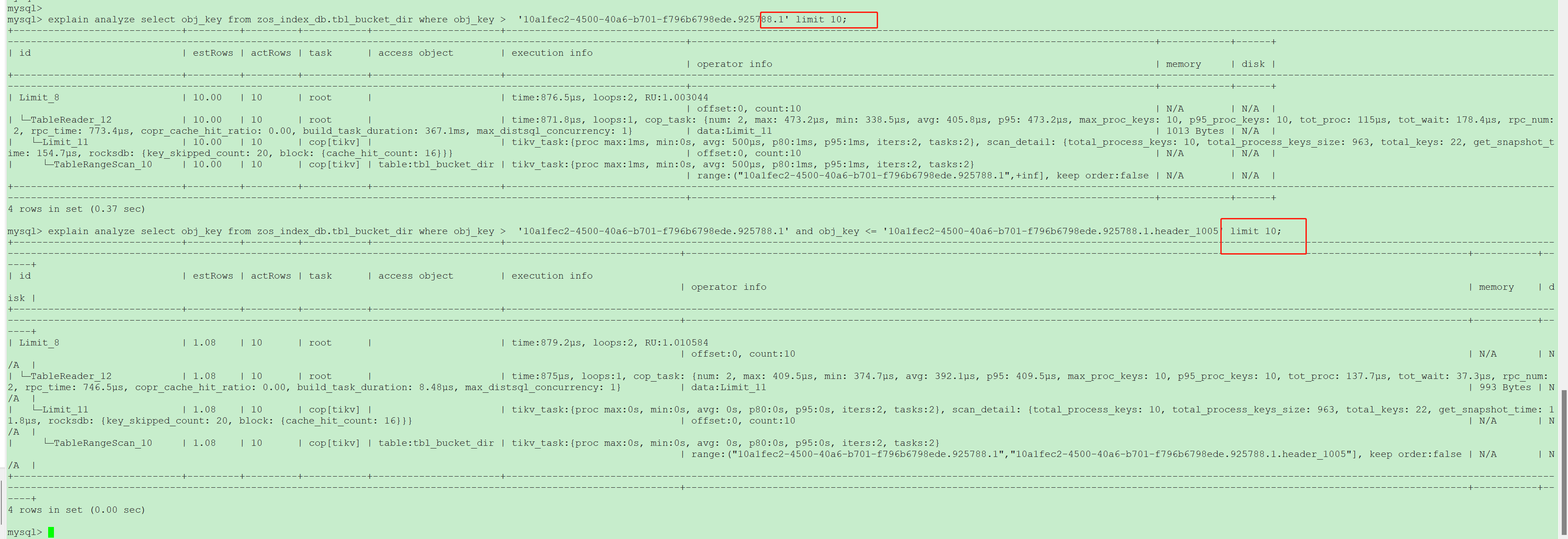
你发帖的截图里SQL没有order by
第二个SQL 看上去build task时需要获取所有region的信息
Kongdom
(Kongdom)
14
 guid做主键,在存储上应该是分散的吧?我是这么理解的。
guid做主键,在存储上应该是分散的吧?我是这么理解的。
1 个赞
有没有order by差别不大,
都有order by
都没有order by
这不是很明显吗?没有结束范围的话,需要扫描从开始的位置往后的所有region。然后再在tidb层聚合。有结束范围的话,只扫描范围内的几个region就行了。
他这个用于筛选过滤的是字段是主键,不是其他非主键字段
如果按照你所说,会随着数据量的增加查询时间不段增大。这种如何优化呢