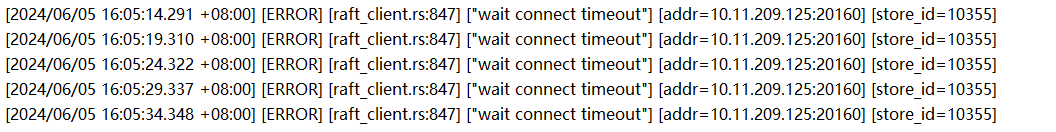Kongdom
(Kongdom)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.3
【复现路径】无
【遇到的问题:问题现象及影响】
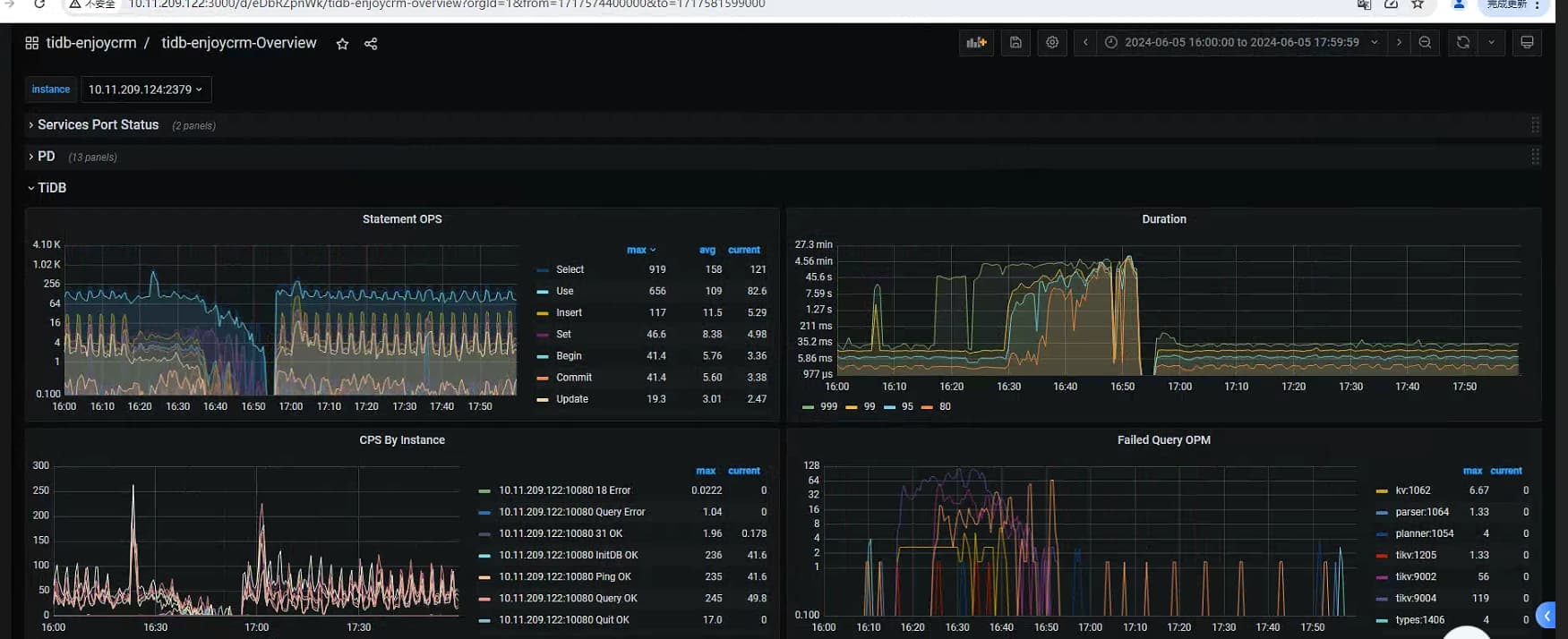
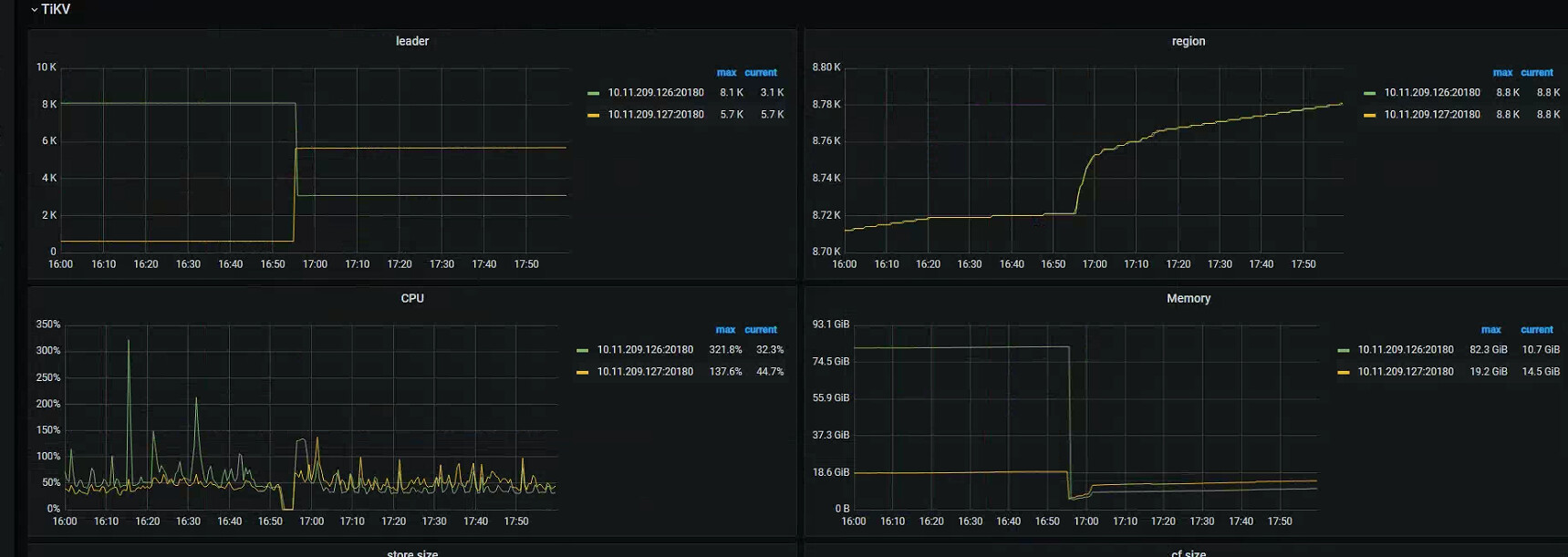
正常使用过程中,集群突然响应特别慢,dashboard及grafana也打不开,重启集群后集群响应正常。
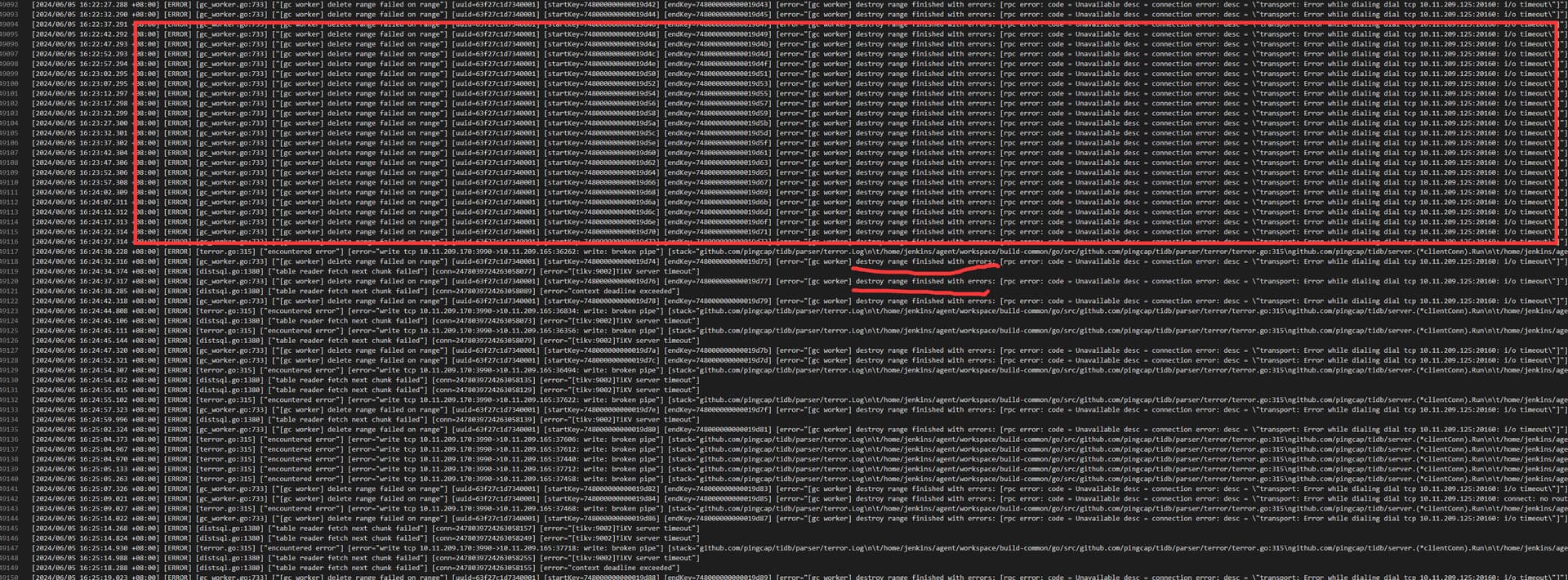
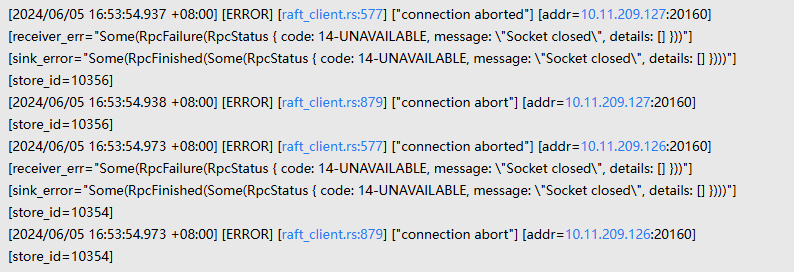
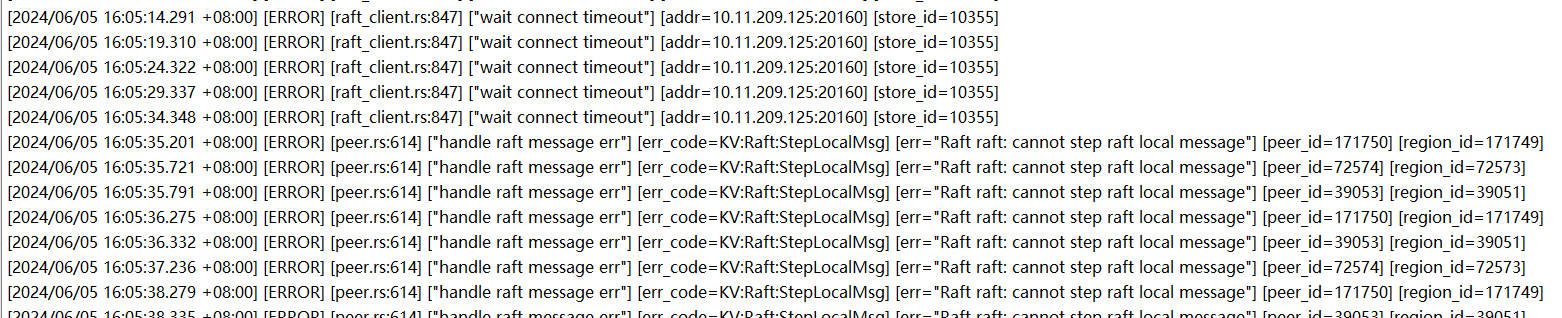
检查日志发现有以下错误信息:
重启后拿到的相关监控截图
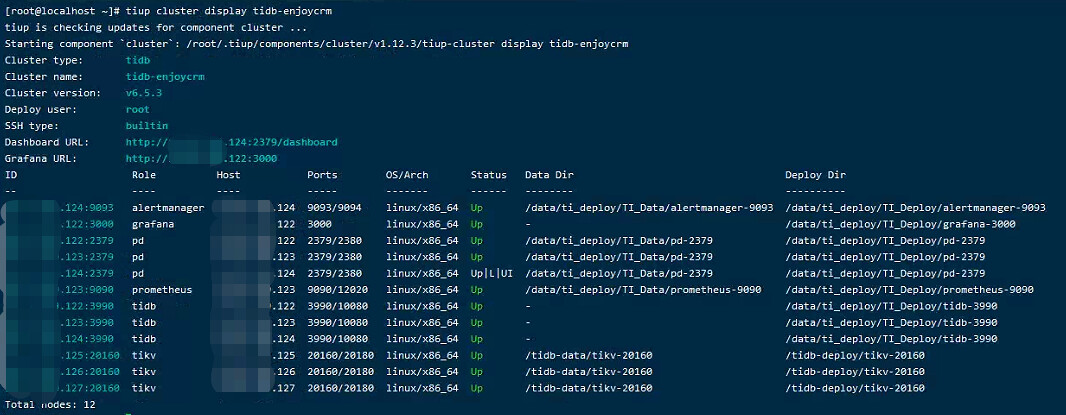
集群配置,tidb+pd混布3节点,tikv3节点。
日志文件:
122.tidb.log (31.3 KB)
123.tidb.log (12.8 MB)
124.tidb.log (22.9 KB)
125.tikv.log (966 字节)
126.tikv.log (3.1 MB)
127.tikv.log (72.1 MB)
lemonade010
(Ti D Ber Sd Dr Zqk O)
2
tidb.log 查看下expensive query , expensive query 日志和慢查询日志的区别是,慢查询日志是在语句执行完后才打印,expensive query 日志可以将正在执行的语句的相关信息打印出来。当一条语句在执行过程中达到资源使用阈值时(执行时间/使用内存量),TiDB 会即时将这条语句的相关信息写入日志
Kongdom
(Kongdom)
3
tidb日志级别是error,三个节点的tidb日志都搜了,没有expensive query
1 个赞
lemonade010
(Ti D Ber Sd Dr Zqk O)
4
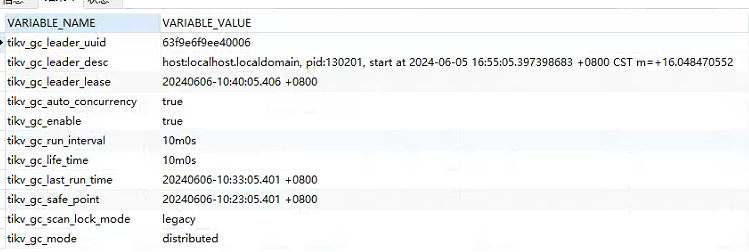
[2024/06/05 17:29:14.463 +08:00] [ERROR] [gc_worker.go:733] [“[gc worker] delete range failed on range”] [uuid=63f9e6f9ee40006] [startKey=748000000000019a8e] [endKey=748000000000019a8f] [error=“[gc worker] destroy range finished with errors: [rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.11.209.125:20160: i/o timeout"]”]
看看GC任务正常执行吗?
Kongdom
(Kongdom)
9
没有,三个组件的日志级别都是error。
tikv里主要是连接超时,和raft报错
1 个赞
Kongdom
(Kongdom)
11
可能是防火墙,早上关闭防火墙之后,就没有这个报错了。
1 个赞
Kongdom
(Kongdom)
15
是的125这台防火墙禁用之后,没有报错连接超时了。
1 个赞
xfworld
(魔幻之翼)
18
生产环境开防火墙,咋想的… 还不给白名单进行排除…