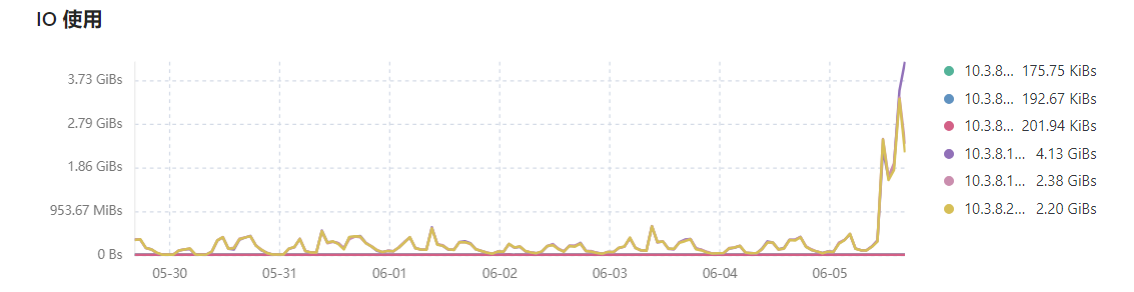
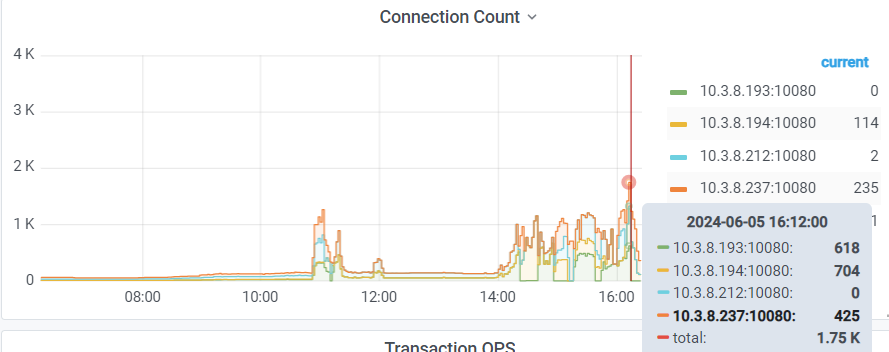
tidb集群遇到大量的查询请求,3个kv节点的io读非常高,重启整个集群tikv的IO读无法下降
先看慢SQL
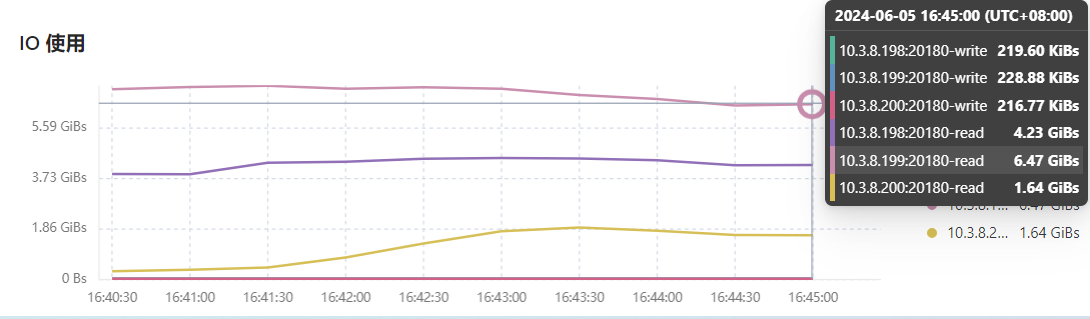
慢查询优化下
刚刚把网关关闭,同时,把整个tidb集群关闭几分钟,然后,再开启集群。打开网关,tidb的请求增长,tikv的io read也开始不断的升高。
好的,我看下慢Sql
查询 导致大量磁盘io 一查慢语句,优化索引 ,二看 grafana(tikv) 看看慢在哪里。查看下是否配置的问题。其他的想想有没有其他的操作。
看dashboard 慢sql,优化慢sql,这才是解决的办法,重启不能解决问题
dashboard查看慢sql,大量请求的sql,逐一排查
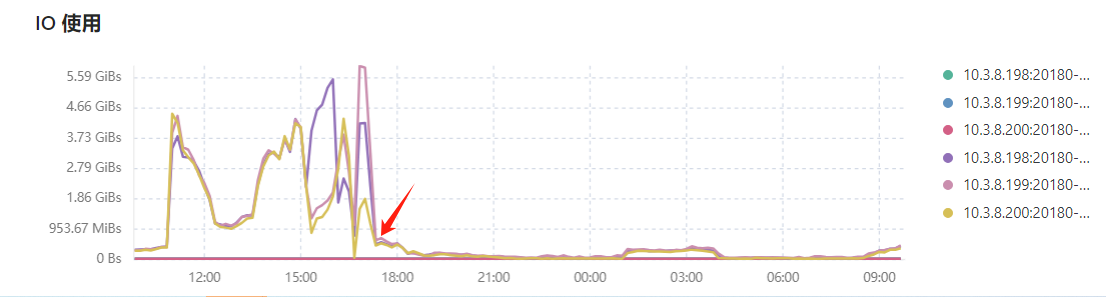
昨天的问题已经解决,原因是有一张600万的业务表的健康度不高,业务侧大量的查询使用此表进行关联查询。对此表进行analyze table table_name统计信息收集后,tikv的io read立刻就降下来。
涉及到需要调整的参数如下:
-- 1、打开收集信息的自动收集功能:
mysql> show variables like 'tidb_enable_auto_analyze';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| tidb_enable_auto_analyze | ON |
+--------------------------+-------+
1 row in set (0.00 sec)
-- 2、调整tidb_auto_analyze_ratio参数,由原来的0.7调整为0.3,指的是当表中超过 30% 的行被修改时,触发自动 ANALYZE 更新。
mysql> show variables like 'tidb_auto_analyze_ratio';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| tidb_auto_analyze_ratio | 0.3 |
+-------------------------+-------+
1 row in set (0.00 sec)
-- 3、修改为北京起始时间,代表从凌晨的00点到次日的08点,这段时间进行自动收集
mysql> set global tidb_auto_analyze_start_time='00:00 +0800';
Query OK, 0 rows affected (0.01 sec)
mysql> set global tidb_auto_analyze_end_time ='08:00 +0800';
Query OK, 0 rows affected (0.03 sec)
吧超时的sql我记得有个参数可以自动kill掉
好案例学习了
首先看dashboard的慢SQL,还有索引,慢SQL表的统计信息等等
健康度不高,导致索引搞错,这个情况比较常见。analyze是一个办法。还有就是绑定执行计划,这样的话表的健康度再低也不影响了。