作者:李文杰 TiDB 社区版主 TiDB 社区华南地区组织者
表妹推荐:
在面对数据库升级这一关键而敏感的操作时,本文提供了全面的策略和步骤,确保升级过程既安全又高效。
无论是选择原地升级还是整体迁移升级,文章都详细阐述了各自的优缺点和适用场景,帮助读者根据自身需求做出最佳决策。特别是对于要求极高、不允许停机的金融级场景,文章还介绍了双向同步灰度迁移升级的方案,确保升级过程的平滑和数据的一致性。
通过这些精心设计的策略,读者可以更加自信地应对数据库升级带来的挑战,保障业务的连续性和稳定性。
推荐给所有需要进行数据库升级操作的专业人士,以确保你们的系统升级既安全又高效。

一、前言
数据库作为应用系统的核心存储层,任何一点风吹草动都可能影响到线上客户的访问体验。升级操作必然会涉及到启停这样的重操作,所以对于整个上下游系统这是非常敏感和危险的操作。
除此之外,升级之前还需要投入大量的时间与精力评估升级收益,比如修复数据库bug或者安全漏洞、使用新特性新功能等;还需要业务侧提前去做大量的兼容性和性能验证工作。对整个团队而言,非不得已,不会去考虑升级数据库的事项。但总会有一些不得不升级的情况,对于这些需求场景,我们会有不同的升级策略。
二、TiDB升级策略
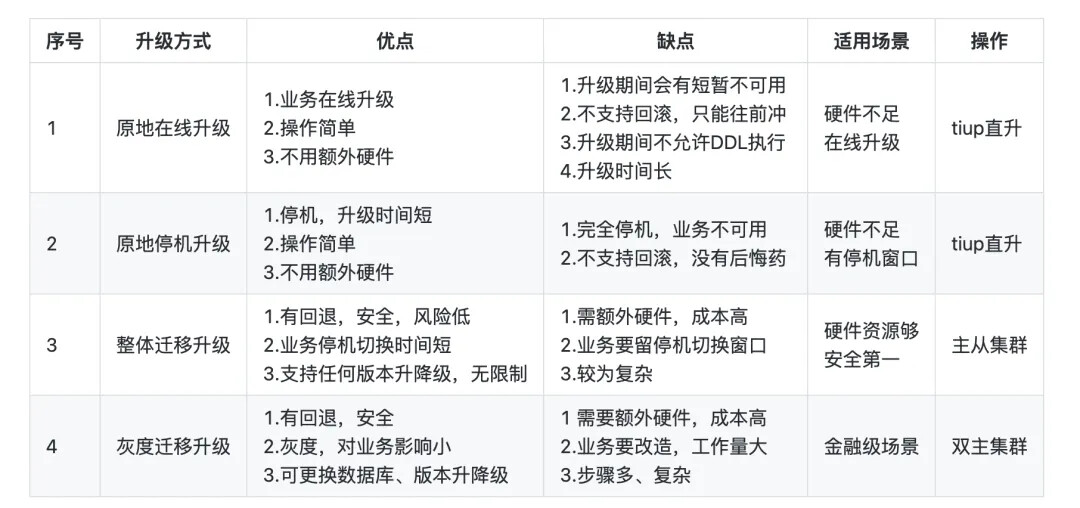
我们升级TiDB集群,大概来说通常有下面的升级策略:
1、原地升级
2、迁移升级
对于原地在线升级和原地停机升级这两个方式,官网有详细的说明,可直接参考升级 https://docs.pingcap.com/zh/tidb/stable/upgrade-tidb-using-tiup。
三、整体迁移升级
要做整体迁移升级,我们需要复制部署一个不差于待升级集群的新集群。
什么叫做“不差于”呢?其实主要从两方面来评估:
- 一个方面是容量空间能存得下数据
- 另一个是访问性能可以满足业务要求。
这个方案允许升级操作有回退的余地,在一些非常敏感和一定不能出错的场景,必须要考虑回滚操作。同时此方案不要求前后集群的拓扑一致,也就是说也可以通过迁移升级的方式,还可以让集群实现调整整体架构、迁移机房、批量更换集群机器硬件、批量更换操作系统等,且比扩缩容的方式更安全可靠。
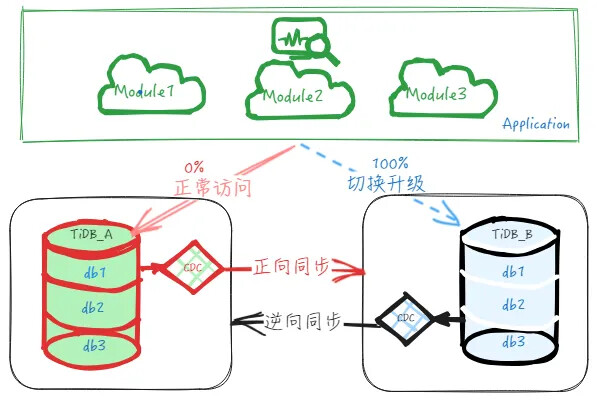
如下图所示,是迁移升级的整体架构图,大致的操作思路就是部署一个新的集群,在导入基量数据后搭建正向的实时增量同步,建立主从集群。待到迁移时,停止业务访问主集群,校验上下游数据一致性后,停止正向同步并开启逆向同步,然后业务访问切换到下游从集群,实现迁移升级操作。
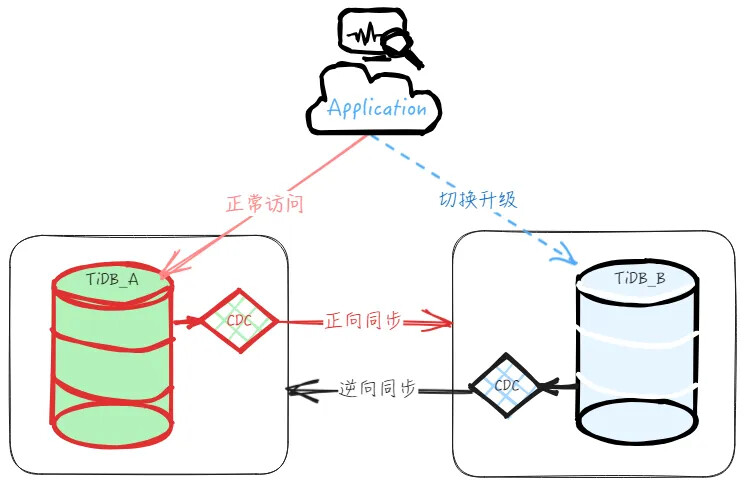
具体的步骤如下:
- 搭建主从同步
-
迁移用户和权限。
-
SQL Binding迁移。
-
定时任务迁移:如定时统计分析脚本、数据备份脚本、定时 analyze 脚本等。
-
基量数据:如果数据量在GB级别,可以使用 Dumpling+Lightning 方式迁移基量数据,如果数据规模在TB级别,建议使用BR进行备份和恢复到下游集群。基量数据恢复完成后,使用sync_diff_inspector 工具校验上下游集群的数据,保证数据一致性。
-
增量数据:如果上游集群版本在v4.0.16以后,可以通过部署TiCDC集群来实现实时增量同步;如果是更老之前的版本,建议使用TiDB Binlog工具 Pump+Drainer 搭建主从实时同步。
-
观察一段时间,不定期使用sync_diff_inspector 校验上下游集群的数据一致性情况。这里也可以结合实际情况,开发检查工具实现一致性快速校验,以避免使用sync_diff_inspector工具进行全量数据校验时耗时过久。
-
业务可以在从集群充分进行新版本的兼容性和性能校验,提前发现和修复问题。如果测试污染了数据,可以在上线前根据上述步骤重建主从集群。
-
参考上游集群的数据量规模和增速,以及访问QPS性能等需求部署一个新的集群。
-
提前设置集群参数:继承上游特殊调整的参数,设置新版本功能参数等。
-
部署新集群:前后拓扑架构可以不相同。
-
搭建主从集群:配置正向同步。
-
周边业务迁移:提前迁移周边辅助业务。
- 整体迁移升级
- 业务确认迁移升级的时间窗口,提前做好公告。
- 业务停止服务,如果有需要则可以锁定或回收上游集群的读写权限,确认上游无业务访问请求。
- 确认数据追平,主从一致。
- 停止正向同步。
- 业务切换访问下游数据库。
- 启动业务,确认请求都正常读写下游集群。
- 业务验证
- 确认逆向同步正常,不定期进行上下游数据一致性检查。观察一段时间。
- 应急回滚:流量切回老集群
- 业务确认出现短时间无法解决的问题,需要实施回退方案。
- 停止业务访问从集群。
- 重新授权业务读写上游集群的权限。
- 确认数据追平,逆向同步的主从一致。
- 业务切回上游主集群,启动业务。
- 进一步排查和修复问题,再排期安排下次切换升级操作。
上面的操作是把业务应用看做一个整体来进行切换升级的,迁移时,整个业务会有短暂的停机窗口,在该时间窗口内容,业务服务不可用。
在一些更敏感或要求更高的场景,比如付费业务,是不允许有停机窗口或者不允许存在业务全部流量不可用的情况出现的,那么这个时候就得考虑业务灰度割接的方案,逐步将应用流量分批迁移,完成升级。具体如下双向同步的方案:
四、双向同步灰度迁移升级
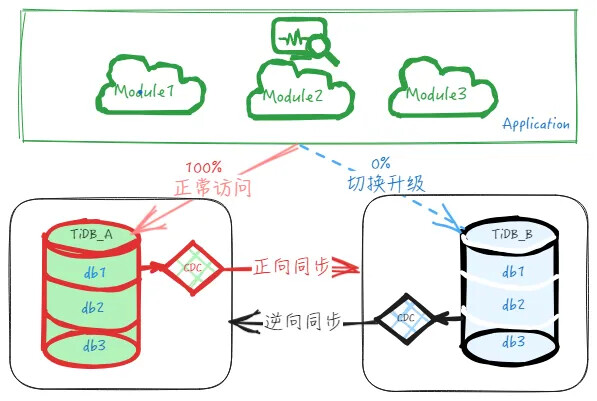
对敏感或高要求业务,不允许出现全部业务不可用的情况,那么就需要调整业务本身,对业务进行模块话切分,使得业务应用支持分批灰度切换。这样我们可以对整体迁移升级的方案做一些改造,实现灰度迁移升级,从而可以更加安全地升级数据库。
基于这个场景下,我们可以一起来探讨下双向同步的迁移升级方案。
两个集群双向同步的前提:是写入两个集群的数据必须保证无冲突。也就是需要业务侧能够做好管理,保证访问能够隔离,即理论上在两个集群中不会同时修改同一张表的同一行,否则双向复制会有相互覆盖的情况。实际操作来说,业务流量需要做到按库或按表级别进行访问隔离,方案实施才更具可行性。
双向同步灰度迁移升级具体操作大致如下:
- 业务改造
- 业务根据业务特点进行垂直改造,使得业务本身支持分模块部署(微服务化),访问的数据库或者表之间实现相互隔离。
- 业务在线上完成分模块的部署优化。
- 搭建主从同步
- 这一步和上文整体迁移升级的步骤类似,此处不再赘述。
(持续迁移…)
- 灰度迁移升级
-
期间始终确认正向和逆向的同步正常,同时不定期进行上下游数据一致性检查,为随时回退做准备。
-
对迁移的业务,及时跟踪和验证准确性,如果有任何短时间无法修复的问题,及时回滚。如果无任何异常,则继续观察一段时间(通常以天为单位)。
-
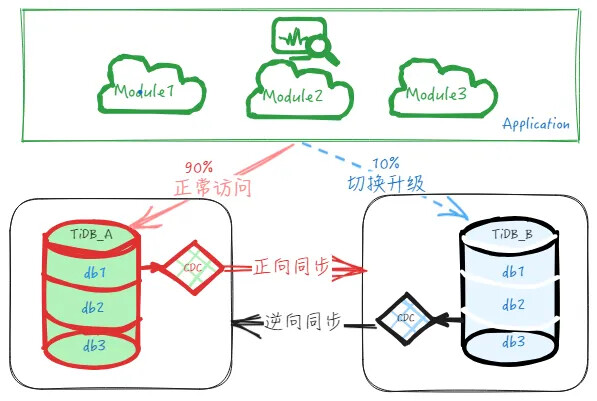
已迁移的业务能保持稳定运行一段时间后,继续开启第二批迁移升级任务,迁移其他模块到下游集群,迁移的业务流量从10%上升到20%(实际流量份额由业务定),然后继续验证、观察,有异常则修复或回退,正常则继续。
-
之后再继续迁移剩余模块,验证、观察,步步为营,稳扎稳打推进,直到把全部业务流量100%迁移到下游集群。
-
刚开始时,只迁移相对没那么重要的个别模块到下游或者只迁移部分流量,如上示意图, 如上示意图,先迁移访问数据库 db1 的10% 的业务流量到下游,迁移后业务直接访问下游 TiDB_B 的 db1 库,而上游 TiDB_A 的不再有业务直接访问,只承接逆向同步过来的数据。
-
业务确认分模块迁移升级的时间窗口,确认正向同步和逆向同步运行正常。
- 应急回滚:流量切回老集群
- 如果所迁移的业务确认出现短时间无法解决的问题,则要实施回退方案。
- 停止所迁移的业务访问从集群。
- 重新授权业务读写上游集群的权限。
- 确认数据追平,逆向同步的主从一致。
- 把业务切回上游主集群,启动业务。
- 进一步排查和修复问题,再排期安排下次切换升级操作。
关于TiCDC的双向复制注意细节,尤其是 DDL 对业务的影响,可以进一步参考官方文档:https://docs.pingcap.com/zh/tidb/stable/ticdc-bidirectional-replication。
五、总结
数据库升级操作是一个高危操作,需要结合实际情况,根据数据库使用的环境(测试、生产)、业务类型(离线、在线)、是否有停服窗口期、是否有高敏感性等内容,综合评估风险与收益,再徐徐图之。
总之,尽量采取稳健、逐步推进的方式去对待升级操作,才是合适之举。