【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】.NET编写插入语句,每次在30张表分别插入1000条数据,持续运行。 查看服务器内存,持续增涨,当达到 峰值,就无法连库了。 已设置集群占用内存80%,但是效果一样出现。 有没有碰到相关现象的?怎么调整配置? 下图是重启Ubuntu后截图。 QPS为0的时候,是无法连接数据库的情况,在无操作的情况下,可以自动恢复,但是时间太长了。
【遇到的问题:问题现象及影响】
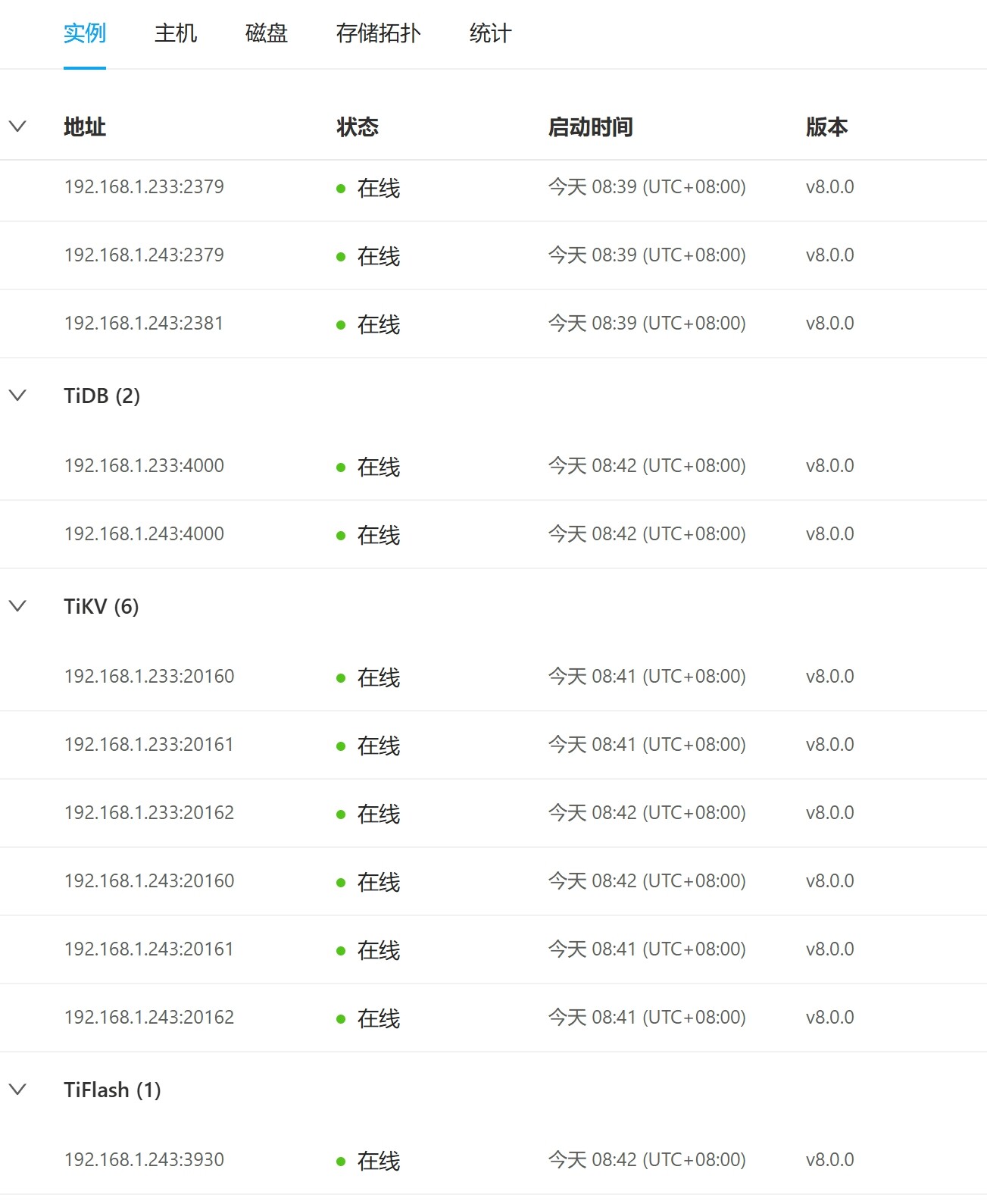
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
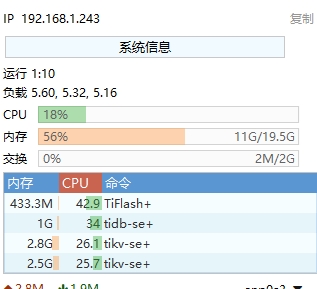
这数据量也不算大吧,这就小了? 这是虚拟机,那我调到 32G,再观察观察。
h5n1
(H5n1)
4
32G也不大,如果你仅仅是测试 tikv砍掉3个, 不考虑性能没用负载均衡 tidb 砍一个, 还要设置tikv的capacity 控制内存
啦啦啦啦啦
5
感觉这种数据量不大,这都是按照默认值走的。 先调整完看看,不行了,重新调整一下。
多个服务器就算混合部署啦。
现有配置,循环插入,连4个小时都 扛不住,就内存满了。 有点接受不了。
如果按照这个来说,配置服务器太多了,以项目为单位部署的话,成本太高了。
如果项目共4个服务器,当成数据库的情况下,最多只能有2台,那这些配置要如何控制? 可以达到最优性能和稳定性。 CPU,内存达到 峰值,可以接受插入和查询慢的问题 。 但是不能接受连接数据库不成功的问题 。
啦啦啦啦啦
8
参数调好的话也能用,就是性能,高可用性这些保证不了了。如果数据量真的不大不如用mysql?
设备运行数据 ,一个设备有上百数据点,数据保存在5秒左右。 设备量计划500~2000。
软件需要持续运行,历史数据量还是比较可观的,使用MySql应该是扛不住。
h5n1
(H5n1)
10
就算组件混布,至少也得3台虚拟机 否则没法保证高可用
小龙虾爱大龙虾
(Minghao Ren)
11
迪迦奥特曼
(迪迦奥特曼)
13
网址看了,里面说的 etc/config-template.toml 文件找不到 。
下面中的参数说明结构,也未找到对应的修改的位置 。
里面同时提供了tiup cluster edit-config ${cluster-name} 这个的修改,我在这里面也没有看到 相关的模板,KV的内存在哪里设置 ?
WalterWj
(王军 - PingCAP)
19
tidb 每个组件默认用服务器内存的 80% 的内存。tikv 有缓存的。你得配置内存使用量。
在线配置如下:
server_configs:
tidb:
log.slow-threshold: 300 # 注意这里的键可能需要根据 TiDB 的实际配置进行修改
tikv:
readpool.storage.use-unified-pool: true
readpool.coprocessor.use-unified-pool: true
storage.block-cache.capacity: “2147483648”
pd:
replication.enable-placement-rules: true
replication.location-labels: [“host”]
tiflash:
logger.level: “info”
设置 storage.block-cache.capacity=2G后,现在KV最大运行内存达到 4G,已插入2个半小时,看情况,还是有增长的现象。
WalterWj
(王军 - PingCAP)
21
storage.block-cache.capacity=2G * 2.2 差不多就是 tikv 最后使用的内存大小。