【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】6.5
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
TiDB在高并发场景下具有显著的优势,这些优势主要源于其分布式架构和独特的设计特性。云原生设计、分布式架构与弹性扩容、金融级高可用、实时HTAP能力、针对高并发批量写入场景的优化等等。
- 分布式架构: TiDB 采用分布式架构,数据存储在多个节点上,可以水平扩展以应对大规模数据的存储和处理需求。这种架构使得 TiDB 能够轻松应对大规模数据和高并发的访问。
- 水平扩展性: TiDB 可以通过简单地增加节点来实现水平扩展,而不需要修改应用程序代码。这使得 TiDB 能够轻松应对数据量的增长和流量的变化。
- 一致性和高可用性: TiDB 支持强一致性和高可用性。它通过 Raft 协议来实现数据的一致性复制和故障转移,确保数据的安全性和可靠性。
- 分布式事务: TiDB 支持分布式 ACID 事务,可以保证跨多个节点的数据操作的一致性和原子性。这使得 TiDB 能够满足对事务性操作有严格要求的应用场景。
- SQL 兼容性: TiDB 兼容 MySQL 协议和语法,可以直接替代 MySQL 作为数据存储引擎而无需修改现有的应用程序代码。这使得迁移现有的应用到 TiDB 变得更加容易。
- 实时分析: TiDB 支持在线分析处理(OLAP)和在线事务处理(OLTP),可以满足实时分析的需求。它的查询性能优秀,可以处理复杂的查询和大规模数据分析。
- 自动化运维: TiDB 提供了 TiDB Ansible、TiUP 等工具来简化部署和运维工作,提供了自动化的管理功能,减少了运维的复杂性和成本。
- 生态系统和社区支持: TiDB 生态系统正在不断发展壮大,有丰富的工具和组件可以与 TiDB 集成,满足不同场景的需求。同时,TiDB 拥有活跃的社区支持,可以获得及时的技术支持和解决方案。
TiDB适用于海量数据存储及高并发的 OLTP 场景,也适用于需要实时处理的大规模数据和高并发场景,在实时数据分析场景也有很优秀的表现。具体可以看看官网介绍:
TiDB可以作为Impala结合Kudu的一个替代选项,特别是你想要一个既能处理日常事务,又能做数据分析的数据库时。它因为是分布式的,所以随着数据量和访问人数的增长,可以通过增加服务器来提高处理能力和存储,这对于高并发查询是个利好。
TiDB支持HTAP,意味着数据分析可以直接在处理事务的数据库上完成,不需要数据迁移,这一步能省不少事儿。而Impala搭配Kudu,虽然也很适合数据分析,尤其是在Hadoop生态系统里,但对于事务处理就没那么直接了,可能会涉及到更多的系统管理和资源调配。
至于查询性能,TiDB的分布式特性让它在处理大量并发请求时表现不错,能够根据需要横向扩展。Impala和Kudu在某些场景下也很快,但可能需要更细致的集群管理和调优来保证高并发下的性能。
TiDB因为兼容MySQL,对很多用户来说上手会容易些。Impala则更适合已经用了Hadoop的环境。选择哪个,得看你的具体需求、现有的技术栈,以及团队熟悉度。总之,两者各有千秋,关键是找到最适合你当前情况的那个。
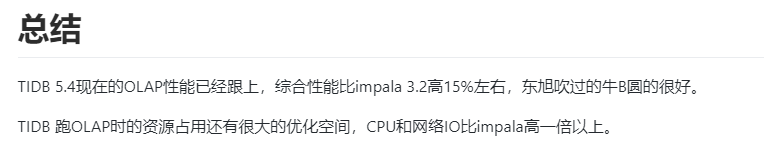
OLAP OLTP相结合