sfgao
(Ti D Ber Kv2 X7ojh)
1
场景描述:
- 数据的写入是通过离线任务驱动,将hive表中的数据同步到TiKv中,供业务侧查询。
- 写入量:每天有大约100亿的增量kv paris 写入,max到300亿。写入是通过调用rawClient的batchPut 、batchDelete方法,要求从源表产出到tikv写入完成,不能有太大的延迟,最大能接受24小时内写入完毕。
- 查询量:1百万/min,max到2百万/min,批量查询(batchGet),一个批次内查询的key数量,平均在10个key以内。
- 因为查询量大,且依赖kv查询的业务场景都比较核心,因此对查询时间敏感(p999要求在50ms以内)且要求稳定(不能有频繁的抖动和毛刺)(目前使用的MySql目前在10ms以内,但是写入比较吃力)
- 目前生产情况:12个节点,24.4T数据(包括副本),region数量(150w,包括副本),raft group = 1 leader + 2 follower。
总之:因为是离线方式写入,对leader和follower的数据不要求强一致性,只需要最终一致即可,对事务也没有要求,期望能够尽可能快速写入leader,能够稳定且低耗时的查询出来。
问题一: 关于 Follower Reader,能否支持 弱一致读,即不去同步 leader节点的 commit index,也不等待 apply log,直接读取follower节点当前的数据。
因为leader写入量比较大,经过线上测试,写入量大的时候,查询时间也会跟随上涨。 因此想要尝试follower read。
目前官方文档支持的是 follower强一致读,读follower的时间要经过一次rpc请求,且如果有延迟且需要等待 apply log 才能执行查询,是否可以去掉同步 leader commit index这一步。
经过生产测试,follower读的时间比leaderP99线要高出一倍:
问题二:Region Split 和 Merge, 对查询时间有何影响,具体是怎么作用的? 能否将对查询时间的影响控制在一个特定的范围内?
新数据的写入可能会频繁触发 region 的split,这个过程中查询时间也会有波动,如何降低这个影响?
问题三:mvcc是默认必须开启的么? 对数据没有强一致性要求,也没有事务要求的场景,数据层面能否不保留多个版本,只保留一个数据版本?
问题四:针对只需保证数据最终一致的非事务场景,有哪些针对性的调优策略或者参数,集群侧和客户端侧?
据了解,还有另外一个团队也有类似的场景,即将离线的hive数据同步到MySQL、ror等引擎中,供实时业务场景。
因此针对这一类特定的场景,是否有特定的优化方案 或者 后续是否有特定的迭代计划。
1 个赞
sfgao
(Ti D Ber Kv2 X7ojh)
2
一:tikv的MVCC
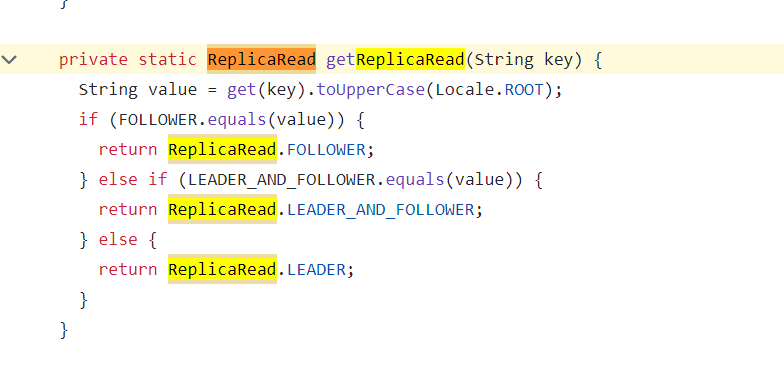
二:关于 tikv raw client 的 follower read 配置
TiConfiguration配置读策略:
副本选择策略的实现:
三:关于读写QPS
查询:max=35k/s,均值=15k/s,调用 raw_batch_get 方法,p99=30ms,但是毛刺比较多,每天约有16%~20%的请求,达到100ms左右。
写入:max=21k/s,均值=6.7k/s,调用 raw_batch_put + raw_batch_delete 方法。写入应用层做了一些限流,按照kvPairs 计算,6kw/min。
有猫万事足
3
我觉得你可以直接尝试一下tidis或者titan这类根据tikv二次开发的项目。
这两个项目基本都是redis协议访问+tikv存储。我虽然说不清楚他们具体做了那些优化,但这两个的性能报告看上去是满足你的要求的。
无非就是现在部署了以后是否还能满足要求,这个需要测一下。
至少我看上去,这两个在qps和p999延迟上都能满足你的要求。
而且我甚至觉得,如果他们玩tikv都达不到你的性能要求的话,你也不必继续用rawkv折腾了,折腾下去要达到要求希望渺茫。
ziptoam
(Ti D Ber D1q T Ff Sk)
6
TiDB目前的Follower Read设计主要是为了提供强一致性读取,即读取操作会等待Follower节点追上Leader的commit index,以保证数据的最新性。如果您希望实现弱一致性读取,直接从Follower读取未经确认的数据,当前TiDB原生并不直接支持这种模式。不过,您可以通过自定义实现来绕过这个限制,但这会增加开发复杂度和运维难度,并且可能引入数据不一致的风险。