vcdog
(Vcdog)
1
上游15万的更新操作,下游被放大到7000万的更新,如何提升ticdc的到下游tidb集群之间的数据同步速度,减小数据延迟。
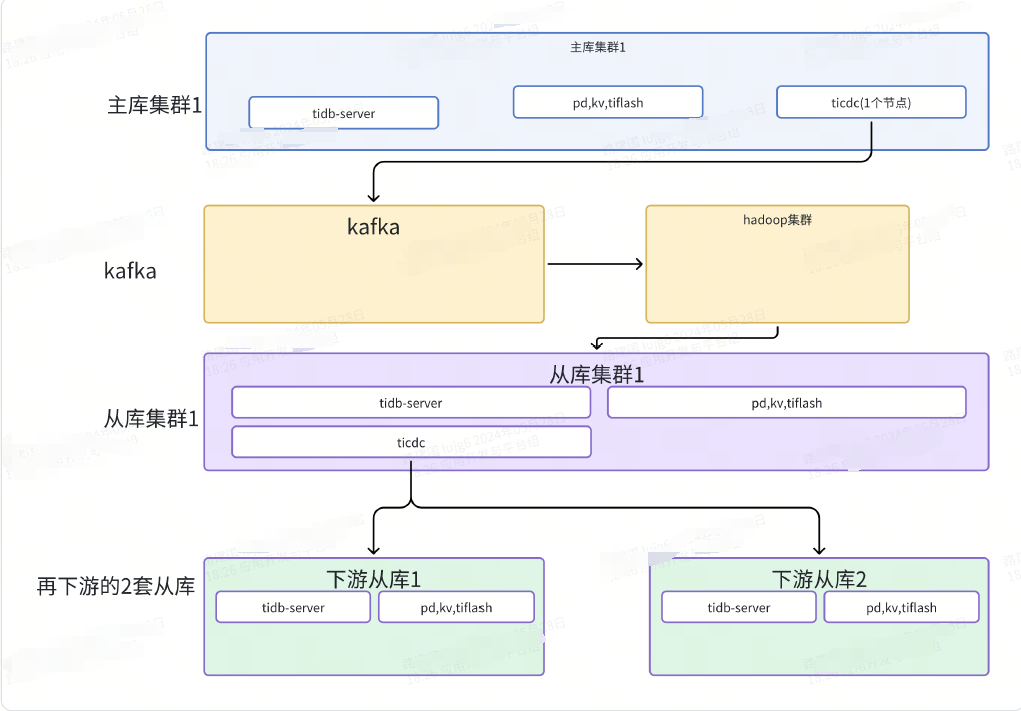
1.此图为改造前的简易的一个架构图:
图1
2.此图为改造后的简易的一个架构图:
图2
3.新扩容一个cdc节点后,发现这两个cdc节点会组成一个高可用复制。之前,在cdc1的任务列表,同步到cdc2。无法实现图2的复制需求。
有没有更好的办法,提升ticdc的到下游tidb集群之间的数据同步速度,减小数据延迟。
目前,每个单独大宽表做为一个cdc的 Changefeed任务,核心配置如下:
# 指定该 Changefeed 在 Capture Server 中内存配额的上限。对于超额使用部分,
# 会在运行中被 Go runtime 优先回收。默认值为 `1073741824`,即 1 GB。
memory-quota = 1073741824
[mounter]
# mounter 解码 KV 数据的线程数,默认值为 16
worker-num = 32
vcdog
(Vcdog)
4
我看过这个文章,是- v5.3.0 版本的 TiCDC,思路应该是相通的。不过,看他当时把work-count调整的1250,有点稍高。
vcdog
(Vcdog)
5
v6.5.0版本,对应的相关参数是这两个:
# 指定该 Changefeed 在 Capture Server 中内存配额的上限。对于超额使用部分,
# 会在运行中被 Go runtime 优先回收。默认值为 `1073741824`,即 1 GB。
# memory-quota = 1073741824
[mounter]
# mounter 解码 KV 数据的线程数,默认值为 16
# worker-num = 32
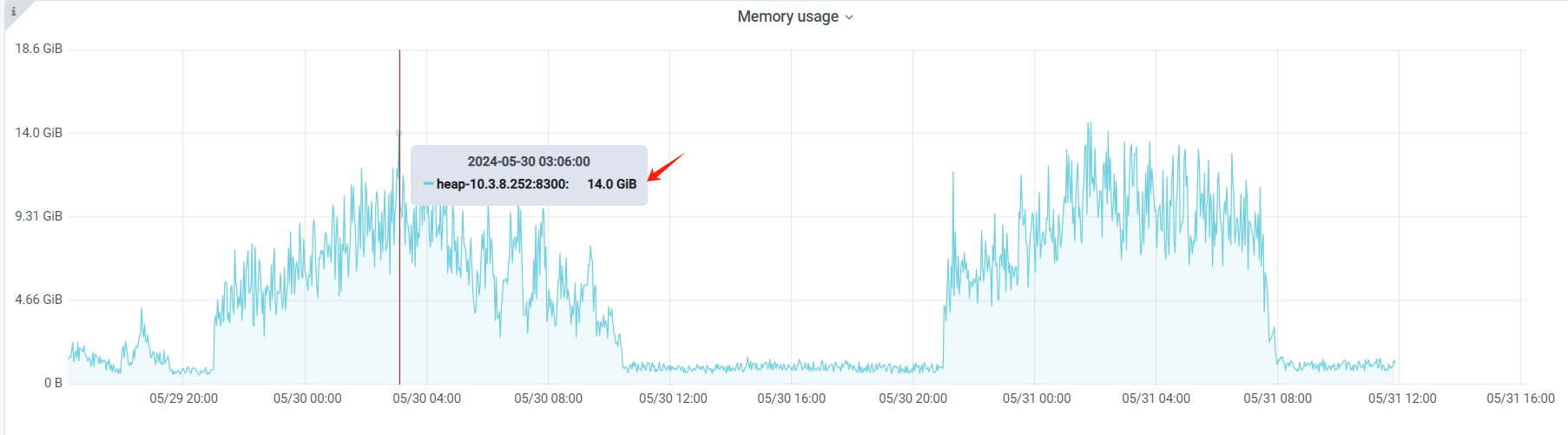
我准备也试一把,难怪监控图上,内存一直上不去。我们的生产环境,配置6张大宽表的同步任务,每个id占用1G,最多应该6G左右。但是,cdc占用内存峰值达到14G.
也可以大力出奇迹,cdc的瓶颈应该是在sorter阶段,可以多扩容几个cdc节点,把cdc同步任务拆分成多个分散压力到不同服务器。
1 个赞
vcdog
(Vcdog)
8
会不会跟我的几套集群的版本有关,
1、上游主库集群版本为:v6.5.0版本
2、下游2套从库集群的版本为:v6.1.5和v7.5.0版本
vcdog
(Vcdog)
9
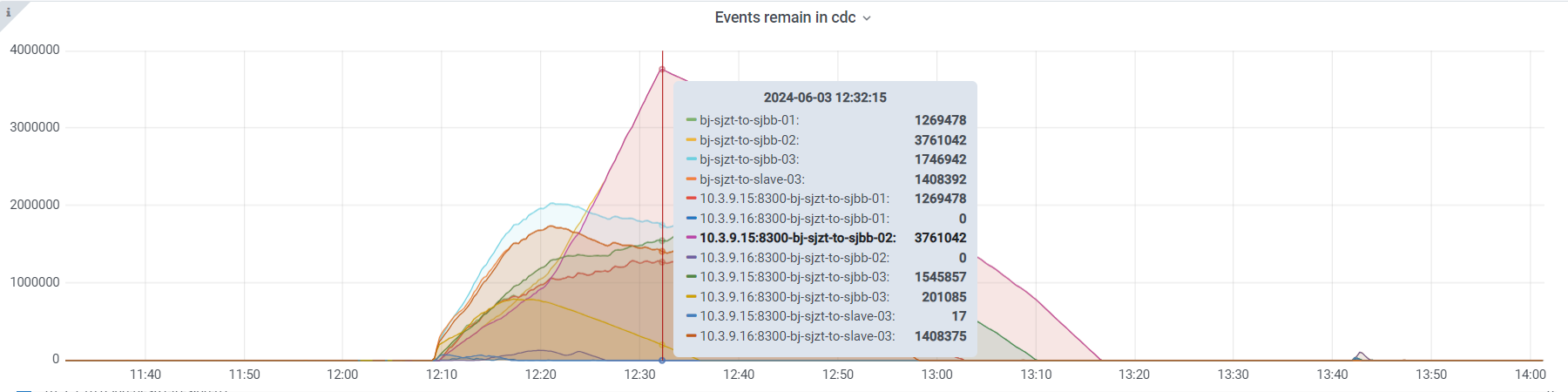
从监控图上看到的处理速度,大概在3000/秒左右,远低于cdc到kafka的36000/秒。理论上cdc到下游tidb集群的速度大概是多少,才属于正常?