【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.5.0
【复现路径】
【遇到的问题:问题现象及影响】
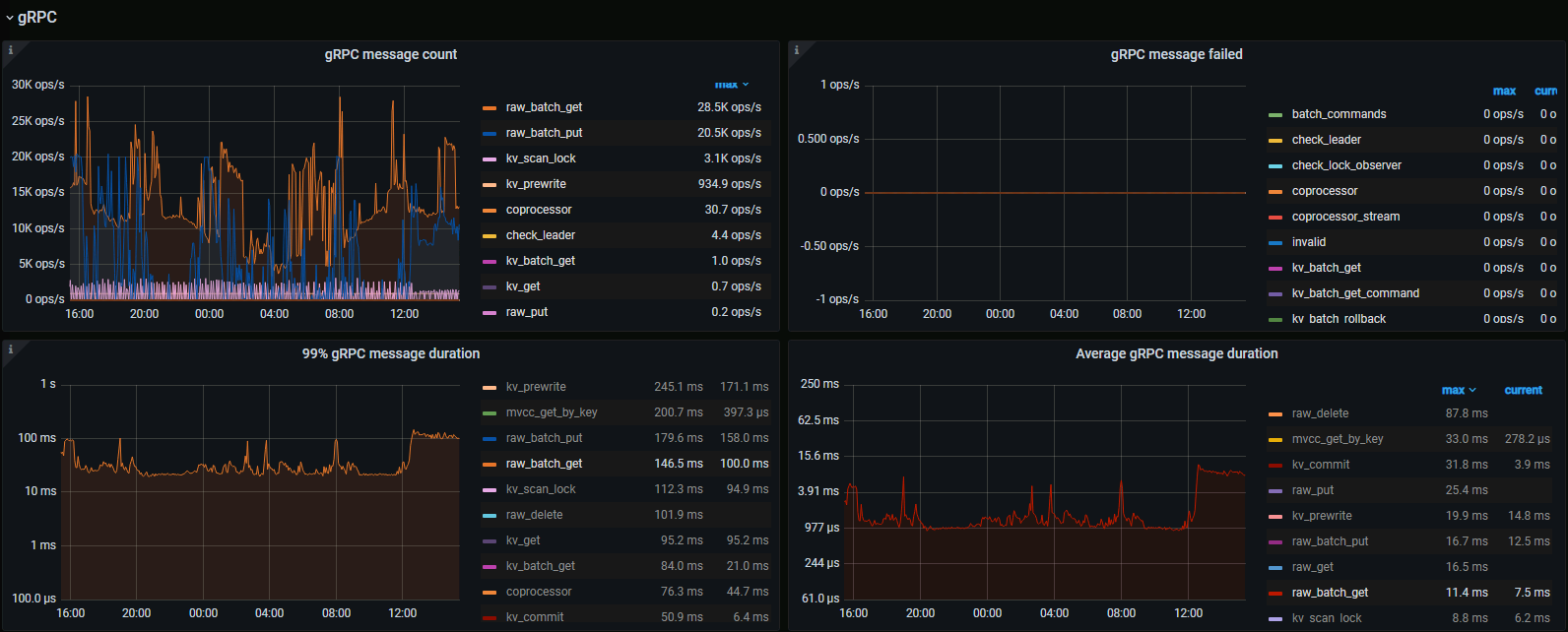
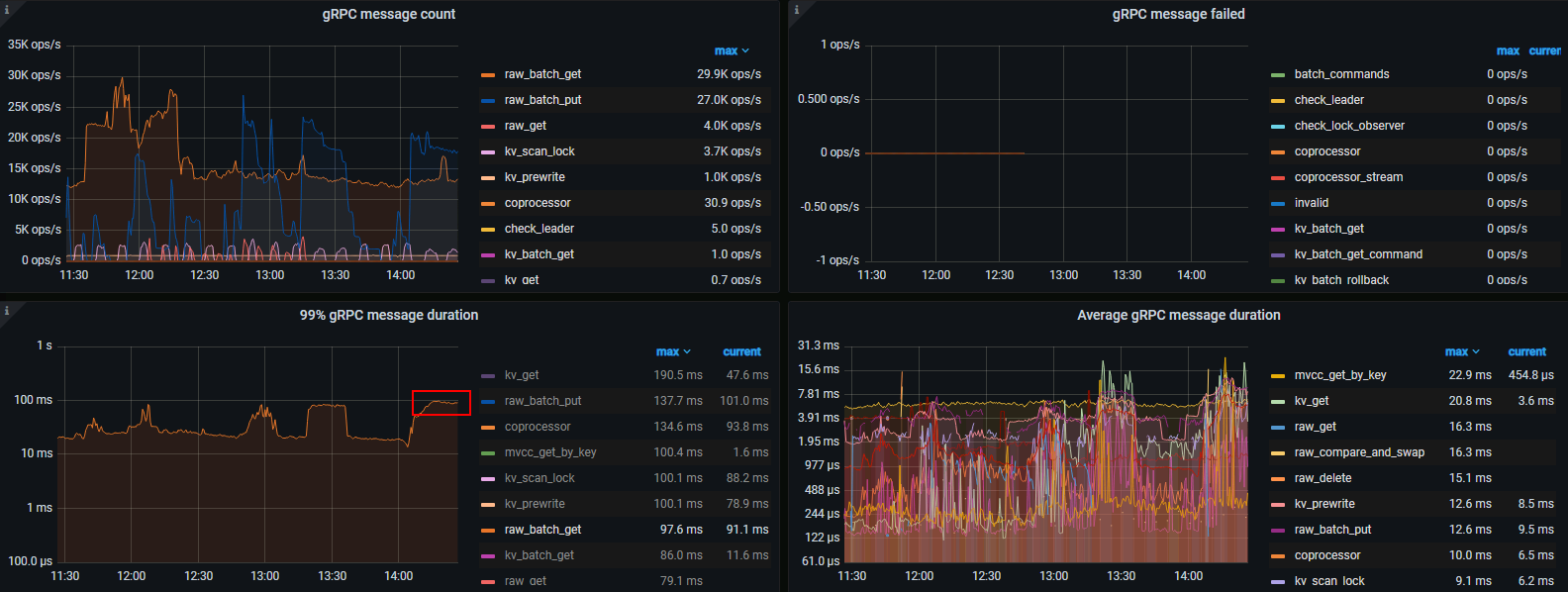
raw_batch_get 10个key,average 2ms以内,99%大于100ms。CPU、IO无压力瓶颈,发现snapshot耗时较多。怀疑是LSM扫描SST文件导致长尾效应,能否调参优化?
【资源配置】
磁盘使用的是nvme ssd、ali PL3性能上没问题
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.5.0
【复现路径】
【遇到的问题:问题现象及影响】
raw_batch_get 10个key,average 2ms以内,99%大于100ms。CPU、IO无压力瓶颈,发现snapshot耗时较多。怀疑是LSM扫描SST文件导致长尾效应,能否调参优化?
【资源配置】
https://docs.pingcap.com/zh/tidb/stable/tune-tikv-thread-performance#tikv-的只读请求 可以看下这部分。看看共享线程池是否打开了,CPU 给了多少。grpc cpu 有没有成为瓶颈。可以将一些默认 cpu 的配置调高一些看下效果。
我们是java client直接使用tikv,用的是raw_batch_put和raw_batch_get,并没有使用到tidb role。
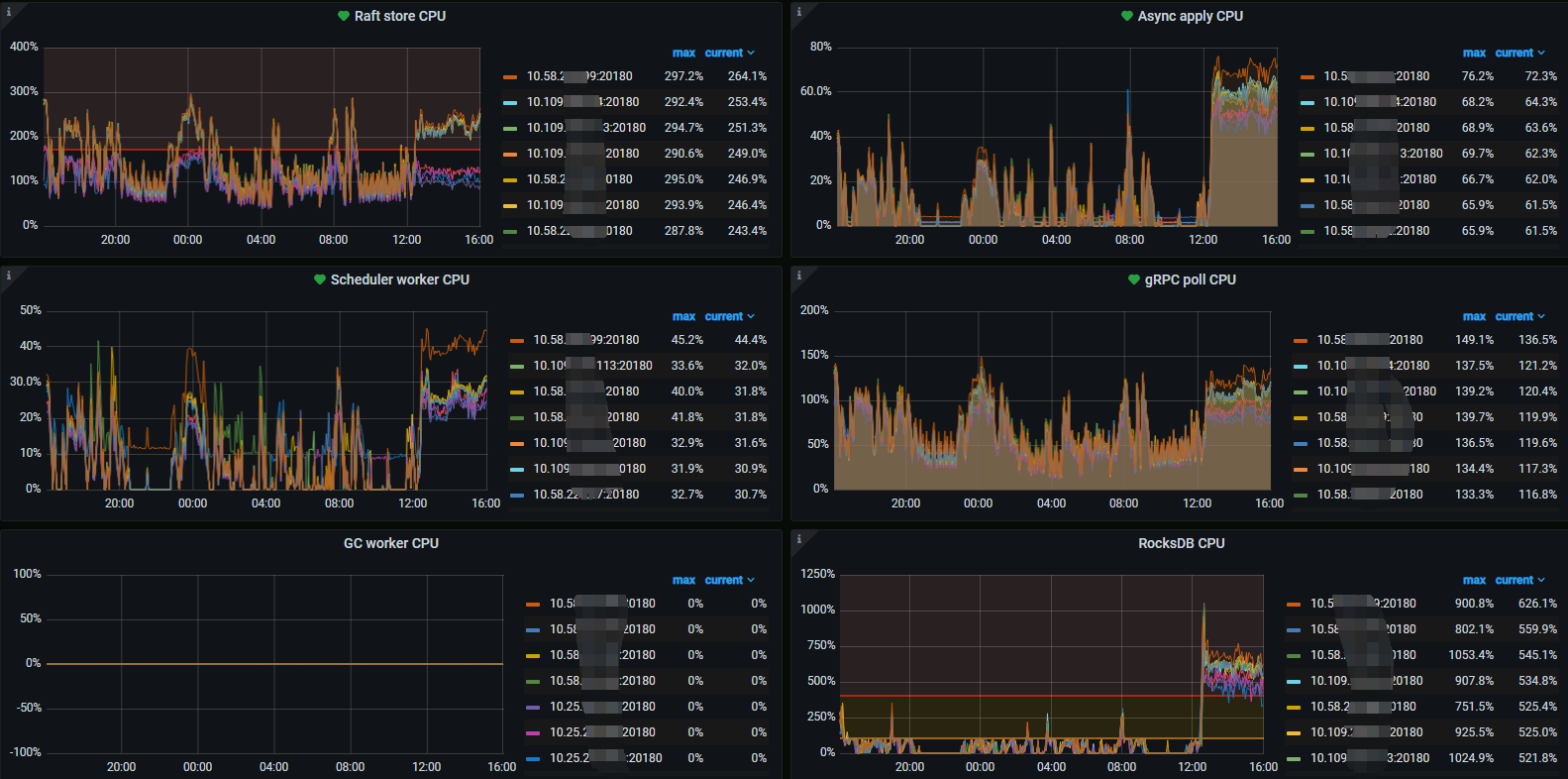
线程池都调得比较大,CPU才40%左右,还没有达到80%,99% duration确上升到100ms+。
tikv:
raftstore.apply-pool-size: 4
raftstore.raft-base-tick-interval: 2s
raftstore.store-pool-size: 8
resolved-ts.advance-ts-interval: 20s
rocksdb.defaultcf.soft-pending-compaction-bytes-limit: 256G
rocksdb.max-background-jobs: 16
rocksdb.max-sub-compactions: 8
rocksdb.wal-recovery-mode: 0
server.grpc-concurrency: 8
storage.api-version: 2
storage.enable-ttl: true
storage.scheduler-pending-write-threshold: 200MB
storage.scheduler-worker-pool-size: 4
本身压力越大,duration 越高是预期的。不是 CPU 没有瓶颈,加压 duration 是不变的。
你看压力大的时候 raft store cpu 看起来超了 200%。你看看这个是否有帮助:
可以调整下 tikv 的拓扑,服务器开启 numa,然后按照 cpu node 绑核,比如有两个 node,可以 tikv 部署两个实例,每一个绑定一个 node。这样 duration 应该有一定的优化。
region比较多,尝试调大region size,减少raft消耗。
set config tikv coprocessor.region-max-size=‘384MB’;
set config tikv coprocessor.region-split-size=‘256MB’;
我感觉是你这个配置小了。
storage.scheduler-worker-pool-size: 4
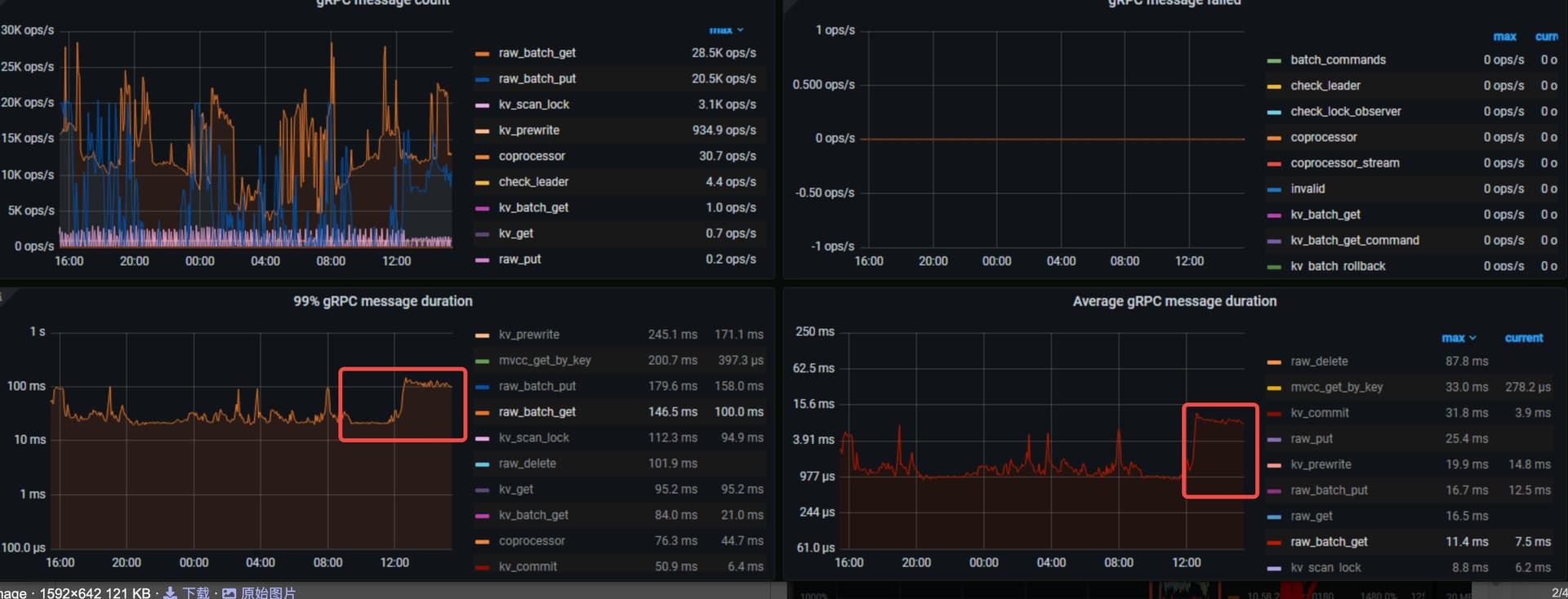
如你所说现在是snapshot耗时长。
https://docs.pingcap.com/zh/tidb/stable/dashboard-diagnostics-report#time-consumed-by-each-component
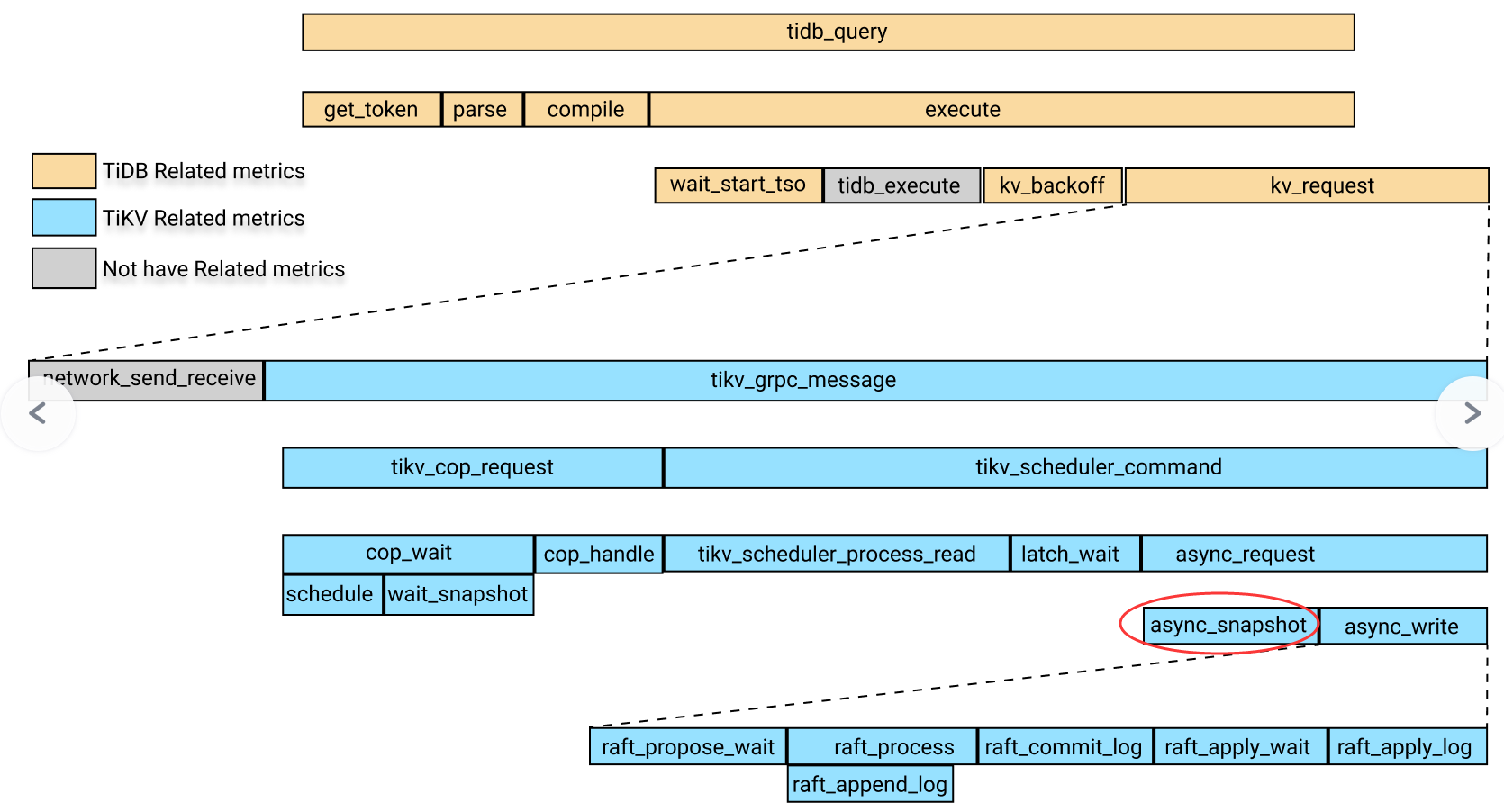
这个页面上可以看到如下图:
红圈处就是snapshot.是属于scheduler_command下面的。
而且
https://docs.pingcap.com/zh/tidb/stable/dashboard-diagnostics-report#time-consumed-by-each-component
scheduler-worker-pool-size
- Scheduler 线程池中线程的数量。Scheduler 线程主要负责写入之前的事务一致性检查工作。如果 CPU 核心数量大于等于 16,默认为 8;否则默认为 4。调整 scheduler 线程池的大小时,请参考 TiKV 线程池调优。
- 默认值:4
- 可调整范围:
[1, MAX(4, CPU)]。其中,MAX(4, CPU)表示:如果 CPU 核心数量小于4,取4;如果 CPU 核心数量大于4,则取 CPU 核心数量。
虽然这个推荐配置就是4.但我看你上面几个线程池设置的都比较大胆,也许你的cpu资源比较多。是否可以调的比4大一些,看看效果如何?
之前storage.scheduler-worker-pool-size配置很大,后来发现该线程很闲,为了避免过多上下文切换,给改成了4。
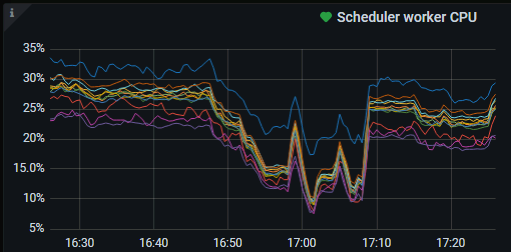
感谢猫的关注,如我下图所示,慢在了snapshot(Replicate Raft Log + Propose Wait + xxx )
raw_get、raw_batch_get在源码中都会get snapshot,这个get snapshot能否提速?
let snapshot =
Self::with_tls_engine(|engine| Self::snapshot(engine, snap_ctx)).await?;
let buckets = snapshot.ext().get_buckets();
let store = RawStore::new(snapshot, api_version);
https://docs.pingcap.com/zh/tidb/stable/latency-breakdown#tikv-快照
tikv_storage_engine_async_request_duration_seconds{type=“snapshot”} =
tikv_coprocessor_request_wait_seconds{type=“snapshot”} =
tikv_raftstore_request_wait_time_duration_secs +
tikv_raftstore_commit_log_duration_seconds +
get snapshot from rocksdb duration
现在是
tikv_storage_engine_async_request_duration_second(63.1ms)
=tikv_raftstore_request_wait_time_duration_secs(3.68ms)+
tikv_raftstore_commit_log_duration_seconds(9.52ms)+
get snapshot from rocksdb duration
虽然文档里面的结论是
从 RocksDB 获取快照通常是一个快速操作,因此
get snapshot from rocksdb duration的耗时可以被忽略。
但是根据这个监控图,我们好像只能得出一个结论。那就是get snapshot from rocksdb duration就有50ms左右。
看看是否有大神,可以想到办法。我现在没有太好的思路了。
依据目前提供的信息,raw_batch_get 的长尾延迟主要是 raw_batch_put 引起 CPU 使用率上升导致的。其中:
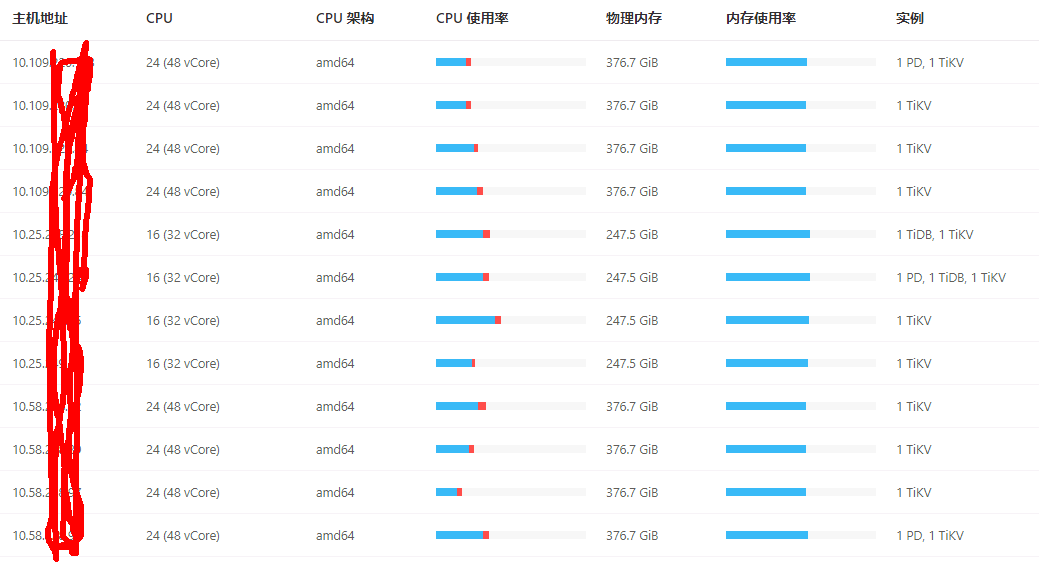
按照经验,如果需要保持长尾延迟稳定,CPU 的使用应当控制在 40% 以下。此外,vCore 实际上并不能达到物理 core 的 2 倍性能,通常只有 1.5 倍左右,并且由于同一个物理 core 的 vCore 间共享寄存器、cache 等硬件,提高吞吐的同时长尾延迟会增加(参考 https://www.sciencedirect.com/science/article/pii/S0167739X22000334?via%3Dihub )。因此,对于 24 (48 vCore) 机型,有条件的话建议 CPU 利用率控制在 1200% 以下,甚至关闭 hyper threading
存在异构混合部署,长尾延迟可能会集中在 16 (32 vCore) 机型上,监控上看到其中一台 CPU 使用率已超过 1300%。建议确认一下长尾延迟是否集中在少量机器
监控中观察到的 snapshot 流程中涉及 read index(见 TiKV 源码解析系列文章(十九)read index 和 local read 情景分析 | PingCAP ),主要在 Raftstore 中处理,对于 CPU 使用率和网络延迟敏感
增加 region size 有可能对于长尾延迟是负面影响,因为同一个 region 内的 Raft 只能串行处理,数据量增大反而增加长尾延迟
建议:
raw_batch_put 削峰,CPU 使用率(以物理 core 计算)控制在 50% 以下。此外,有条件的话 raw_batch_put 尽量打散写入,同一时间不要集中在少量 region
TiKV 独立部署并采用相同机型
建议调整机型配置,目前机型的 CPU 相比内存太小。TiKV 一般建议 CPU : Memory = 1 : 4。当采用 NVMe 时,大容量 block cache 的效果不会很显著。相近成本下如果调整为 32C/128GB,相信长尾延迟会有改善。
解决了吗?这个如何优化?博主