【 TiDB 使用环境】生产环境
【 TiDB 版本】
v5.4.3 → v7.1.5
【复现路径】做过哪些操作出现的问题
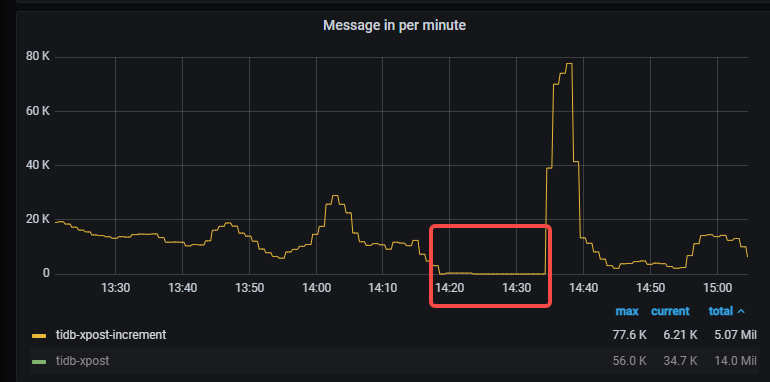
升级集群版本v5.4.3 → v7.1.5,升级过程中cdc数据中断15分钟。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
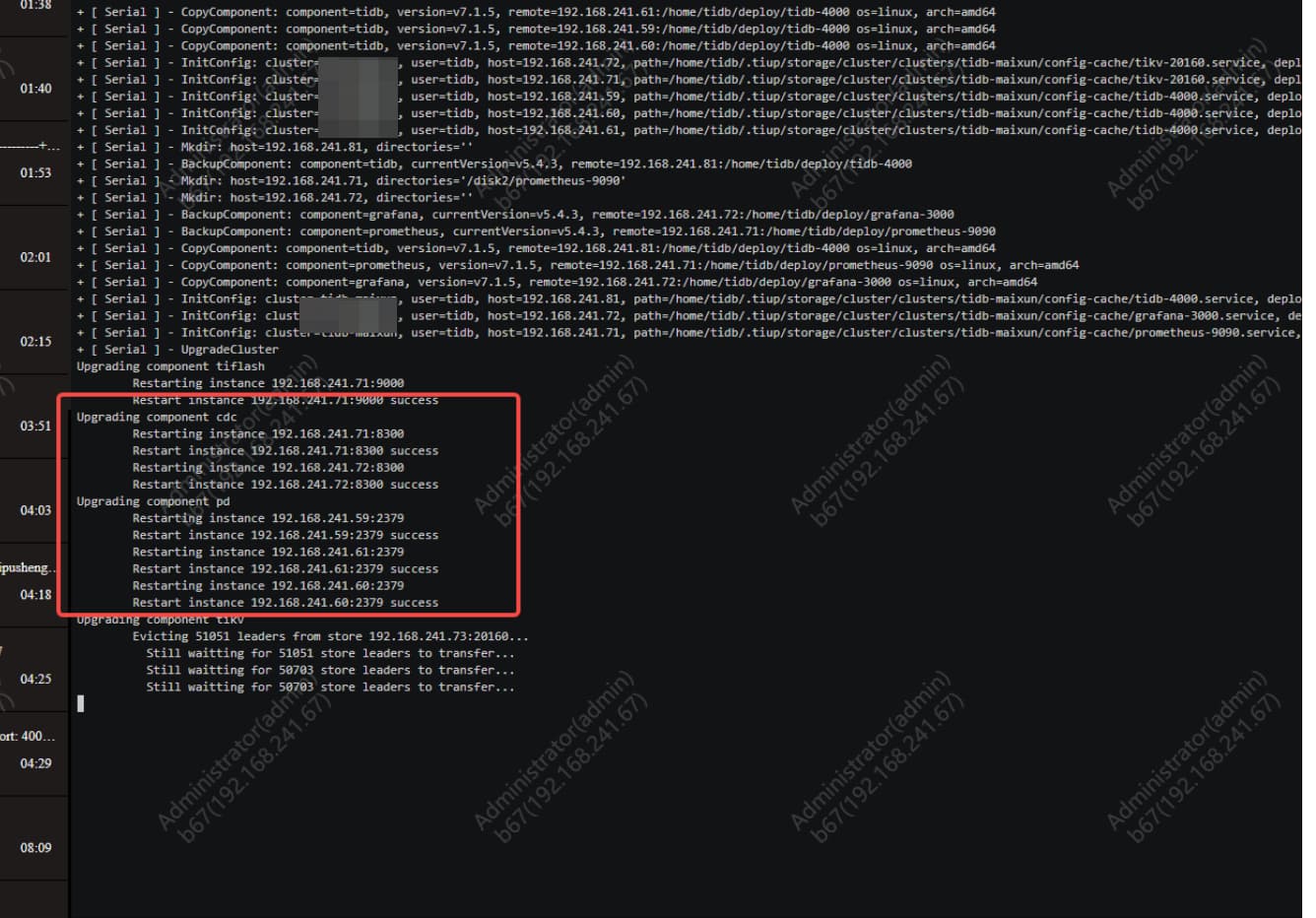
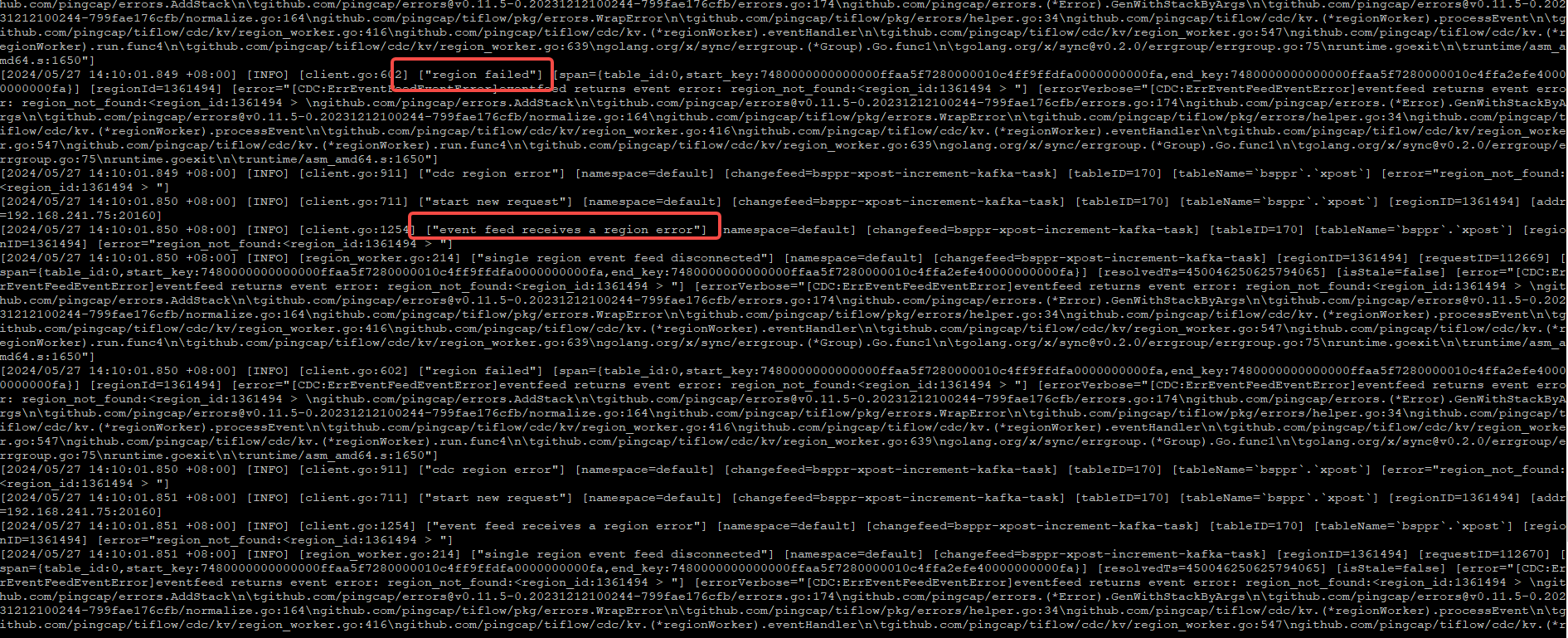
cdc日志开始开始报错
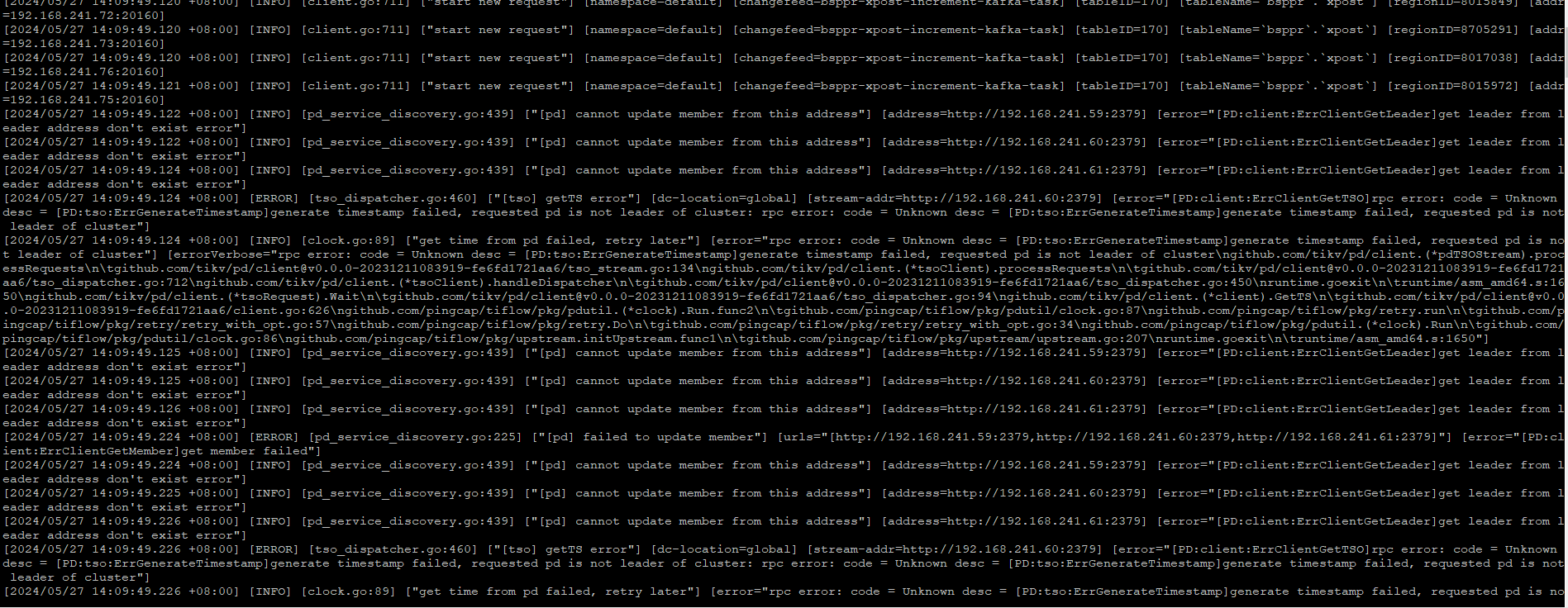
受影响的时间范围好像都是这种日志 ,太大了就不再上传
【 TiDB 使用环境】生产环境
【 TiDB 版本】
v5.4.3 → v7.1.5
【复现路径】做过哪些操作出现的问题
升级集群版本v5.4.3 → v7.1.5,升级过程中cdc数据中断15分钟。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
cdc日志开始开始报错
受影响的时间范围好像都是这种日志 ,太大了就不再上传
第一个日志应该是 pd leader 切换,后续的 info 可能和 tikv 滚动 leader 切换有关系。
cdc 要扫 tikv raft 日志的,region leader 切换,tikv 重启卡 cdc 任务我理解也合理。
leader不是正常下线主动切换的吗?我理解的pd不是应该知道当前的leader信息吗,怎么还一直报后面的错误,
还有即使是leader找不到,也总会有找到的吧,问题状态是cdc数据直接为0,这不正常吧?
tikv leader 主动切换也不代表 pd 信息是最新的,默认 tikv 应该是 1min 上报一次 leader 信息,遇到错误 让 tikv 主动报一次。
cdc 数据直接为 0 怎么理解?是不是当时用 cdc cli 没有更新导致查询结果有问题。。。。 实际上可能在跑?
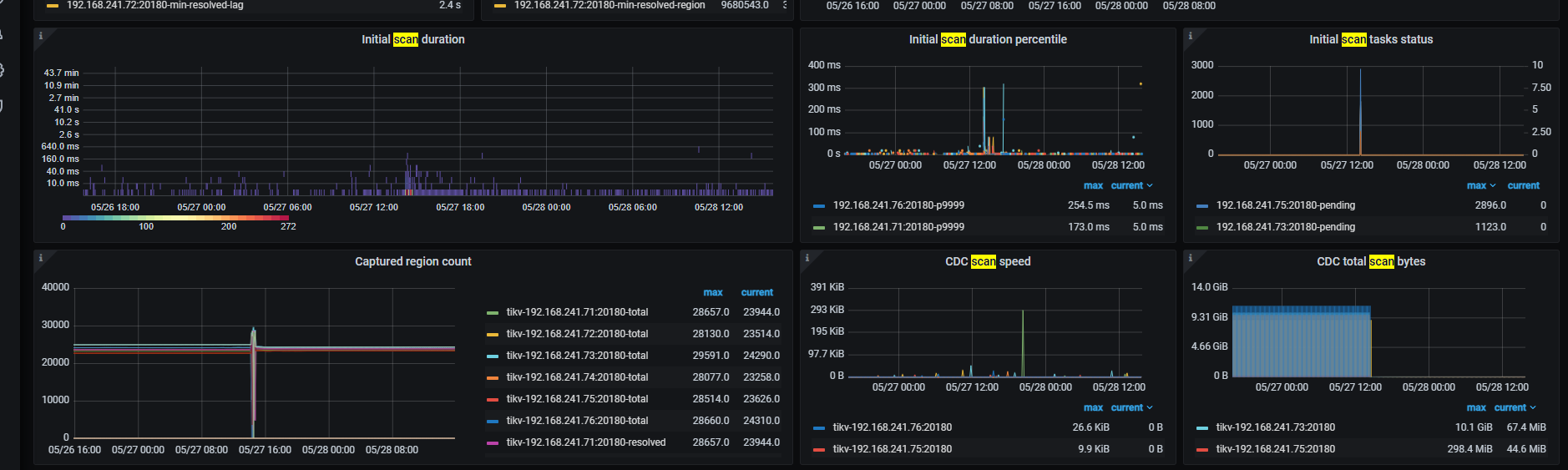
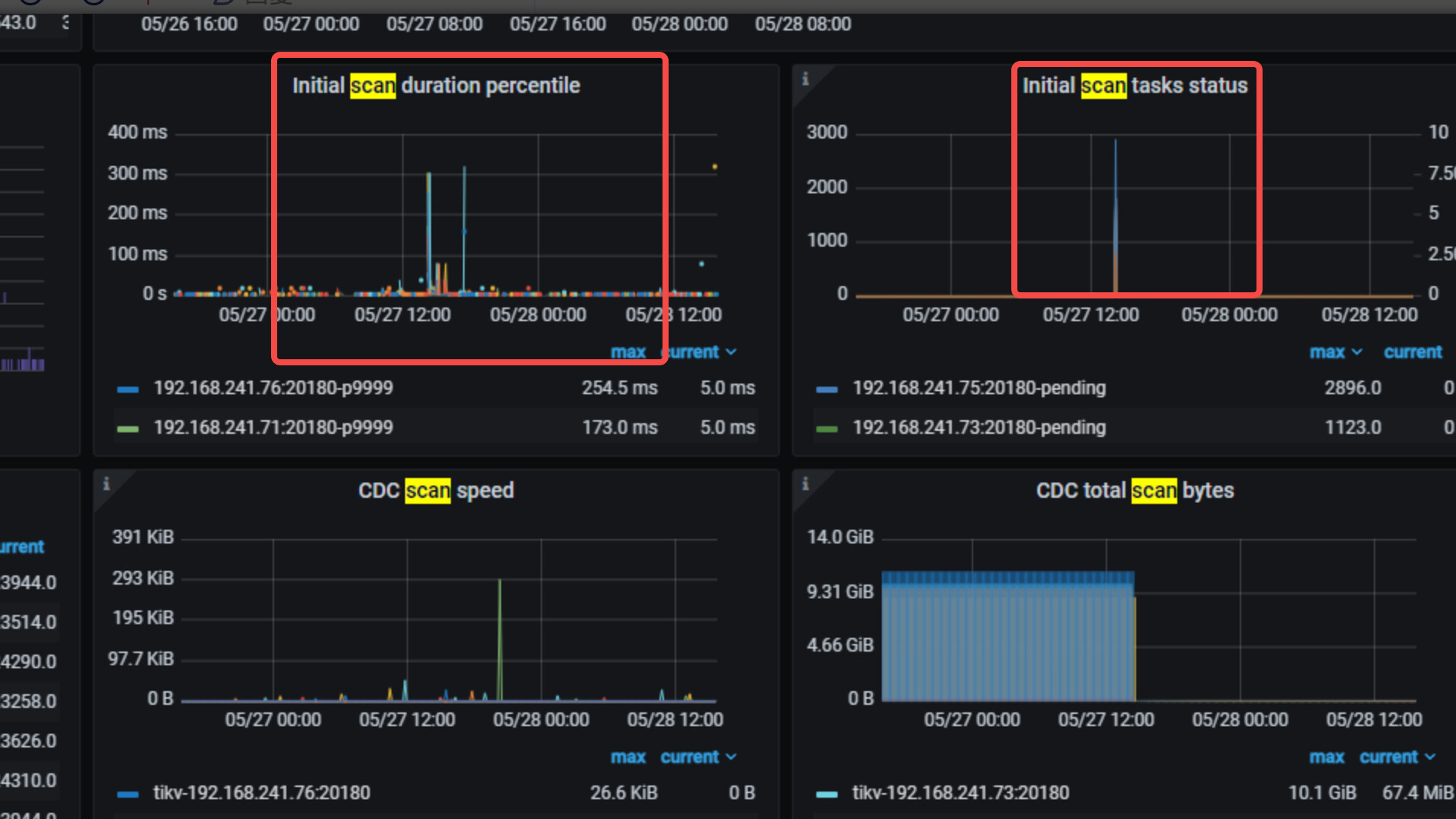
Grafana → CDC的dashboard → TiKV的Row → 三個Initial scan的panel
如果是 scan 那麼在 14:35 這三個panel會有反應
发生 scan 的话会卡就预期了。
在线升级从这监控看是符合预期的。
大佬威武 ![]()
![]()
![]()
大佬威武
向大佬学习~!
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。