【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】4.0.10
【复现路径】
【遇到的问题:问题现象及影响】
tikv 启动异常,报错如下:
[2024/05/27 16:07:51.797 +08:00] [INFO] [store.rs:925] ["region is applying snapshot"] [store_id=4] [region="id: 25193 start_key: 7480000000000000FF365F698000000000FF0000040380000000FF0000000004000000FF006082F5FF038000FF000004EEBEC50000FD end_key: 7480000000000000FF365F698000000000FF0000040380000000FF0000000004000000FF0060830014038000FF00000523062B0000FD region_epoch { conf_ver: 1325 version: 522 } peers { id: 12589504 store_id: 5 } peers { id: 12634220 store_id: 4 } peers { id: 13778883 store_id: 2134051 }"]
[2024/05/27 16:07:51.797 +08:00] [INFO] [peer.rs:180] ["create peer"] [peer_id=12634220] [region_id=25193]
[2024/05/27 16:07:51.799 +08:00] [FATAL] [server.rs:590] ["failed to start node: Other(\"[components/raftstore/src/store/peer_storage.rs:504]: [region 25193] entry at 33014 doesn\\'t exist, may lose data.\")"]
region 信息:
» region 25193
{
"id": 25193,
"start_key": "7480000000000000FF365F698000000000FF0000040380000000FF0000000004000000FF006082F5FF038000FF000004EEBEC50000FD",
"end_key": "7480000000000000FF365F698000000000FF0000040380000000FF0000000004000000FF0060830014038000FF00000523062B0000FD",
"epoch": {
"conf_ver": 1338,
"version": 522
},
"peers": [
{
"id": 13778883,
"store_id": 2134051
},
{
"id": 17455504,
"store_id": 5
}
],
"leader": {
"id": 13778883,
"store_id": 2134051
},
"written_bytes": 0,
"read_bytes": 0,
"written_keys": 0,
"read_keys": 0,
"approximate_size": 47,
"approximate_keys": 661611
}
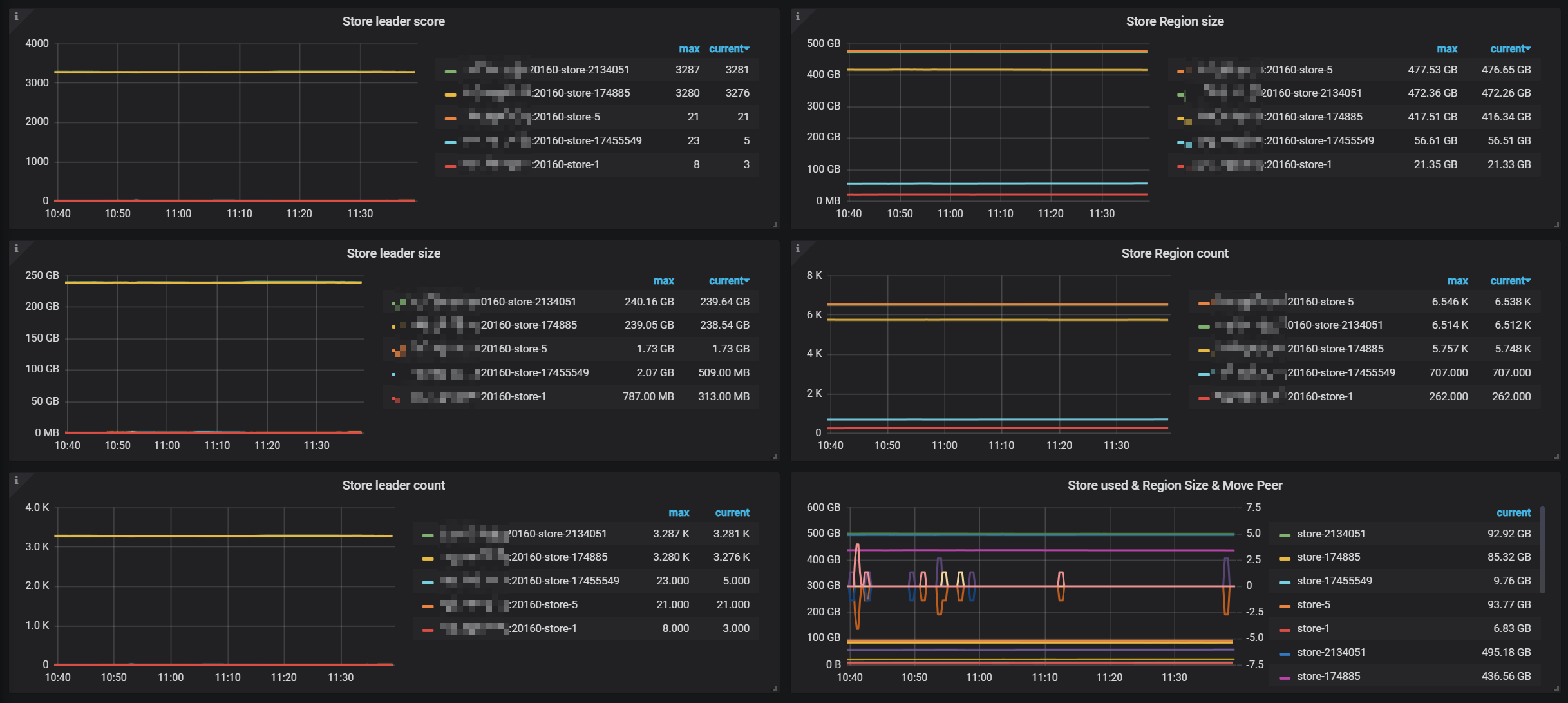
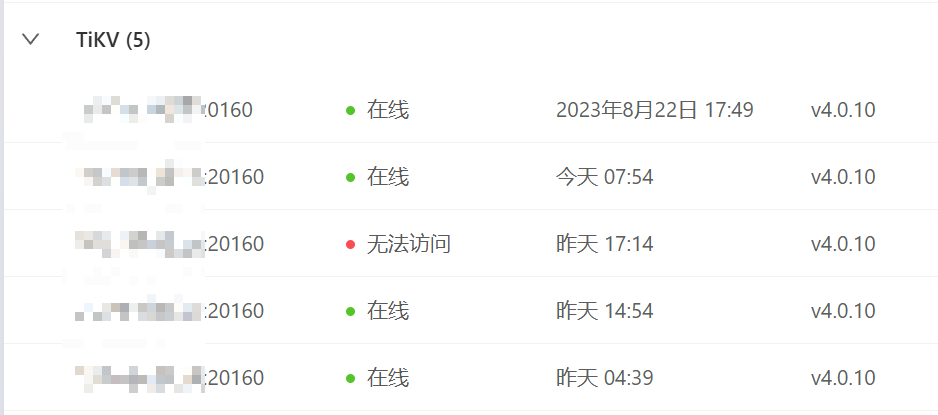
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
查看文档 TiKV Control 使用说明 | PingCAP 归档文档站
其中 remove-peer 是需要把全部的 store_id 给处理掉吗
其次在故障 tikv 机器上面执行 tikv-ctl --db /path/to/tikv/db tombstone -p 127.0.0.1:2379 -r <region_id> 有如下报错
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: RocksDb("IO error: No such file or directoryWhile opening a file for sequentially reading: /cloud/data5/tikv-20160/CURRENT: No such file or directory")', src/libcore/result.rs:1188:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace.
Error: exit status 101
Error: run `/root/.tiup/components/ctl/v4.0.10/ctl` (wd:/root/.tiup/data/UDxZpT0) failed: exit status 1
查看正常节点都没有 CURRENT 相关目录