【 TiDB 使用环境】测试
【 TiDB 版本】v7.5.1
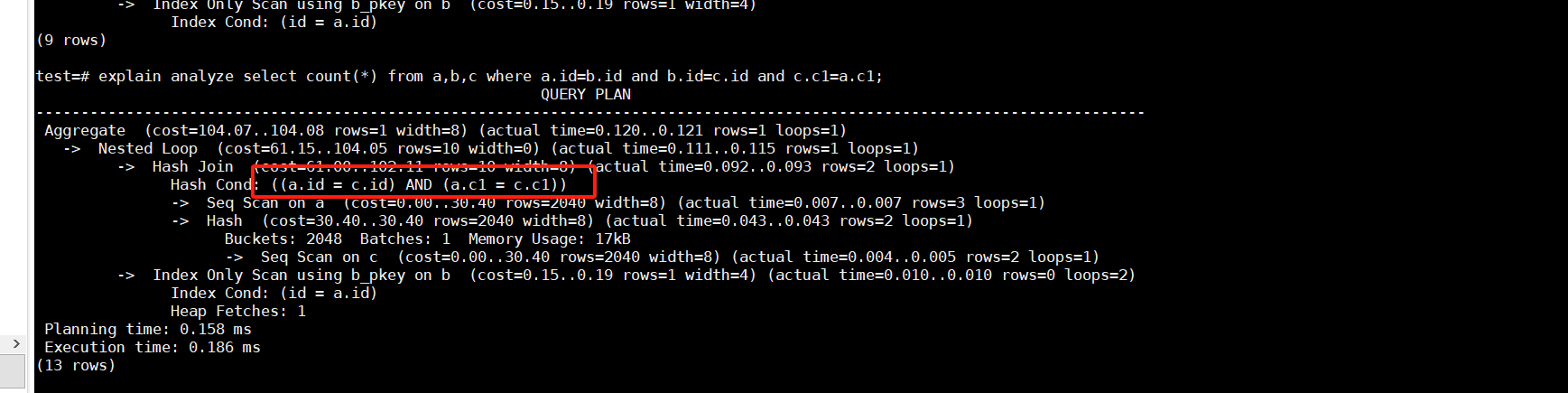
tpch的Q5执行效率较慢,其中有一点是没有对等值关联条件做转换,帖子:因优化器问题导致TPCH的Q5语句执行过慢
但是上面这个帖子内容较多,没有聚焦该问题,因此这里简化测试该问题。
创建相关表结构:
drop table if exists a;
drop table if exists b;
drop table if exists c;
create table a(id int,c1 int,c2 int,primary key (id));
create table b(id int,c1 int,c2 int,primary key (id));
create table c(id int,c1 int,c2 int,primary key (id));
insert into a values (1,1,1),(2,2,2),(3,3,3);
insert into b values (1,1,1),(10,10,10),(11,11,11),(12,12,12);
insert into c values (1,1,1),(2,2,2);
analyze table a,b,c with 1 samplerate;
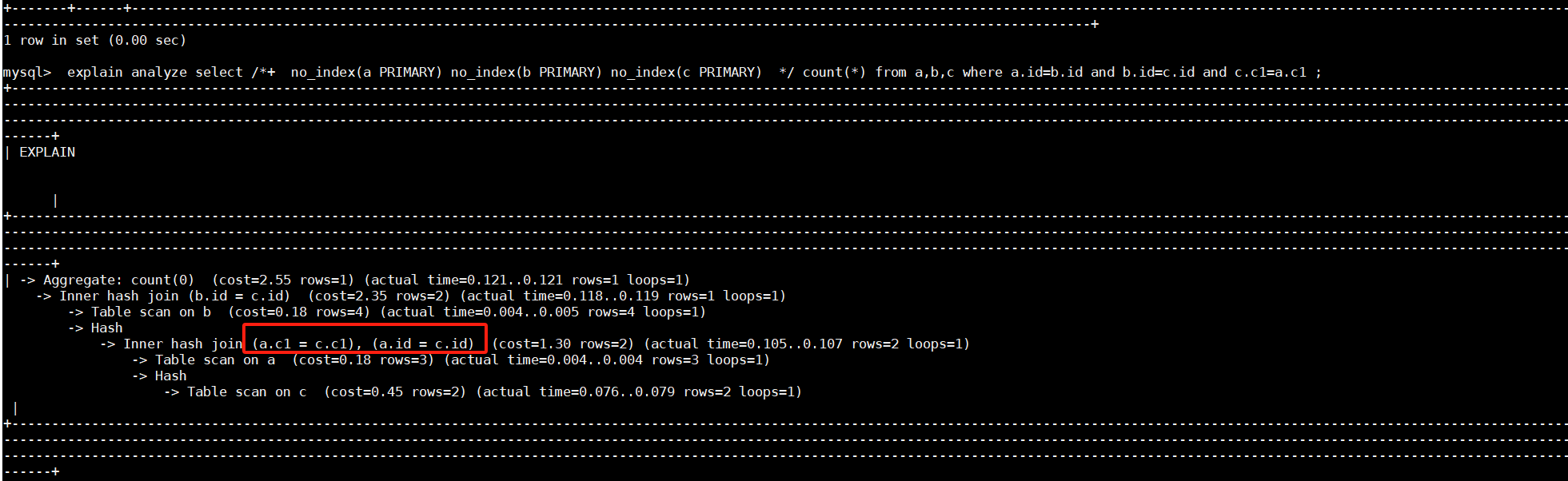
查看SQL语句:select count(*) from a,b,c where a.id=b.id and b.id=c.id and c.c1=a.c1 的执行计划:
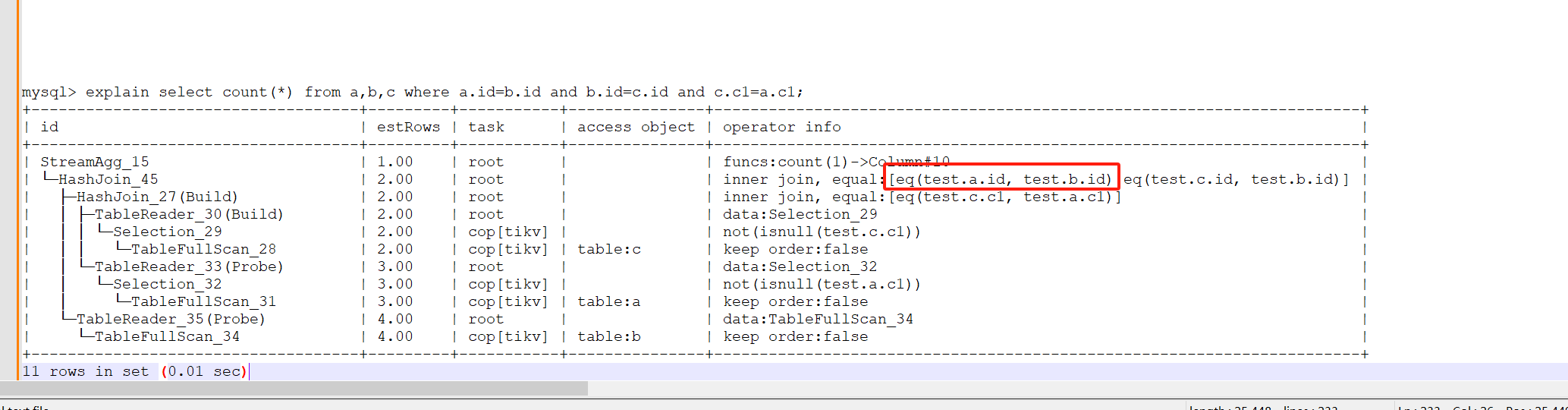
mysql> explain select count(*) from a,b,c where a.id=b.id and b.id=c.id and c.c1=a.c1;
+------------------------------------+---------+-----------+---------------+-----------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+------------------------------------+---------+-----------+---------------+-----------------------------------------------------------------------+
| StreamAgg_15 | 1.00 | root | | funcs:count(1)->Column#10 |
| └─HashJoin_45 | 2.00 | root | | inner join, equal:[eq(test.a.id, test.b.id) eq(test.c.id, test.b.id)] |
| ├─HashJoin_27(Build) | 2.00 | root | | inner join, equal:[eq(test.c.c1, test.a.c1)] |
| │ ├─TableReader_30(Build) | 2.00 | root | | data:Selection_29 |
| │ │ └─Selection_29 | 2.00 | cop[tikv] | | not(isnull(test.c.c1)) |
| │ │ └─TableFullScan_28 | 2.00 | cop[tikv] | table:c | keep order:false |
| │ └─TableReader_33(Probe) | 3.00 | root | | data:Selection_32 |
| │ └─Selection_32 | 3.00 | cop[tikv] | | not(isnull(test.a.c1)) |
| │ └─TableFullScan_31 | 3.00 | cop[tikv] | table:a | keep order:false |
| └─TableReader_35(Probe) | 4.00 | root | | data:TableFullScan_34 |
| └─TableFullScan_34 | 4.00 | cop[tikv] | table:b | keep order:false |
+------------------------------------+---------+-----------+---------------+-----------------------------------------------------------------------+
11 rows in set (0.01 sec)
可以看到优化器优先选择a join c 最后和b关联,但是a join c的condition条件只有:equal:[eq(test.c.c1, test.a.c1) 并没有感知a.id=b.id and b.id=c.id推出a.id=c.id,因此没有提前做a.id=c.id的过滤,手工优化为:
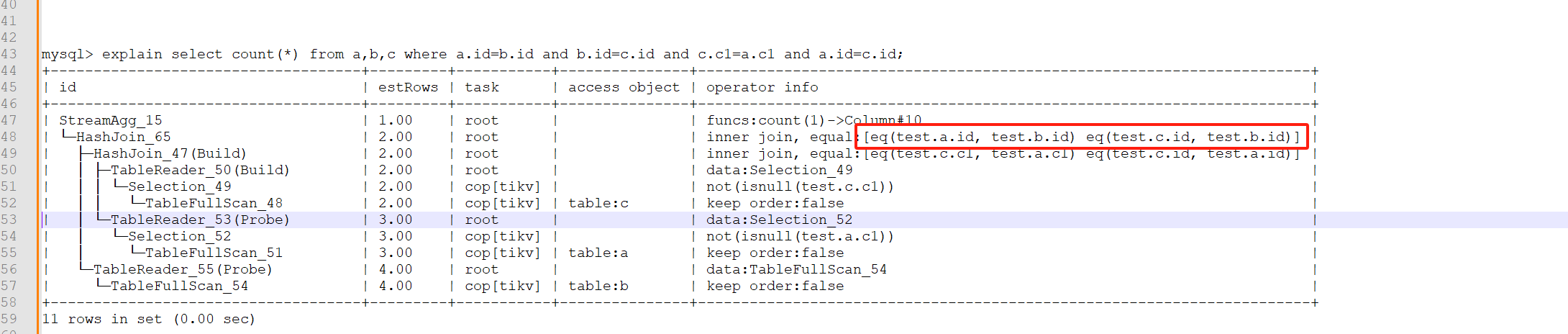
mysql> explain select count(*) from a,b,c where a.id=b.id and b.id=c.id and c.c1=a.c1 and a.id=c.id;
+------------------------------------+---------+-----------+---------------+-----------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+------------------------------------+---------+-----------+---------------+-----------------------------------------------------------------------+
| StreamAgg_15 | 1.00 | root | | funcs:count(1)->Column#10 |
| └─HashJoin_65 | 2.00 | root | | inner join, equal:[eq(test.a.id, test.b.id) eq(test.c.id, test.b.id)] |
| ├─HashJoin_47(Build) | 2.00 | root | | inner join, equal:[eq(test.c.c1, test.a.c1) eq(test.c.id, test.a.id)] |
| │ ├─TableReader_50(Build) | 2.00 | root | | data:Selection_49 |
| │ │ └─Selection_49 | 2.00 | cop[tikv] | | not(isnull(test.c.c1)) |
| │ │ └─TableFullScan_48 | 2.00 | cop[tikv] | table:c | keep order:false |
| │ └─TableReader_53(Probe) | 3.00 | root | | data:Selection_52 |
| │ └─Selection_52 | 3.00 | cop[tikv] | | not(isnull(test.a.c1)) |
| │ └─TableFullScan_51 | 3.00 | cop[tikv] | table:a | keep order:false |
| └─TableReader_55(Probe) | 4.00 | root | | data:TableFullScan_54 |
| └─TableFullScan_54 | 4.00 | cop[tikv] | table:b | keep order:false |
+------------------------------------+---------+-----------+---------------+-----------------------------------------------------------------------+
11 rows in set (0.00 sec)
在复杂SQL语句中,人工做这种变换较为困难,希望优化器可以做下关联字段等值转换方面的优化。