【 TiDB 使用环境】开发环境
【 TiDB 版本】v7.1.0
【复现路径】机房异常断电,服务状态异常
【遇到的问题:问题现象及影响】
PD状态异常
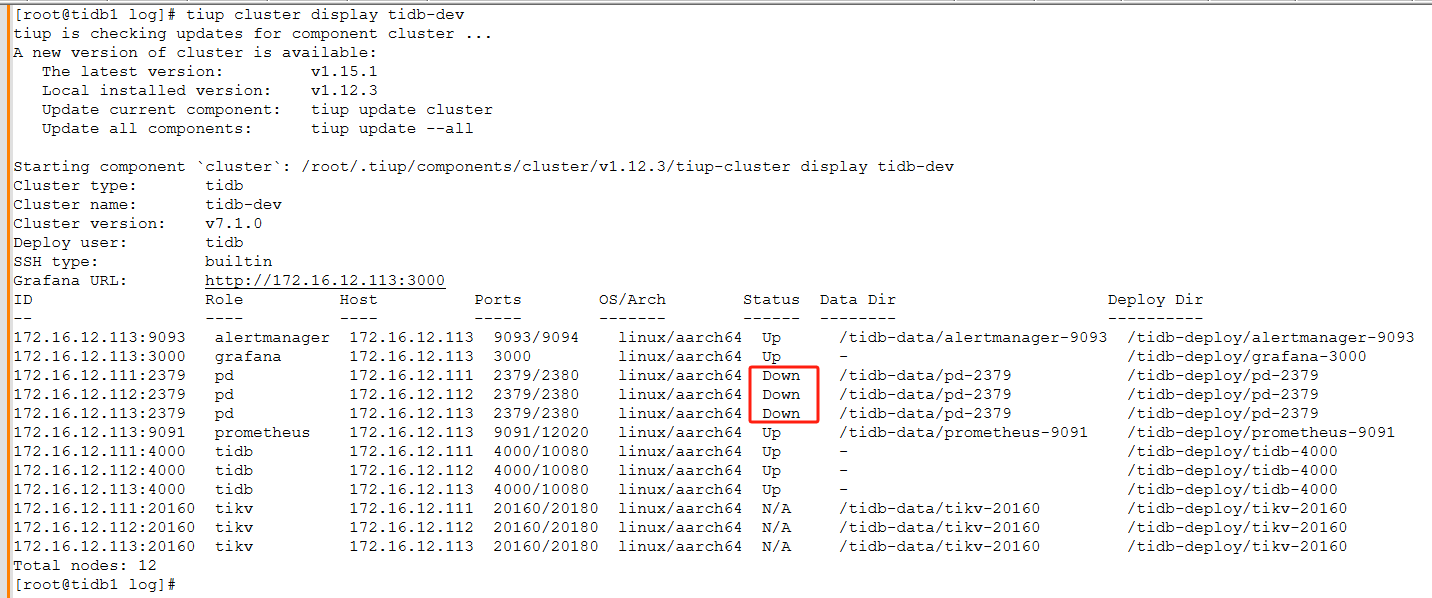
tiup日志:
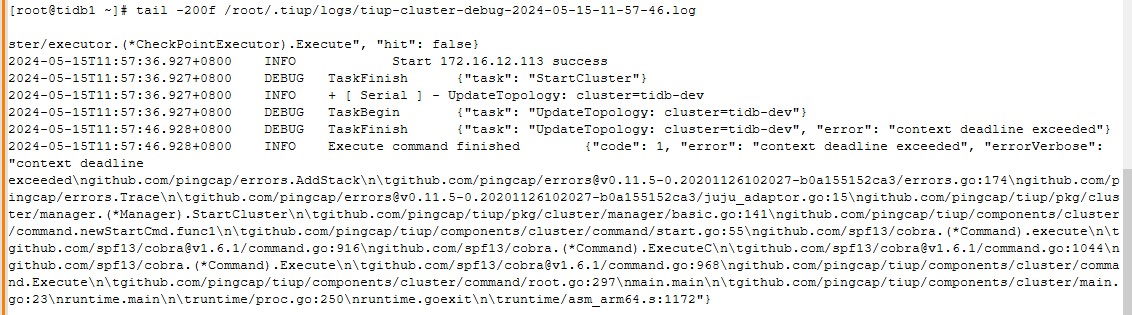
pd日志:

Tikv日志:
[2024/05/15 12:41:59.671 +08:00] [INFO] [] [“subchannel 0xffe8e05c5800 {address=ipv4:172.16.12.113:2379, args=grpc.client_channel_factory=0xfffd00510cf8, grpc.default_authority=172.16.12.113:2379, grpc.initial_reconnect_backoff_ms=1000, grpc.internal.subchannel_pool=0xfffd00201a40, grpc.keepalive_time_ms=10000, grpc.keepalive_timeout_ms=3000, grpc.max_receive_message_length=-1, grpc.max_reconnect_backoff_ms=5000, grpc.max_send_message_length=-1, grpc.primary_user_agent=grpc-rust/0.10.4, grpc.resource_quota=0xfffd000efd80, grpc.server_uri=dns:///172.16.12.113:2379}: Retry in 1000 milliseconds”]
[2024/05/15 12:41:59.671 +08:00] [ERROR] [util.rs:682] [“connect failed”] [error=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "failed to connect to all addresses", details: }))”] [endpoints=http://172.16.12.113:2379]
[2024/05/15 12:41:59.671 +08:00] [INFO] [util.rs:604] [“connecting to PD endpoint”] [endpoints=http://172.16.12.111:2379]
[2024/05/15 12:41:59.672 +08:00] [INFO] [] [“subchannel 0xffe8e05c5c00 {address=ipv4:172.16.12.111:2379, args=grpc.client_channel_factory=0xfffd00510cf8, grpc.default_authority=172.16.12.111:2379, grpc.initial_reconnect_backoff_ms=1000, grpc.internal.subchannel_pool=0xfffd00201a40, grpc.keepalive_time_ms=10000, grpc.keepalive_timeout_ms=3000, grpc.max_receive_message_length=-1, grpc.max_reconnect_backoff_ms=5000, grpc.max_send_message_length=-1, grpc.primary_user_agent=grpc-rust/0.10.4, grpc.resource_quota=0xfffd000efd80, grpc.server_uri=dns:///172.16.12.111:2379}: connect failed: {"created":"@1715748119.672112390","description":"Failed to connect to remote host: Connection refused","errno":111,"file":"/root/.cargo/registry/src/github.com-1ecc6299db9ec823/grpcio-sys-0.10.3+1.44.0-patched/grpc/src/core/lib/iomgr/tcp_client_posix.cc","file_line":200,"os_error":"Connection refused","syscall":"connect","target_address":"ipv4:172.16.12.111:2379"}”]
[2024/05/15 12:41:59.672 +08:00] [INFO] [] [“subchannel 0xffe8e05c5c00 {address=ipv4:172.16.12.111:2379, args=grpc.client_channel_factory=0xfffd00510cf8, grpc.default_authority=172.16.12.111:2379, grpc.initial_reconnect_backoff_ms=1000, grpc.internal.subchannel_pool=0xfffd00201a40, grpc.keepalive_time_ms=10000, grpc.keepalive_timeout_ms=3000, grpc.max_receive_message_length=-1, grpc.max_reconnect_backoff_ms=5000, grpc.max_send_message_length=-1, grpc.primary_user_agent=grpc-rust/0.10.4, grpc.resource_quota=0xfffd000efd80, grpc.server_uri=dns:///172.16.12.111:2379}: Retry in 1000 milliseconds”]
[2024/05/15 12:41:59.672 +08:00] [ERROR] [util.rs:682] [“connect failed”] [error=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "failed to connect to all addresses", details: }))”] [endpoints=http://172.16.12.111:2379]
[2024/05/15 12:41:59.672 +08:00] [INFO] [util.rs:604] [“connecting to PD endpoint”] [endpoints=http://172.16.12.112:2379]
[2024/05/15 12:41:59.751 +08:00] [WARN] [client.rs:152] [“failed to update PD client”] [error=“Other("[components/pd_client/src/util.rs:343]: cancel reconnection due to too small interval")”]
[2024/05/15 12:41:59.993 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:41:59.993 +08:00] [WARN] [pd.rs:1842] [“report min resolved_ts failed”] [err=“Other("[components/pd_client/src/util.rs:427]: request retry exceeds limit")”]
[2024/05/15 12:41:59.994 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:41:59.994 +08:00] [INFO] [util.rs:604] [“connecting to PD endpoint”] [endpoints=http://172.16.12.113:2379]
[2024/05/15 12:41:59.997 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:41:59.999 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:42:00.002 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:42:00.007 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:42:00.009 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:42:00.012 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:42:00.015 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:42:00.017 +08:00] [ERROR] [util.rs:462] [“request failed, retry”] [err_code=KV:Pd:Grpc] [err=“Grpc(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: "not leader", details: }))”]
[2024/05/15 12:42:00.023 +08:00] [ERROR] [util.rs:462] ["request