【 TiDB 使用环境】生产环境
【 TiDB 版本】 7.5TIKV
【复现路径】一读多写
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
我们有一个3节点的服务器,每个服务器上两个3.5TIB 的 SSD 。
当前我们的服务是juicefs +TIKV , 我们juicefs 上有 22亿的文件,
我们发现TIKV 的监控的QPS 达到了800M QPS/s 甚至更高,这个感觉不太符合常理,请问下这里是不是有什么问题,
如何修复呀?
【附件:截图/日志/监控】
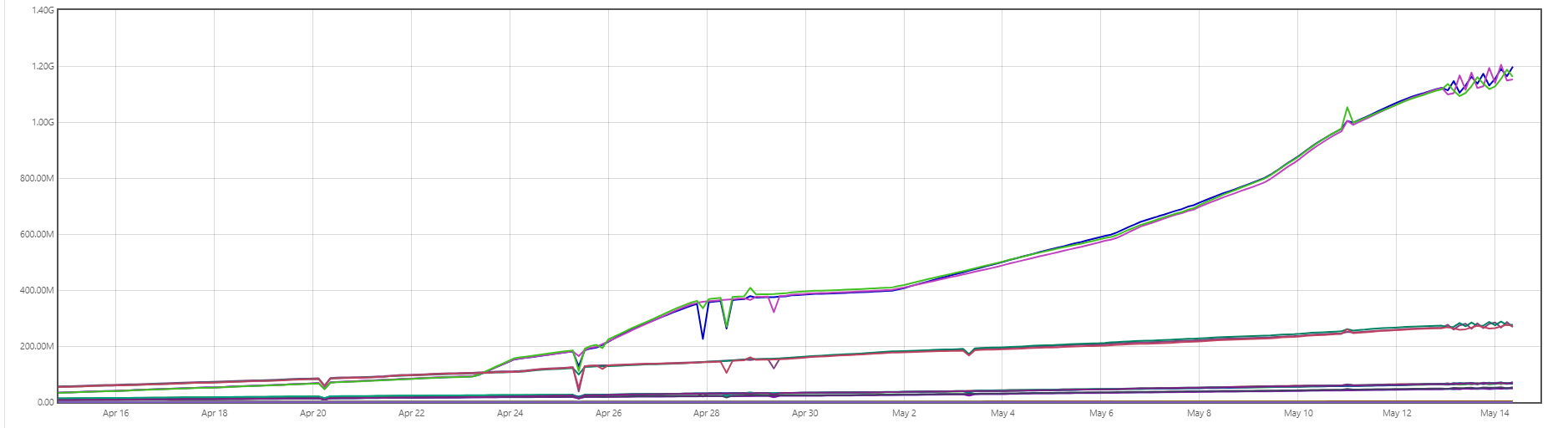
写,也是先查出来 再做修改,这个qps值 是感觉大的不正常?
我也感觉有点离谱,不知道怎么排查,这里是小白,有什么可以指点的吗?
这个QPS 我都数不过来了
有热点?
看是哪个时间段的,比对下一周的峰值
最好提供一下底层的日志
1 个赞
热点导致的吗
先从业务上排除一下,看是否业务高峰,近期业务系是否升级等
不确定 什么是热点,我是用作juicefs 的 元数据服务,最终暴露的是文件接口。 TIKV 层面没法感知。。。
我看从2024.4 月中旬上线,到 2024.5月中旬,一直是累积的样子,一直是递增的,不像是别人几千QPS 的样子,
业务常规使用,从4月份上线,就一直在增加,曲线呈累积的事态,像是数值累加了一样。但也会的模型不会这样的。
这个图看着不像是grafana的图。是谁提供的?
为啥不去juicefs的社区问问?毕竟是juicefs在用tikv吧?
排除一下慢语句,慢语句堆积会影响整体并发和整个集群的性能
也有这种可能
这个是抓到的Prometheus 的数据,展示样式不同而已, 这个QPS 的值我是想从TIKV 层面看看,是否是显示有问题, 想从TIKV 层面判断下是否是异常。
不会抓错指标了吧?抓成类似cpu time 、tikv usage 之类的累加值
可以看到详细的 promsql 吗
1 个赞
提供一下计算方式吧。有的指标就是一直累加的,展示的时候需要前值减后值。会不会是类似的问题?
没有细节就不清楚是哪里有问题。
1 个赞