【 TiDB 使用环境】生产环境
【 TiDB 版本】7.1.2
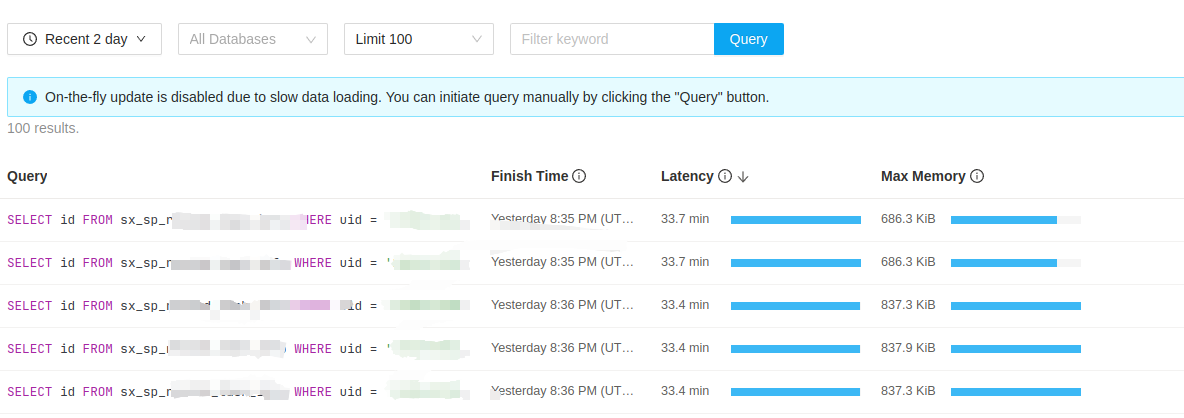
【遇到的问题:问题现象及影响】执行简单查询语句耗时非常久,有索引,表的总数据量百万级别
【附件:截图/日志/监控】
SQL 如下
select id from sx_sp_rti where uid = ‘xxx’ and comp_id = ‘xxx’;
其中 uid 字段有索引,执行耗时 33.7 min!
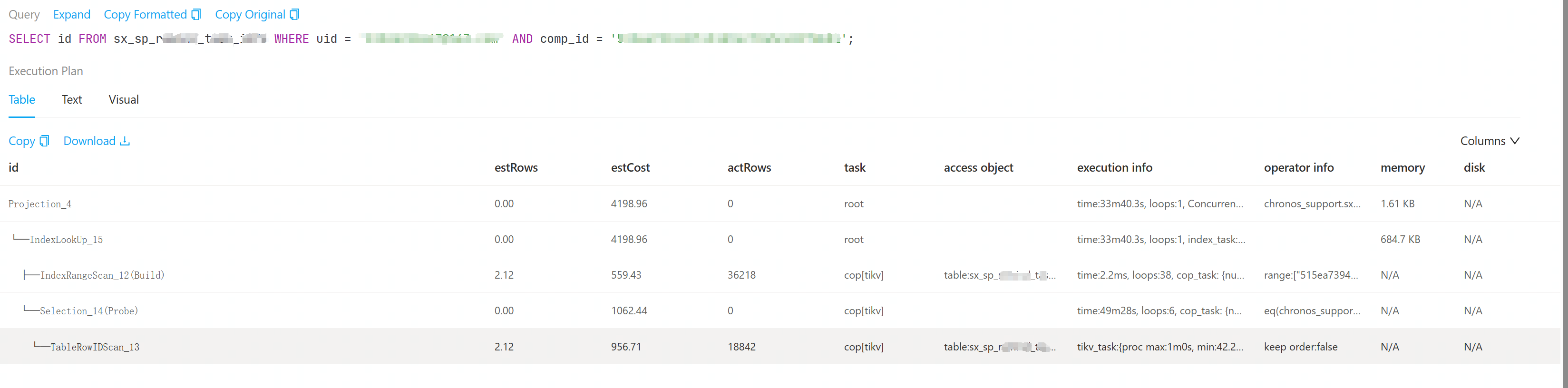
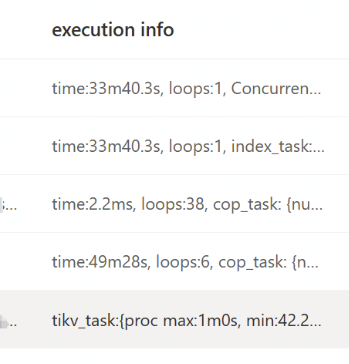
执行计划文本
| id | estRows | estCost | actRows | task | access object | execution info | operator info | memory | disk |
| Projection_4 | 0.00 | 4198.96 | 0 | root | | time:33m40.3s, loops:1, Concurrency:OFF | chronos_support.sx_sp_rti.id | 1.61 KB | N/A |
| └─IndexLookUp_15 | 0.00 | 4198.96 | 0 | root | | time:33m40.3s, loops:1, index_task: {total_time: 5.28ms, fetch_handle: 5.24ms, build: 16.5µs, wait: 23µs}, table_task: {total_time: 49m28.1s, num: 6, concurrency: 5}, next: {wait_index: 1.81ms, wait_table_lookup_build: 390.3µs, wait_table_lookup_resp: 11m49.6s} | | 684.7 KB | N/A |
| ├─IndexRangeScan_12(Build) | 2.12 | 559.43 | 36218 | cop[tikv] | table:sx_sp_rti, index:idx4_sx_sp_rti(comp_id) | time:2.2ms, loops:38, cop_task: {num: 8, max: 678.7µs, min: 203.9µs, avg: 358.4µs, p95: 678.7µs, max_proc_keys: 480, p95_proc_keys: 480, tot_proc: 756.4µs, tot_wait: 228.9µs, rpc_num: 8, rpc_time: 2.78ms, copr_cache_hit_ratio: 0.75, build_task_duration: 8.87µs, max_distsql_concurrency: 1}, tikv_task:{proc max:517ms, min:0s, avg: 120.4ms, p80:238ms, p95:517ms, iters:66, tasks:8}, scan_detail: {total_process_keys: 704, total_process_keys_size: 118272, total_keys: 710, get_snapshot_time: 59.9µs, rocksdb: {delete_skipped_count: 68, key_skipped_count: 776, block: {cache_hit_count: 31}}} | range:[“515ea7394d2f431d94c79a5ca99fdb81”,“515ea7394d2f431d94c79a5ca99fdb81”], keep order:false | N/A | N/A |
| └─Selection_14(Probe) | 0.00 | 1062.44 | 0 | cop[tikv] | | time:49m28s, loops:6, cop_task: {num: 5, max: 1m42.5s, min: 59.3s, avg: 1m8.1s, p95: 1m42.5s, max_proc_keys: 9184, p95_proc_keys: 9184, tot_proc: 1.54s, tot_wait: 544.8µs, rpc_num: 16, rpc_time: 15m40.3s, copr_cache_hit_ratio: 0.00, build_task_duration: 971.9µs, max_distsql_concurrency: 1}, backoff{regionMiss: 2ms, tikvRPC: 475ms}, tikv_task:{proc max:1m0s, min:42.2s, avg: 56.1s, p80:1m0s, p95:1m0s, iters:41, tasks:5}, scan_detail: {total_process_keys: 18842, total_process_keys_size: 13142340, total_keys: 19076, get_snapshot_time: 101µs, rocksdb: {key_skipped_count: 710, block: {cache_hit_count: 207075}}} | eq(chronos_support.sx_sp_rti.uid, “xxxx”) | N/A | N/A |
| └─TableRowIDScan_13 | 2.12 | 956.71 | 18842 | cop[tikv] | table:sx_sp_rti | tikv_task:{proc max:1m0s, min:42.2s, avg: 56.1s, p80:1m0s, p95:1m0s, iters:41, tasks:5} | keep order:false | N/A | N/A |
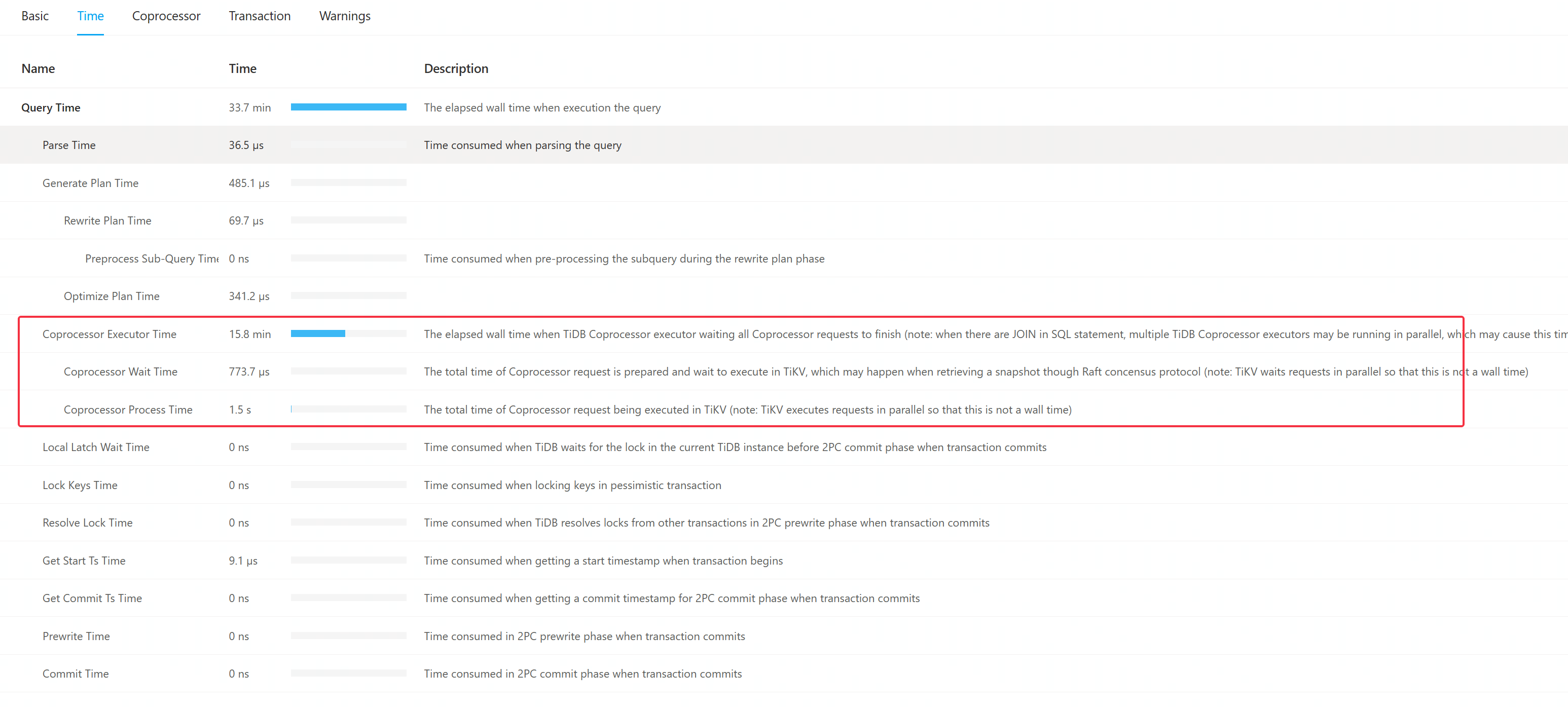
这里的 Coprocessor Executor Time 远远大于 Coprocessor Process Time,有可能是什么问题?
====== 补充一下关键信息
业务方的操作有开事务,事务里先执行了上边的这个查询语句,查出所有 id ,存在的话会先根据 id 删除数据,再执行新增数据的插入操作 ,其中 id 是雪花算法生产的唯一 id ,在 uid 和 comp_id 有非唯一索引。
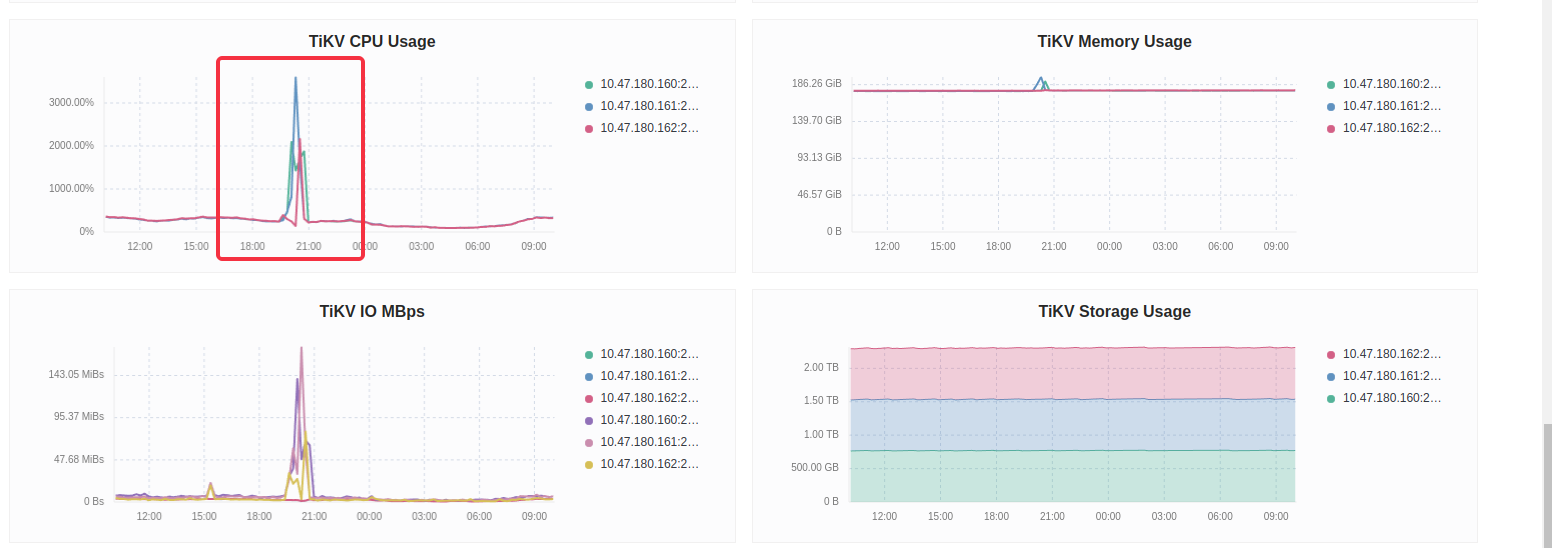
故障出现在有大量同一个 comp_id 的操作请求时,在终止掉这些请求后恢复正常
故障期间有出现频繁的 region leader 切换
[2024/05/13 19:21:40.313 +08:00] [INFO] [operator_controller.go:571] [“operator finish”] [region-id=234008] [takes=1.334272ms] [operator=“"transfer-hot-read-leader {transfer leader: store 3 to 1} (kind:hot-region,leader, region:234008(17178, 5), createAt:2024-05-13 19:21:40.311542511 +0800 CST m=+15385682.207289421, startAt:2024-05-13 19:21:40.311741338 +0800 CST m=+15385682.207488249, currentStep:1, size:130, steps:[0:{transfer leader from store 3 to store 1}],timeout:[1m18s]) finished"”] [additional-info=]