课程名称:TiDB数据库核心原理与架构(101)
学习时长:
500min
课程收获:
tidb各组件的架构
课程内容:
我们需要怎么的数据库
-
扩展性
-
强一致性高可用性 rpo 数据丢失量 rto 系统恢复时间。rpo=0 rto足够小
-
标准sql 和 acid事务
-
云原生
-
htap
-
兼容主流生态和协议
数据技术栈常见的基础因素
-
数据模型
-
数据存储与检索
-
数据格式
-
存储引擎
-
复制协议
-
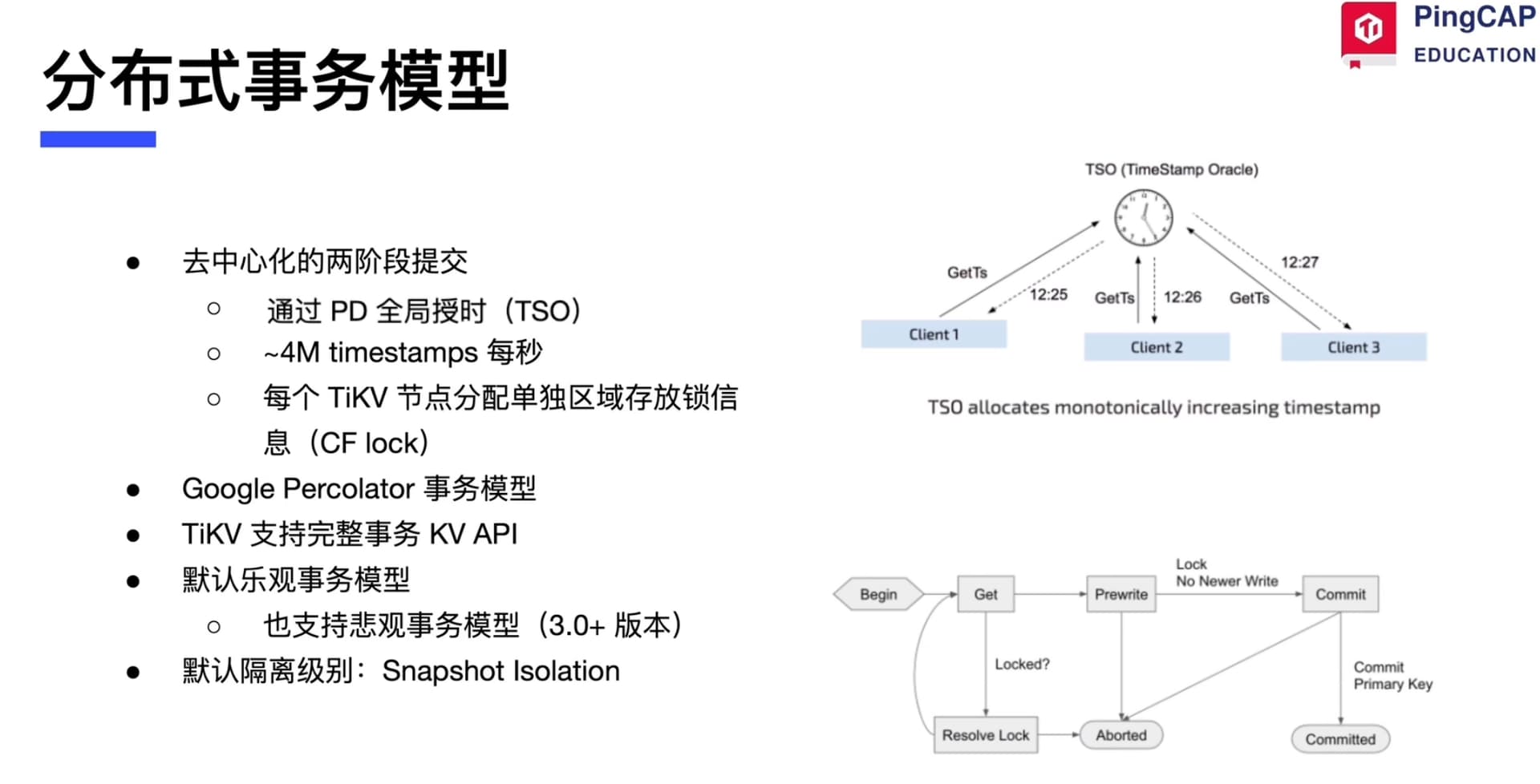
分布式事务模型
-
数据架构
-
优化器算法
-
执行引擎
计算与存储分离
硬件 尤其是网络的发展 推动了计算和存储分离




我们需要怎么的存储引擎
-
更细粒度的弹性扩缩性
-
高并发读写
-
数据不丢不错
-
多副本保障一致性及高可用
-
支持分布式事务
选择数据结构
lsm-tree 用空间置换写入延迟,用顺序写替换随机写
写入是最昂贵的成本
lsm-tree 支持批量写入 无锁快照
数据复制
raft
如何实现扩展
预先分片(静态分片)or 自动分片(动态分片)用自动
分片算法 hash range list 用rage
region 就是一个range分片
pd负载region的均衡调度
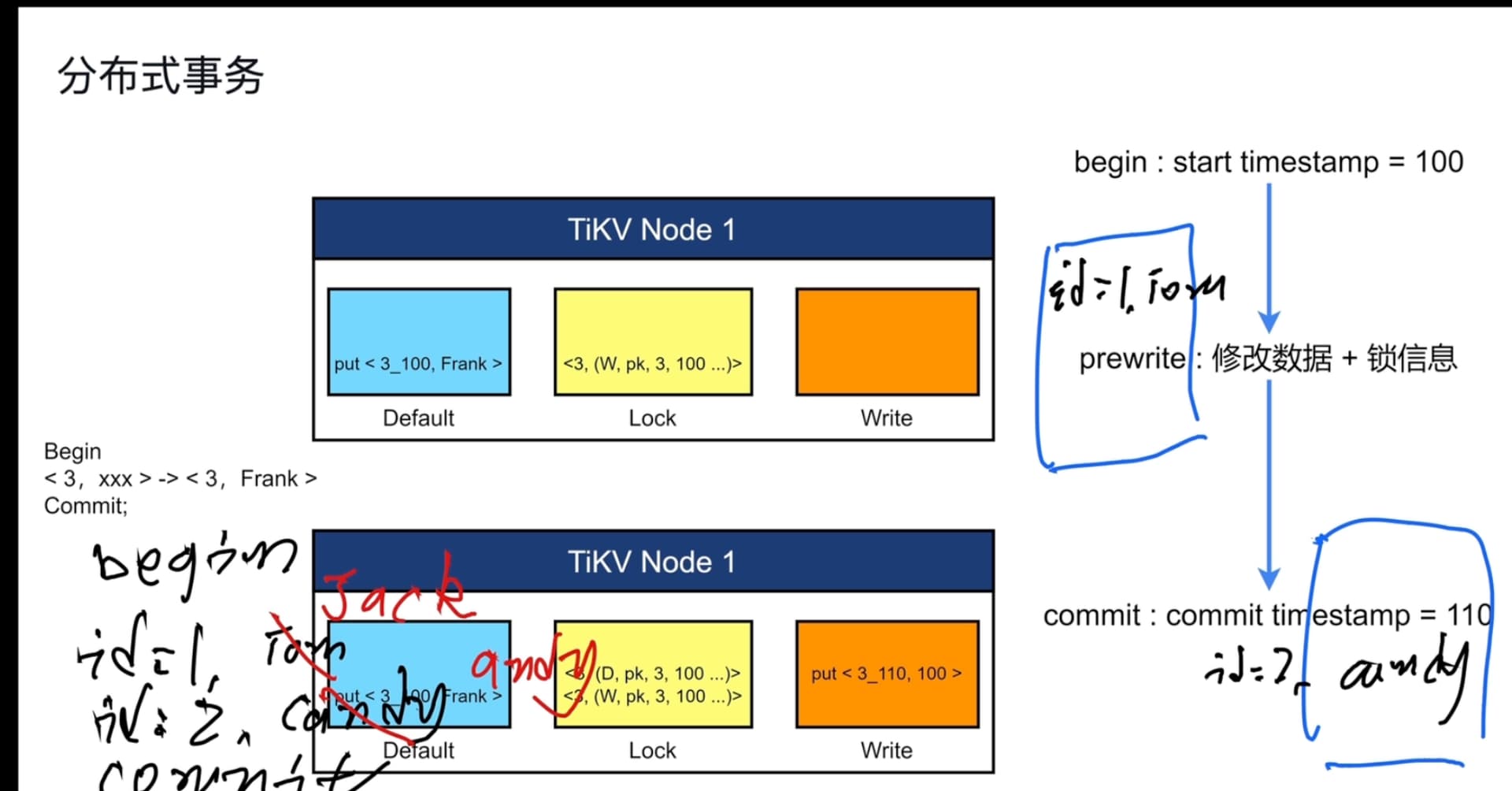
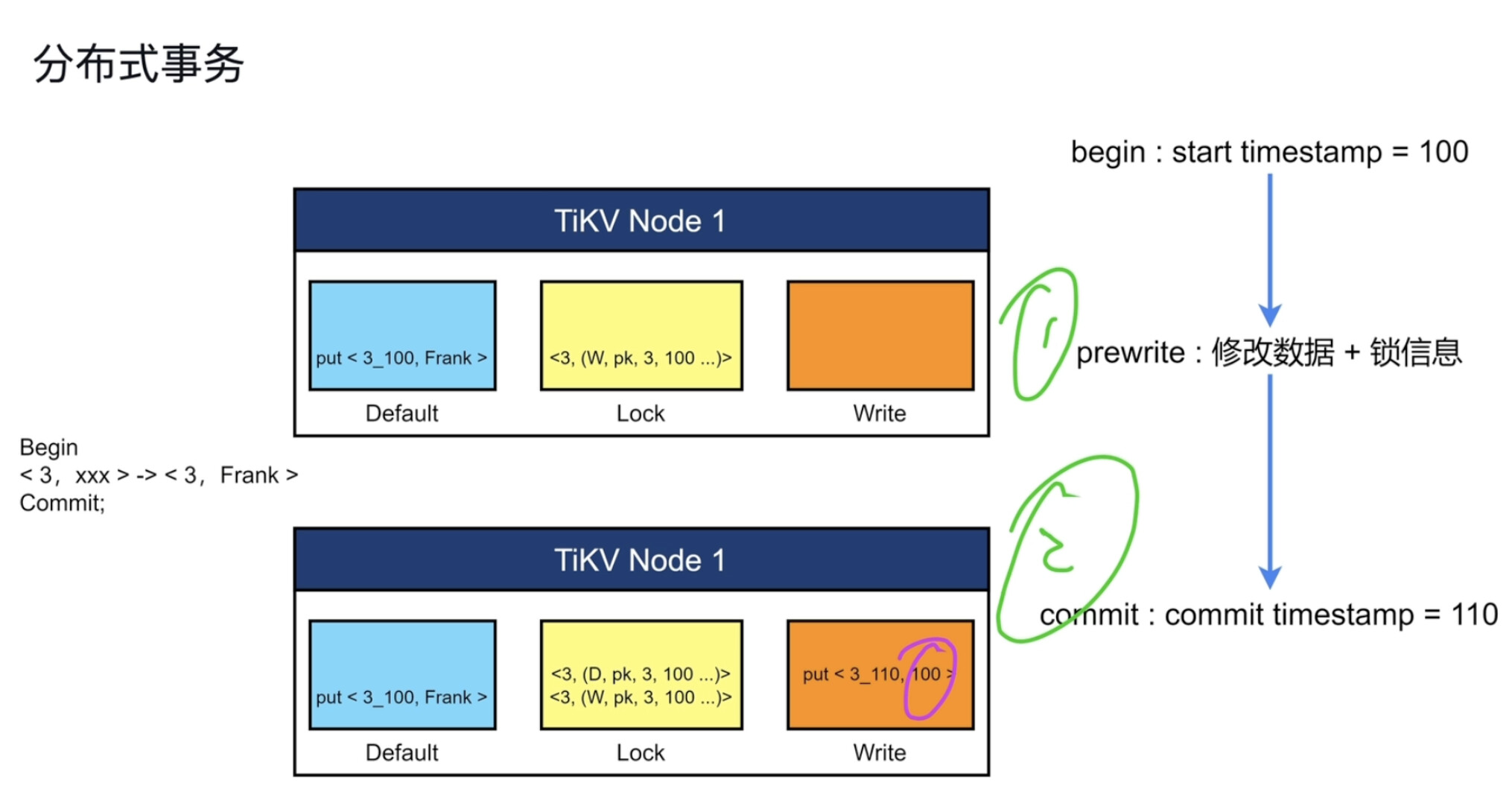
分布式事务 去中心化的两阶段提交
tidb事务隔离si (snapshot isolation) rr 支持rc
默认乐观锁
如何构建分布式sql引擎
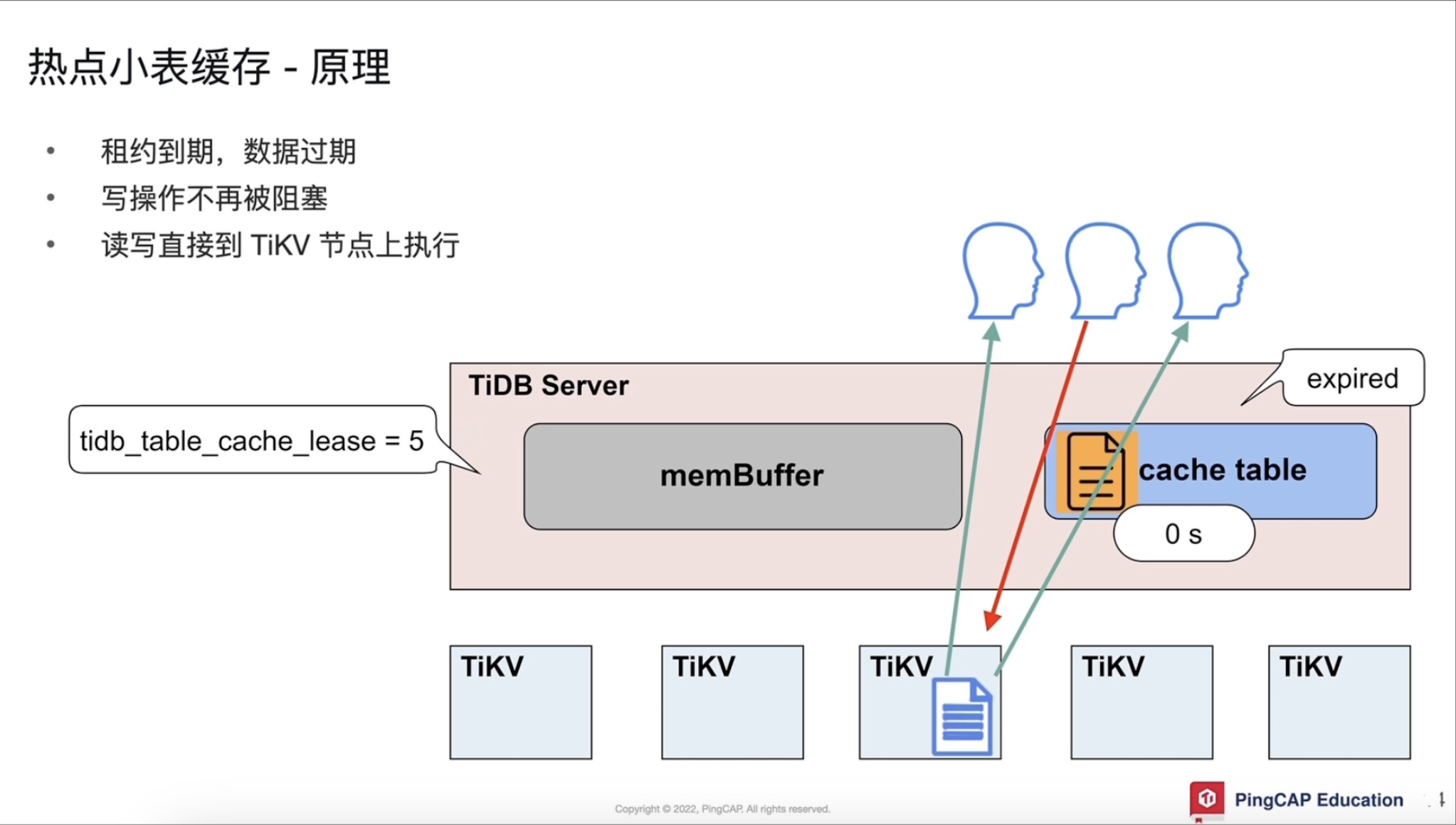
小表缓存
数据量不大 64m以下
只读 或 修改不频繁
表的访问很频繁
租约
tidb_table_cache_lease = 5 单位秒
租约到期前不能写,写会阻塞
开启小表缓存有不能做ddl 互斥
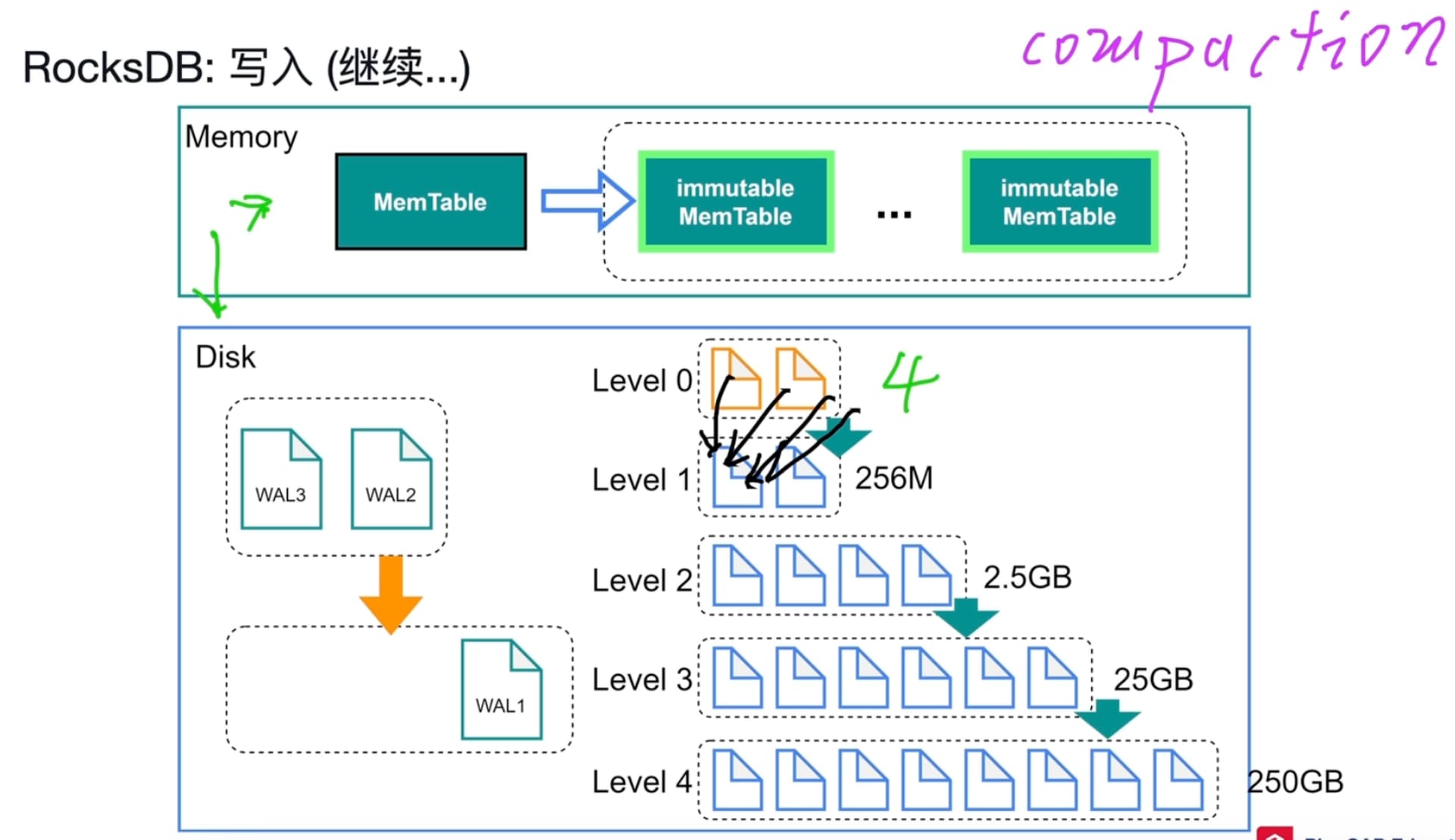
先写wal,再写memtable。
write_buffer_size 到了之后 memtable会转成immutable memtable
immutable memetable防止memtable直接转sst时候的写阻塞
immutable memtable有1个就刷磁盘,达到5个没有持久化成sst时会写阻塞 write stall 流控
小于255字节,直接写write列
学习过程中遇到的问题或延伸思考:
- 问题 1:聚蔟表和非聚蔟表的区别
以mysql为例,聚簇索引是按照表中的主键进行排序的索引,一个表只能有一个聚簇索引。聚簇索引在表中的数据存储方式是将整个表的数据存储在一棵B+树中,并根据主键排序。
非聚簇索引是按照非主键字段进行排序的索引,一个表可以有多个非聚簇索引。非聚簇索引在表中的数据存储方式是将索引字段的值与该数据行的地址存储在一棵B+树中。
因此,如果按照非主键字段查询数据,则可以通过非聚簇索引定位到符合条件的数据行所在的磁盘页,然后直接获取该数据行的数据,因此效率相对较高。