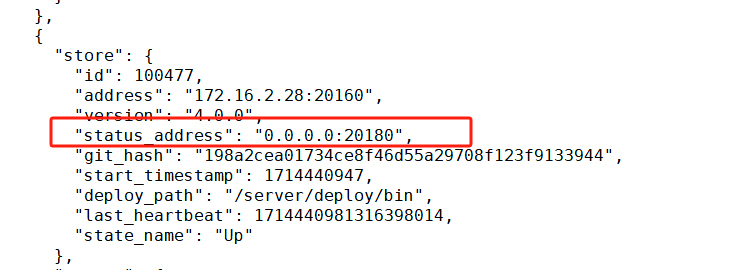
这个地方地址信息 正常吗?我看其他几个store这个地方 status_address和addressIP是对应的一样的。这个不一样。这两个地方都没有ip只是0.0.0.0 地址信息。这个是哪里配置少了吗?

看一下你的配置文件
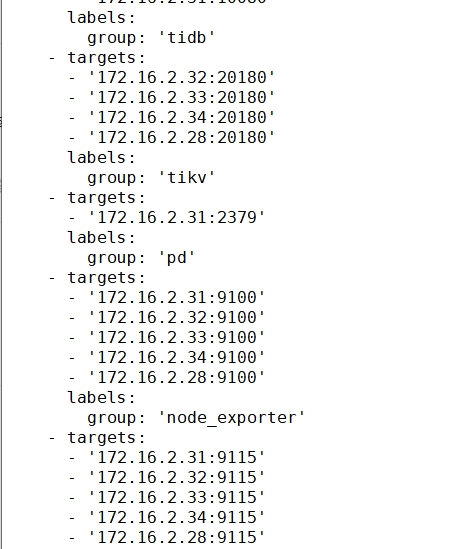
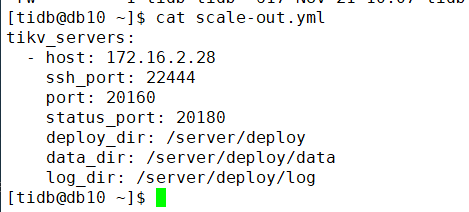
这个新节点是扩容的 scale文件:
tikv_servers:
- host: 172.16.2.28
ssh_port: 22444
port: 20160
status_port: 20180
deploy_dir: /server/deploy
data_dir: /server/deploy/data
log_dir: /server/deploy/log
可能是配置文件没生效
这个配置是直接复制之前扩容的文件只改了一个IP地址,而且和官方的一样没任何区别,我还重启了三四遍服务器。不应该呀。配置没生效那应该是20180端口也用不了吧。为啥端口启动了。对应的IP没用到呢
https://docs.pingcap.com/zh/tidb/stable/tiup-cluster-topology-reference#tikv_servers
是不是主机有多个ip,默认值 0.0.0.0 ,但是你这指定ip,怎么还会出现,是不是格式那块没有生效
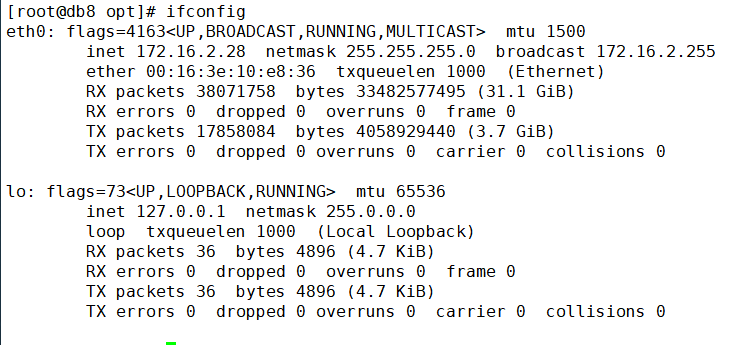
20180 这个端口是监控用的,你看下监控是否正常?
顺便看下/data/tidb-deploy/prometheus-8249/conf/prometheus.yml 这配置文件中的xxx:20180对不对
这个是在tidb部署服务器查看还是看对应有问题的服务器上的配置?
监控图里面显示有2个问题store, 但是我在pd-ctl里面store查看都是up状态,只不过这个有问题的2.28 服务器他的up时间一直是几十秒 几分钟,好像是一两分钟重启一次,他的进程好像一直再重启
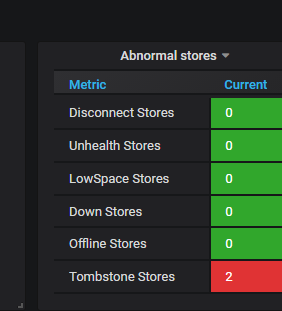
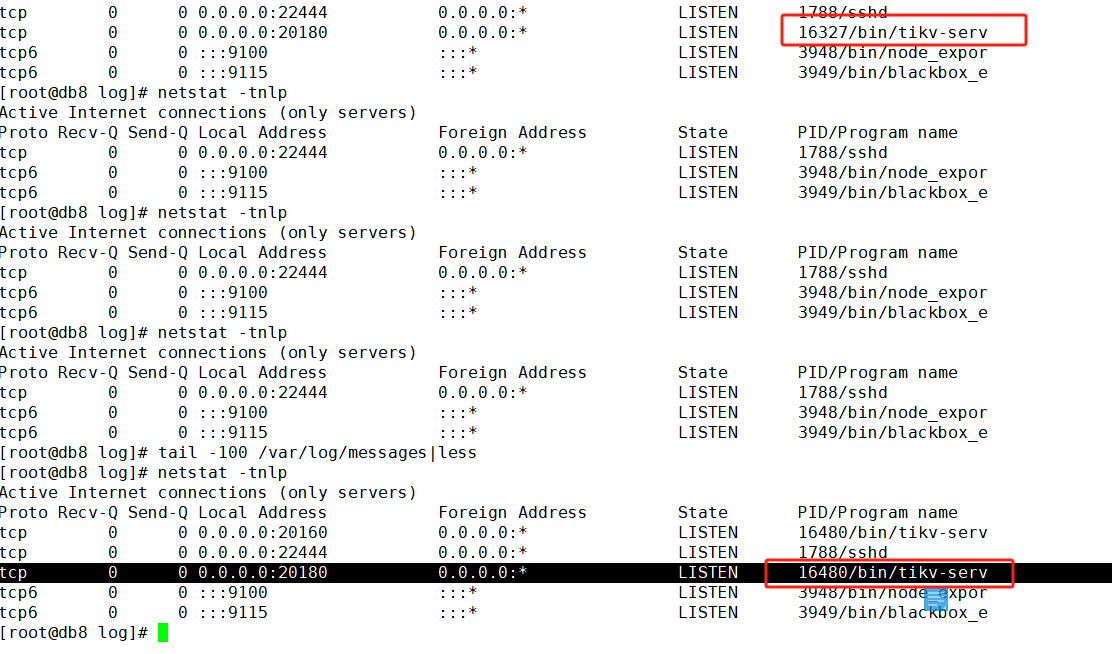
![]() 不会是低版本显示 bug 吧。
不会是低版本显示 bug 吧。
有可能是新增扩容的问题,现在也不知道是不是内存问题,几分钟就会重启一下tikv服务,
过一遍扩容过程,看那个配置没有加载上
升级吧 这个版本太老了。。。。已经快不知道 ansible 的用法了。。。
是不是普拓文件有异常,是不是从windows直接复制来的,有不识别字符导致没生效
配置文件在检查一下呢
不是,使用之前 前任DBA扩容的文件直接cp 修改了ip地址。其他都没变化
扩容的这一个scale文件。没看出任何问题
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。