【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】7.5.1
【遇到的问题:问题现象及影响】
原理的集群重装为版本7.5.1,使用原来的配置文件部署,然后lightning导入重装前的备份数据。导入完成后,又重启了一次集群,发现集群故障
故障现象:
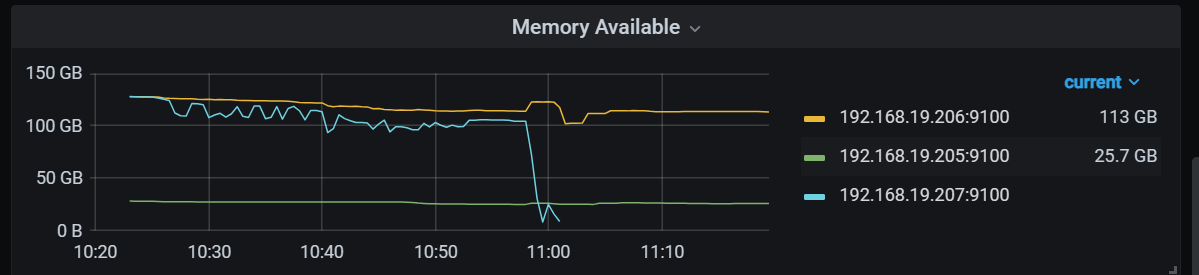
19.207服务器内存耗尽离线了
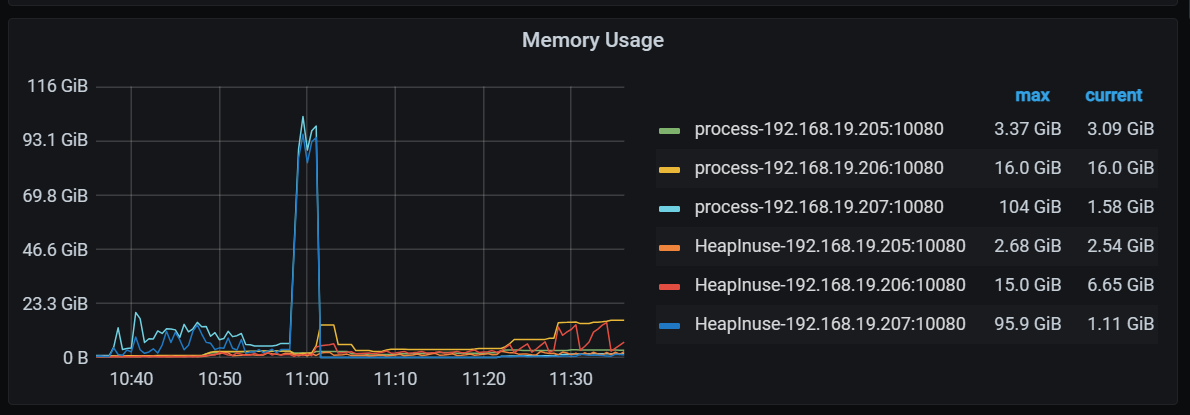
Heaplnuse-192.168.19.207:10080 占用了很大的内存:95.9 GiB
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】7.5.1
【遇到的问题:问题现象及影响】
原理的集群重装为版本7.5.1,使用原来的配置文件部署,然后lightning导入重装前的备份数据。导入完成后,又重启了一次集群,发现集群故障
故障现象:
19.207服务器内存耗尽离线了
Heaplnuse-192.168.19.207:10080 占用了很大的内存:95.9 GiB
查看下系统日志?
大sql干挂了。日志有些的
dashboard查询下expensive日志,有没有大内存的SQL或者其他
还没等到oom kill我就重启机器了 系统日志没发现太有用的东西
看看日志吧
只有两个tikv服务器? tidb pd tikv 三个还都是安装在 同一个服务器?? 你副本是1个吗?如果是1个tikv应该没问题,如果是3个 ,tikv会有问题官方文档 3副本,至少要3个tikv,
有6个tikv 3副本
lightning导入完成的时候还是正常的吗,然后重启集群后发现tidb节点占用内存非常高,就手动重启了机器对吧?重启机器后跑了sql吗,比如接入业务了吗,有人跑sql测试吗
先lightning导入完成 正常的 ,然后resstart集群,过了10分钟有个机器失联了,一看 内存占用太高卡死了
这十分钟有没有人执行sql呢,最好在有问题的tidb的日志中找找expensive关键字,如果是sql导致的内存升高,基本会有这个关键字。如果找不到的话,可能是其他原因了。
先确定一下是哪个组件oom, 安装 tidb,tikv
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-tidb-oom
https://docs.pingcap.com/zh/tidb/stable/tune-tikv-memory-performance
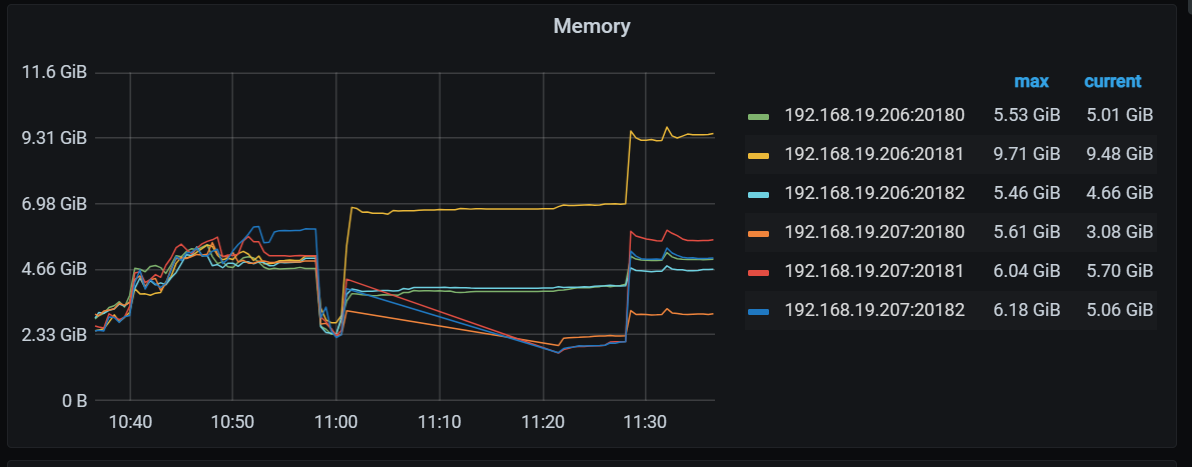
你这混搭,有时候确实不好分析,去grafana看看占用内存高是哪个组件
上面截图有了,Heaplnuse-192.168.19.207:10080占了90多G
需要看下日志的
看看大sql
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。