首先非常感谢 InfoQ 的邀请! TiDB 社区应用创新负责人霍昊 在 QCon 北京站大会上能和大家见面。在 4 月 12 日下午的 Al+everythig/基础大模型 展区 Mini Open Talk 环节中,霍昊老师和大家聊了聊 基于 TiDB Vector 的 RAG AI 聊天机器人 的开发与应用。

资料下载:
TiDB Database for MySQL Users to Build AI Apps.pptx (36.9 MB)
先看看 Demo!
小助手 Ask TiDB 入口: tidb.ai
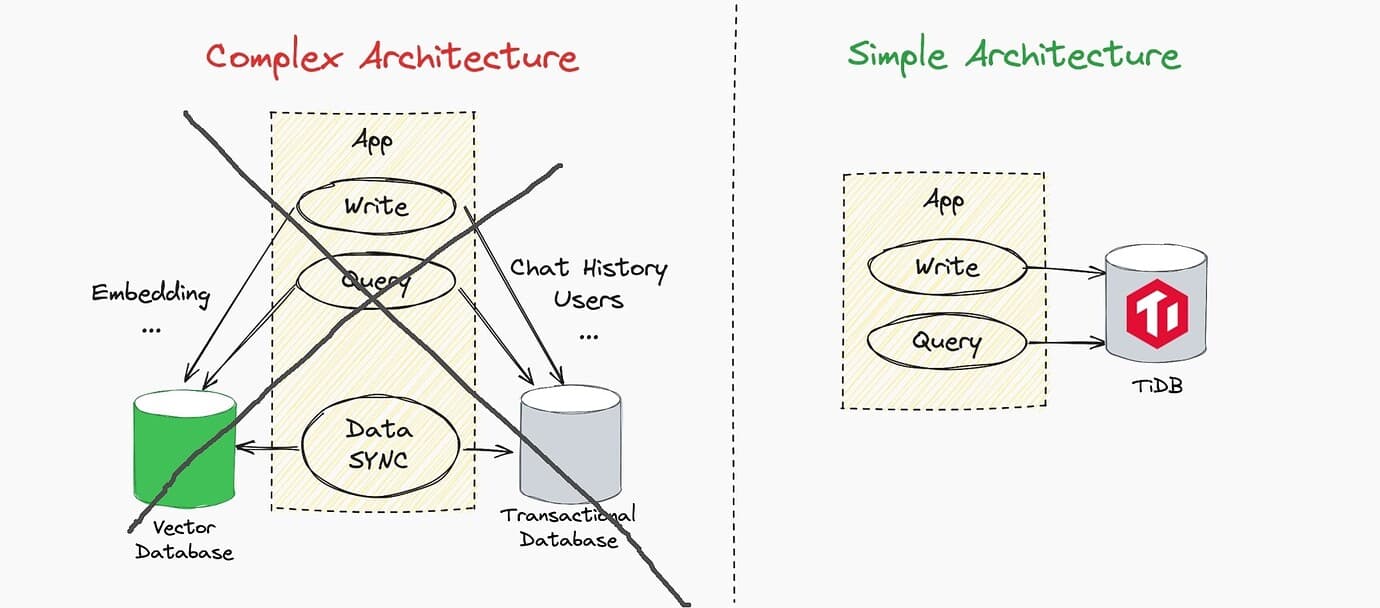
“Ask TiDB” 背后的架构

什么是向量搜索
与传统的基于关键词的搜索不同,向量搜索基于理解数据的含义和上下文的原理运作。它将复杂的数据——如文本、图像或音频——转换为数值向量嵌入。这些嵌入使得数据库能够基于语义理解进行搜索,而不仅仅是基于精确的单词匹配。这种方法对于处理大量非结构化数据的 AI 应用程序至关重要,在这里,精确度和上下文是关键。
向量搜索不仅仅是关于更智能的数据解释;它也关乎性能和可扩展性。它优化了查询效率,使得能够更快速、更准确地在大型、复杂的数据集中进行搜索。通过在 TiDB Serverless 中添加向量搜索,我们增强了其处理AI和机器学习工作负载的能力。这使得它成为 MySQL+AI 生态系统中开发者的有力工具。
TiDB Vector 架构
TiDB Vector 是基于 TiDB Serverless 的向量搜索功能,它将传统数据库的强大功能与先进的向量搜索能力相结合。这一功能的引入,使得开发者能够在熟悉的 MySQL 环境中,直接处理和查询向量数据。
架构特点
- 水平扩展与分布式计算:TiDB Vector 继承了 TiDB Serverless 的分布式架构,能够高效地处理大规模数据集。
- 向量数据类型:通过引入新的数据类型,TiDB Vector 能够在数据库中直接存储和索引向量嵌入。
- 相似性搜索索引:采用如 Hierarchical Navigable Small World (HNSW) 等算法,优化了向量数据的存储和检索效率。
- SQL集成:开发者可以使用标准的 SQL 语句来执行向量搜索,无需额外的编程语言或工具。
基于 TiDB Vector 的 RAG AI 聊天机器人的探索
RAG是一种结合检索和生成的 AI 模型,它能够根据用户的输入先从向量数据库里检索相关信息,再将检索出来的信息,和问题一起发送给大模型,最终生成连贯、准确的回答。在TiDB Vector 的发布之后,我们也基于 TiDB Vector 开发了一款 RAG(Retrieval-Augmented Generation)AI Convesational Search 的应用。
示例地址:https://tidb.ai
(有兴趣的同学可以去试试,完全开源,因为正在开发中,会有一些 bug 存在的情况)
另外,我们也总结出:TiDB 是 MySQL 用户构建 AI 应用所需的唯一数据库。
-
最简架构:全能数据库,仅需 MySQL 技能
-
避免了重复操作:在传统的数据库解决方案中,开发者往往需要在不同的数据库之间同步数据,这不仅需要编写额外的同步脚本,还会导致网络I/O的开销和存储空间的重复。TiDB通过其内置的向量搜索功能,避免重复操作。
-
单轮对话 CRUD 优于多轮对话
-
免费的 AI 应用数据库,最高 25 GiB 存储
目前已开放 Waitlist 体验名单!欢迎尝鲜使用!
TiDB Vector 体验等待申请:Built-In Vector MySQL Database