一般来说,每个表都是自己单独的 region 还是所有表共用 region。
1.如果是单独,会存在大量的 region 引起向 PD 心跳报告性能问题(老师举例说超过 5w 个 region)
2.如果是共用 region,会导致单表的全表扫描可能需要扫描所有 region(比如每隔 region 只有一条数据)
上面的理解对吗,如果对,TIDB 怎么解决这个问题哪?
单独占用region
单独占用region
独占region的
一个region一般96m,大多数情况下,都是一个表对应多个region,如果开启跨表合并的话,可能会存在1个region上有几个小表的情况
这问题我也没搞清楚 现在知道了默认是一个表多个region 不会一个region对应多个表

也不太懂
-
- Region: 负载均衡的最小单元。TiKV 中的全量数据是以有序的方式存储的,
PD 根据数据的尺寸将全量数据分割成一系列的 Region,每一个 Region 承载全量数据中一段较小范围的数据。
- Region: 负载均衡的最小单元。TiKV 中的全量数据是以有序的方式存储的,
所以是单独的region
默认是单独region 如果跨表合并就可能会出现多表共享region
[quote=“Tidb789, post:1, topic:1024592”]
如果是共用 region,会导致单表的全表扫描可能需要扫描所有 region(比如每隔 region 只有一条数据)
[/quote] 这个问题并不是因为共享region造成的 读写放大问题是由TiKV本身架构造成的 看这往篇帖子回复就可以 请问什么是读放大和写放大 - TiDB 的问答社区 (asktug.com)
新建一个表默认是一个新的region,如果这个表数据很少,数据库参数enable-cross-table-merge空值是否可以进行region跨表合并

通过查询语句我们可以看到一个region可能包括多个表的数据
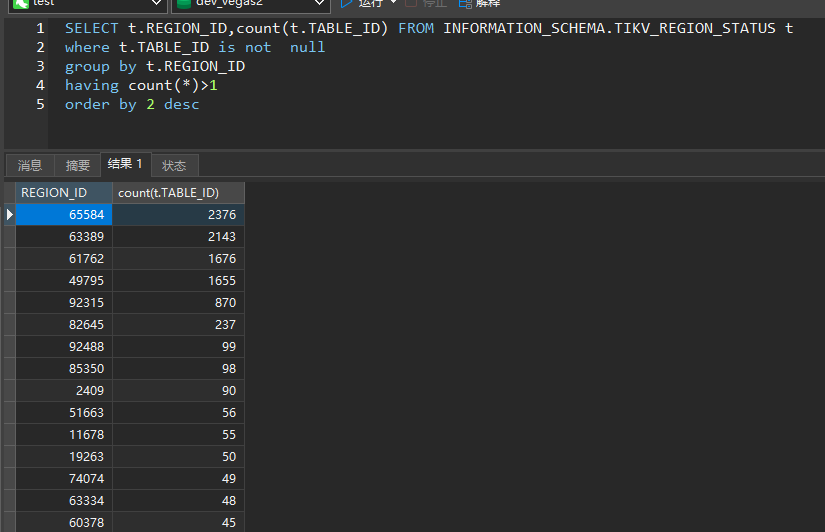
2.如果是共用 region,会导致单表的全表扫描可能需要扫描所有 region(比如每隔 region 只有一条数据)
这个你不用担心,region是逻辑概念,物理上所有tikv数据是一个有序的kv列表,key中带了表的id,同一个表数据是连续的,不存在跳跃扫描。
前面说的读写放大那个主要是tikv底层的rocksdb把所有数据增删改都转成了一个插入新key,导致旧数据在那里没清理的问题
1 个赞
默认是单独占用 region 的。我也好奇那么多 region 向 PD 发消息,PD 会不会成为瓶颈。后面再研究看看PD 是怎么处理的。
PD 为什么不会成为瓶颈?有懂的同学讲解一下不
tidb-server中的tikv-client组件会缓存pd的region信息,可以降低pd的压力
1 个赞
大佬,那过多的 region 向 pd 发心跳会引起性能问题怎么解决的哪?
是否可以这样理解,存在多种情况 table和region 的关系 1:1 1:N N:1 N:N 默认情况下 一个region 只存在一个表的数
我还以为 region 也是物理概念哪
这样可以理解为大表都是 独占多个 region,小表存在 region 融合。对把
请教,我看视频中说需要定期向 pd 发送心跳,tidb 是作为PB 级别容量存在的,这种情况下怎么解决大量心跳带来的性能开销哪?
