有一个慢查询,我看了dashboard的执行计划:
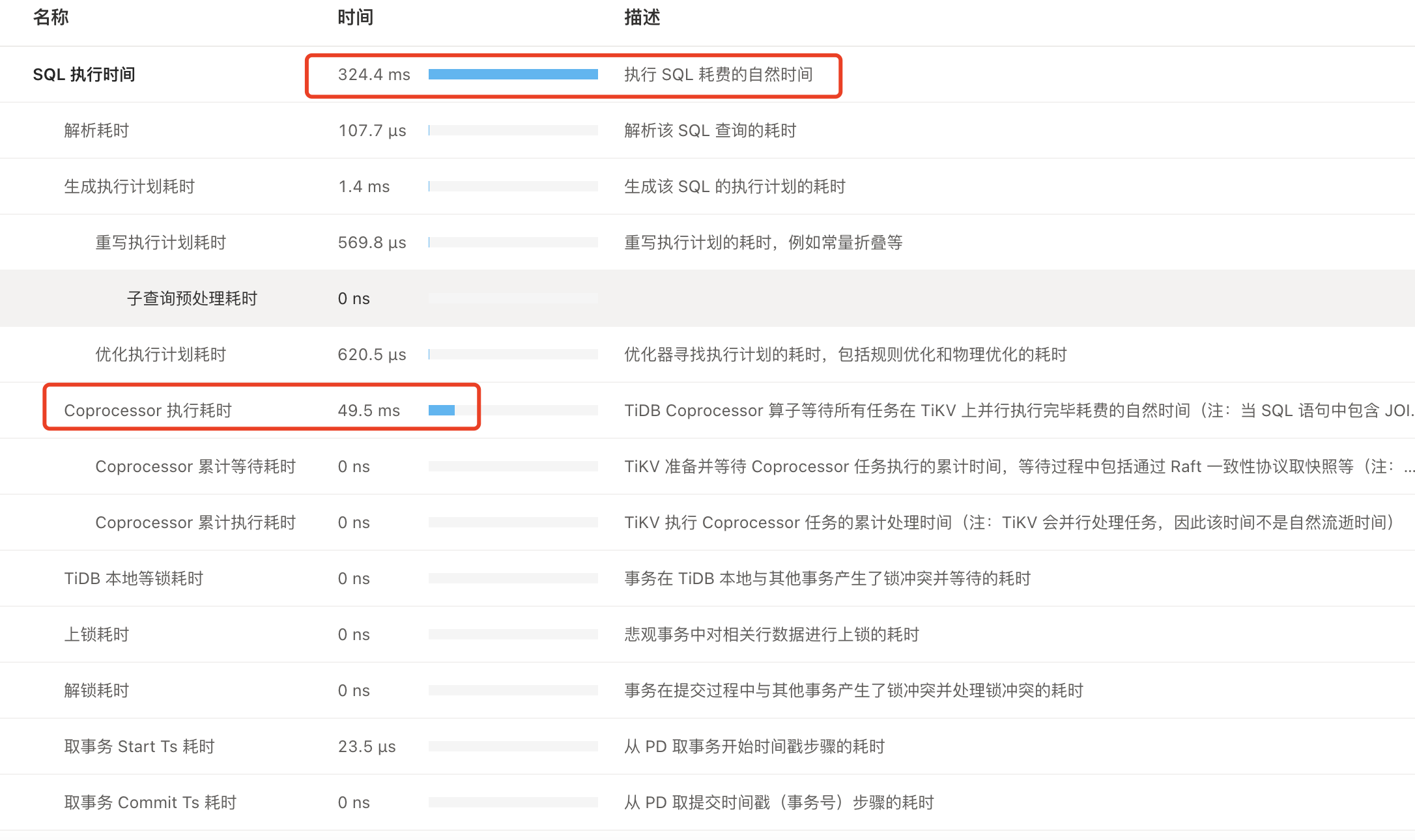
【整体执行时间】324ms,除了【Coprocessor 执行耗时】50多ms,没有其他明显耗时,这种一般都是耗时在什么地方?
表索引信息如下:
1、主键id、create_time; 在create_time做了partition分区
2、二级索引cid
查询语句 select * from table where cid = 123;

你把sql拉出来手工执行下explain analyze+sql看下执行计划,关键字pseudo出现的话就anlyze下表吧
这个语句的返回就是空的; 没有符合条件的语句,是不是这个原因
没有这个pseudo
执行计划能贴一下,看看慢在哪
没有,即使是命中索引了,也需要过滤行信息的
要看具体的执行计划;
现在这样子的信息还是看不出来
命中索引后过滤完没有数据,不需要回表过滤行信息了吧
客户端进库explain analyze 看下,还有tidb cpu和内存资源使用怎么样?
1 个赞
tidb server配置什么样 ? cpu 利用率高不高? sql执行计划的文本形式 复制上传下
大佬们已经给出了多种处理方法了
partition all, 应该是扫了全分区
感谢,
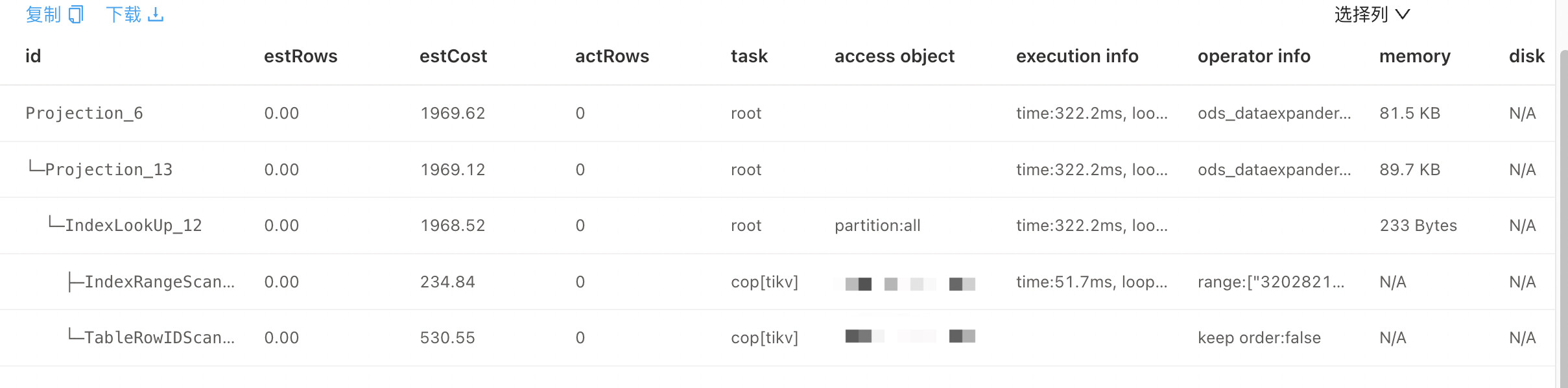
| id | estRows | estCost | actRows | task | access object | execution info | operator info | memory | disk |
| Projection_6 | 0.00 | 1969.62 | 0 | root | | time:322.2ms, loops:1, Concurrency:OFF | o_dp.t_hr.business_id, o_dp.t_hr.output_amount, o_dp.t_hr.output_product, o_dp.t_hr.create_time, o_dp.t_hr.output_result | 81.5 KB | N/A |
| └─Projection_13 | 0.00 | 1969.12 | 0 | root | | time:322.2ms, loops:1, Concurrency:OFF | o_dp.t_hr.business_id, o_dp.t_hr.customer_id, o_dp.t_hr.create_time, o_dp.t_hr.output_amount, o_dp.t_hr.output_result, o_dp.t_hr.output_product | 89.7 KB | N/A |
| └─IndexLookUp_12 | 0.00 | 1968.52 | 0 | root | partition:all | time:322.2ms, loops:1 | | 233 Bytes | N/A |
| ├─IndexRangeScan_10(Build) | 0.00 | 234.84 | 0 | cop[tikv] | table:t_hr, index:idx_customer_id(customer_id) | time:51.7ms, loops:41, cop_task: {num: 41, max: 270.6ms, min: 545.5µs, avg: 7.61ms, p95: 1.74ms, rpc_num: 41, rpc_time: 309.6ms, copr_cache_hit_ratio: 0.02, distsql_concurrency: 15}, tikv_task:{proc max:3ms, min:0s, avg: 292.7µs, p80:1ms, p95:1ms, iters:41, tasks:41}, scan_detail: {total_keys: 40, get_snapshot_time: 917µs, rocksdb: {block: {cache_hit_count: 492}}} | range:["320282199601025723","320282199601025723"], keep order:false | N/A | N/A |
| └─TableRowIDScan_11(Probe) | 0.00 | 530.55 | 0 | cop[tikv] | table:t_hr | | keep order:false | N/A | N/A |
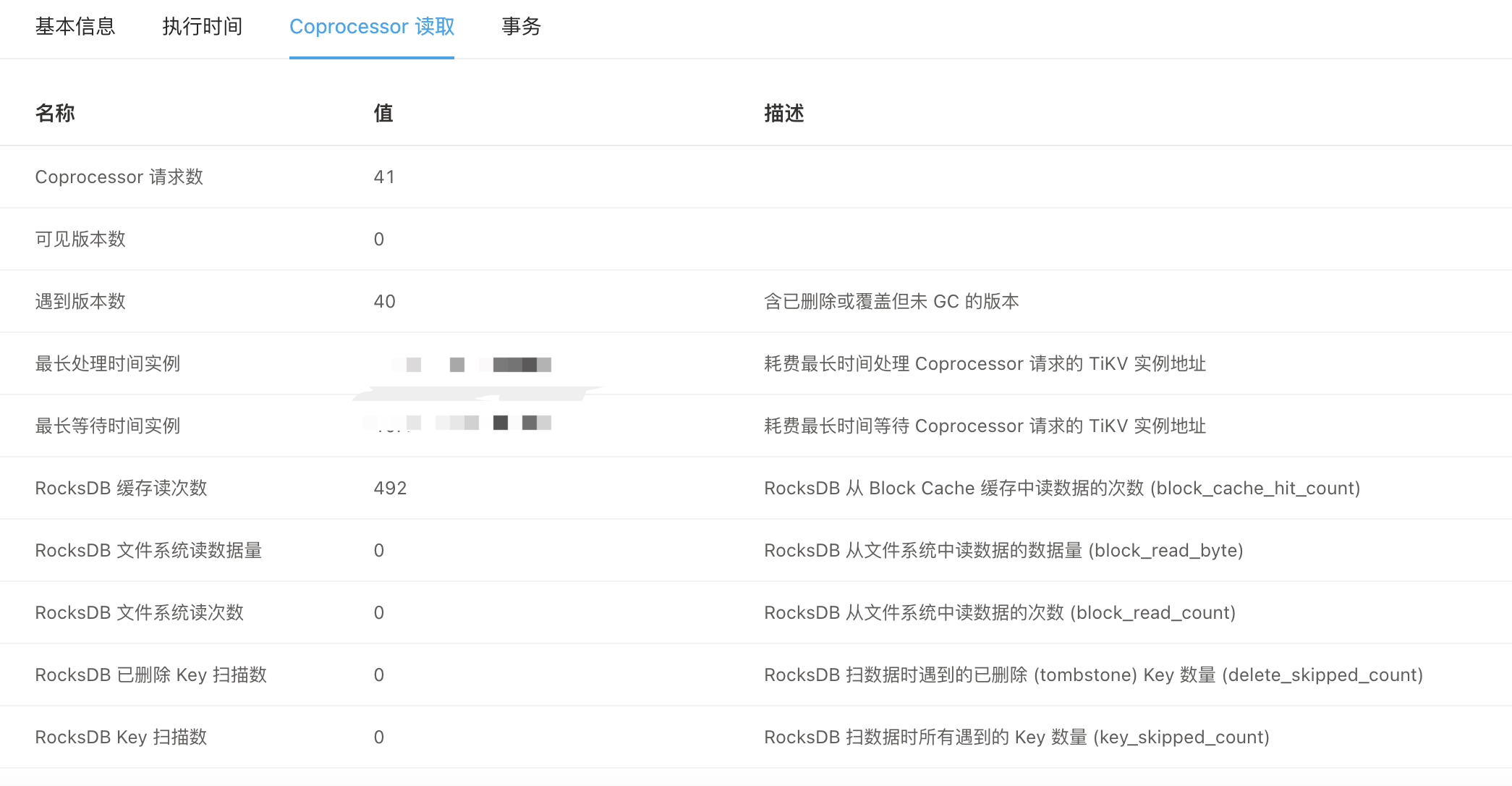
这个计时感觉有点问题,41个cop task, 最大的一个执行要 270.6ms ,但这里记录的51.7ms
1 个赞
先看服务器压力吧,一般协程调度慢和io或者cpu压力有关
没有,即使是命中索引了,也需要过滤行信息的
提供的信息不全
慢查询和索引没有必然联系,一个SQL语句的执行效率最终要看的是扫描行数。
另外可以使用虚拟列和联合索引来提升复杂查询的执行效率。