vcdog
(Vcdog)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】主库集群:v6.5.0 从库集群:v6.1.5
【复现路径】空region数比较大,这个有影响吗,一般是什么情况下,会产生大量的空region
【遇到的问题:问题现象及影响】上游的主库集群的empty region就比较少,下游的从库集群却比较多。正常情况下,主集群上的所有dml操作,都会同步到下游。
上游主库集群:
下游从库集群:
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
zhanggame1
(Ti D Ber G I13ecx U)
2
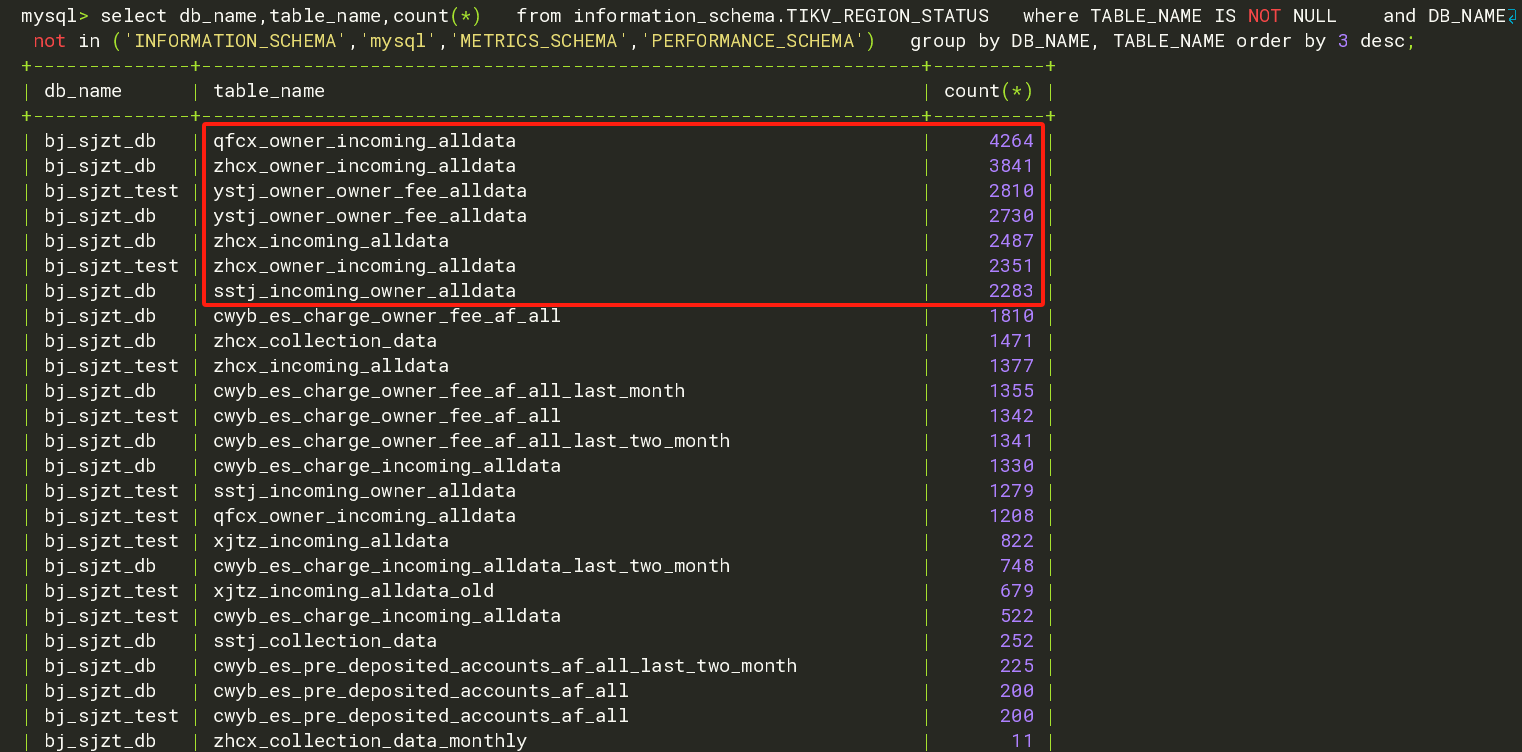
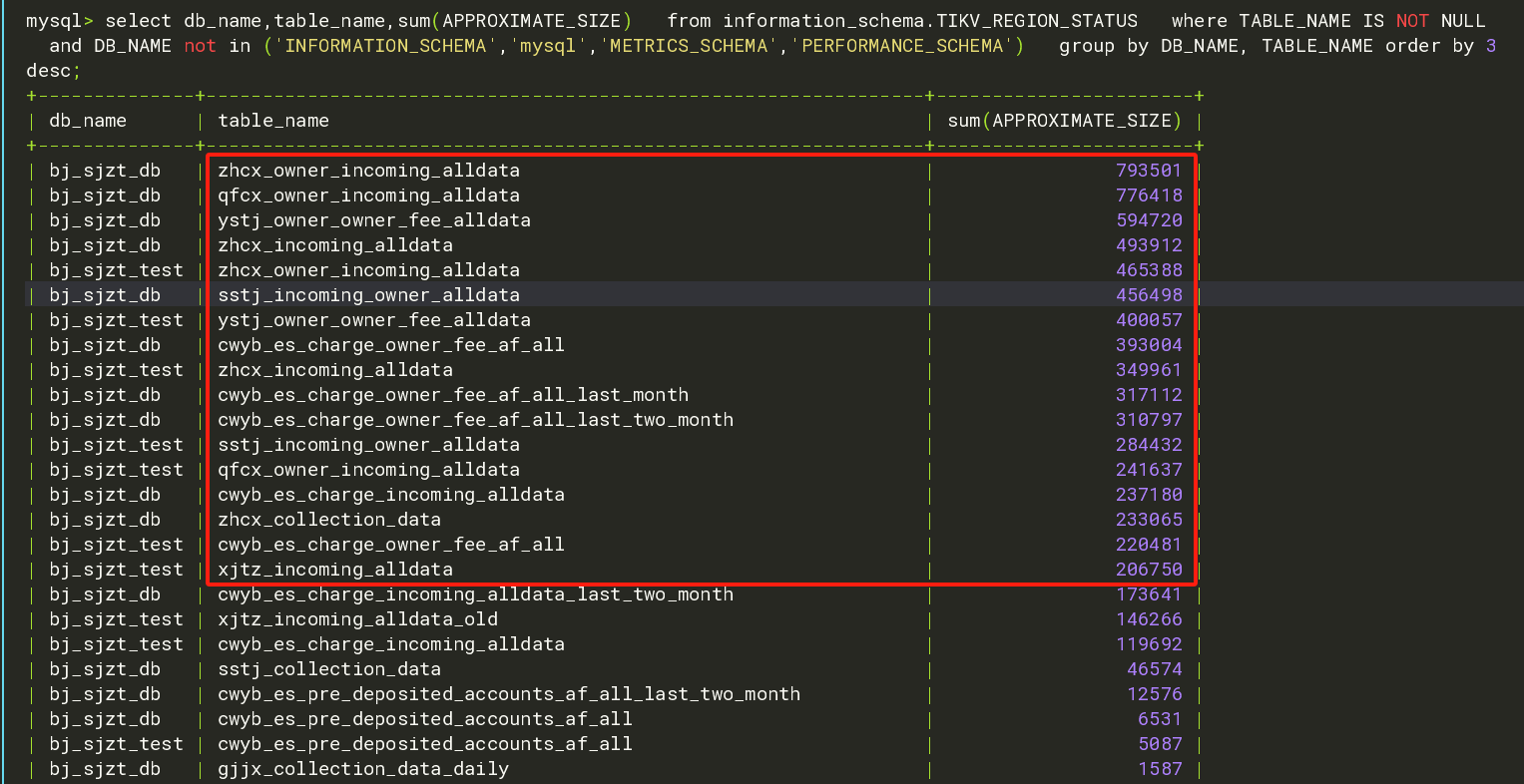
group by下空region 按表名和大小排序看看有什么规律
1 个赞
vcdog
(Vcdog)
3
是查看哪张表,TIKV_STORE_STATUS?
vcdog
(Vcdog)
4
CREATE TABLE TIKV_REGION_STATUS (
REGION_ID bigint(21) DEFAULT NULL,
START_KEY text DEFAULT NULL,
END_KEY text DEFAULT NULL,
TABLE_ID bigint(21) DEFAULT NULL,
DB_NAME varchar(64) DEFAULT NULL,
TABLE_NAME varchar(64) DEFAULT NULL,
IS_INDEX tinyint(1) NOT NULL DEFAULT ‘0’,
INDEX_ID bigint(21) DEFAULT NULL,
INDEX_NAME varchar(64) DEFAULT NULL,
EPOCH_CONF_VER bigint(21) DEFAULT NULL,
EPOCH_VERSION bigint(21) DEFAULT NULL,
WRITTEN_BYTES bigint(21) DEFAULT NULL,
READ_BYTES bigint(21) DEFAULT NULL,
APPROXIMATE_SIZE bigint(21) DEFAULT NULL,
APPROXIMATE_KEYS bigint(21) DEFAULT NULL,
REPLICATIONSTATUS_STATE varchar(64) DEFAULT NULL,
REPLICATIONSTATUS_STATEID bigint(21) DEFAULT NULL
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin;
大佬,是这张表吗?
zhanggame1
(Ti D Ber G I13ecx U)
5
TIKV_REGION_STATUS 对group by DB_NAME, TABLE_NAME 看看 APPROXIMATE_SIZE和regions数量
zhanggame1
(Ti D Ber G I13ecx U)
8
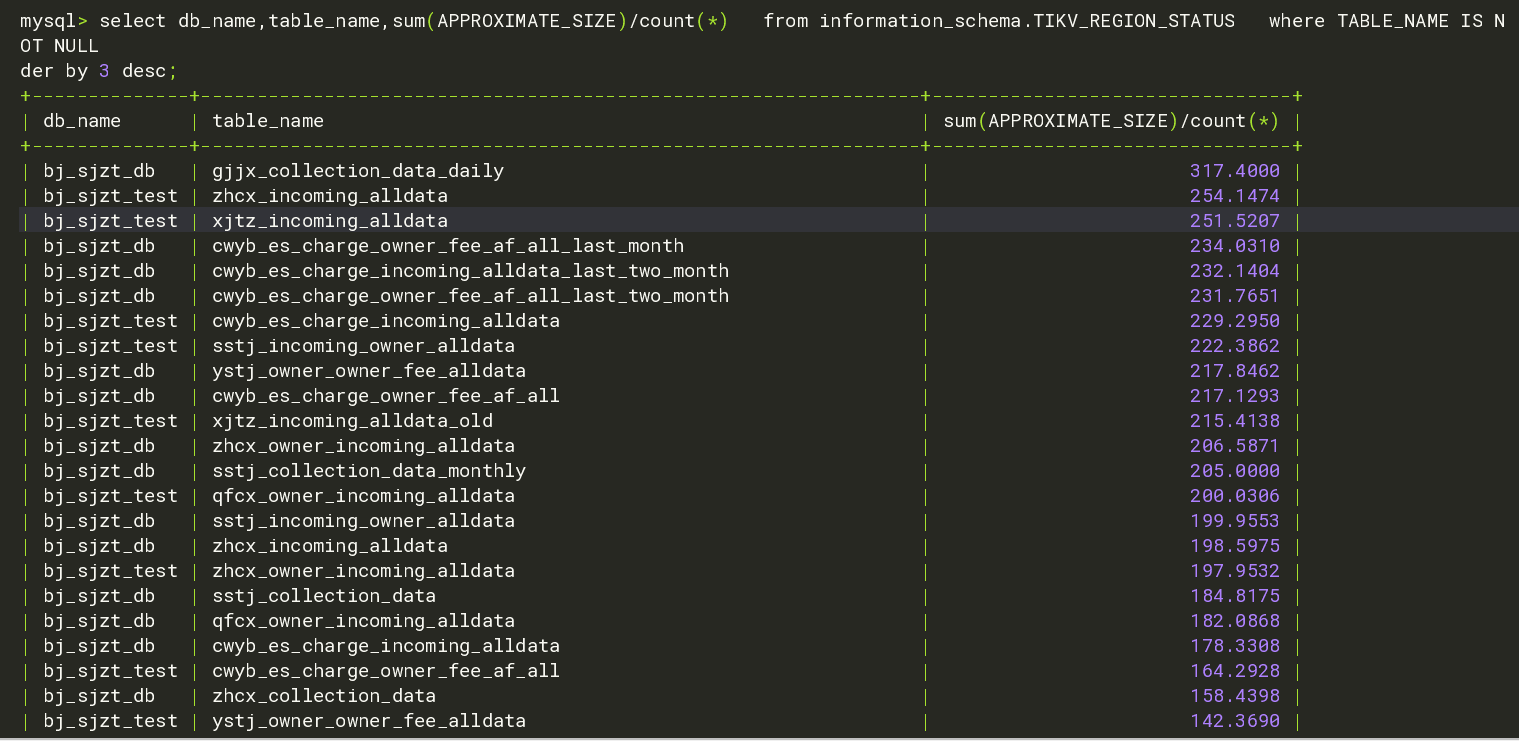
sum(APPROXIMATE_SIZE)/count(*) 看看是不是有的表regions数量多又很小
空region合并下吧,来回的raft心跳也浪费资源
WalterWj
(王军 - PingCAP)
11
默认自动合并,看看 admin show ddl jobs 中 是否有 truncate or drop big table 的操作。
经常有删除操作,导致的?region 自动合并 或分裂。
有猫万事足
14
一般来说是因为分区表。特别是按时间分区的分区表。
有些时间还没到,所以对应的region就没数据,是空的。
然后如果你还在分区表上加了诸如shade_row_id_bits之类的属性,就会产生更多空region。
https://docs.pingcap.com/zh/tidb/stable/table-attributes#使用表属性控制-region-合并
ALTER TABLE t ATTRIBUTES ‘merge_option=deny’;
还有就是通过表属性可以禁止region合并。不过这个比较高级了,一般人不太会设置表属性。
但是可以按这个思路查一查。
miya
(mili)
16
空region一般上因为,region配置参数设置过大,尽管region有数据依然认为是空region.还有就是做了大批量的数据删除造成了空的region。空region会造成region重新负载,做数据迁移,region合并等,所以会影响服务性能。比如:增大cpu,内存,io,带宽的消耗
1 个赞