【 TiDB 使用环境】生产环境
【 TiDB 版本】7.1
【复现路径】
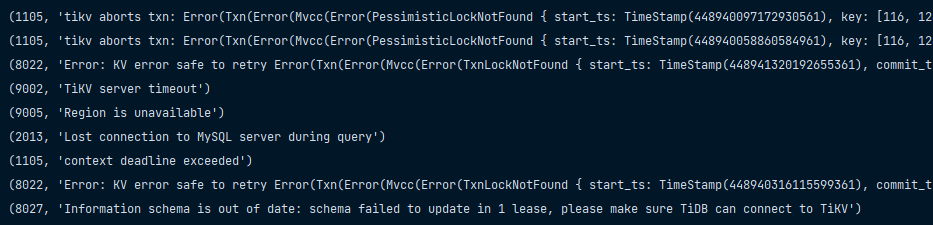
【遇到的问题:问题现象及影响】1、自4月1日开始,发现集群频繁出现短暂的写入异常,TiDB出现多种报错:
2、4月9日对TiDB集群重启,发现5个TiKV结点中的一个CPU高负载,SSH无法连入,根据Grafana日志,该结点在3月25日已经失联。由于SSH无法连入,所以强制关闭了虚拟机重启。
3、TiDB集群重启时,无法快速启动TiKV服务器(任意一个结点都耗时很久),添加了–wait–timeout 3600 参数方才启动集群。
4、集群重启后,其他TiKV结点向原故障结点同步数据进展缓慢,22个小时仅使得原故障结点已用磁盘容量增加了200G。
5、登录各个tikv结点查看tikv.log日志,发现原故障结点频繁报错 failed to recv snapshot,其他Tikv结点报错 failed to send snap

请问如何排查相关原因及解决?
额外的问题:目前整个集群的写入速度变得很慢,4月1日到4月9日,由于故障未能写入的3000条sql语句重新写入花了近1小时。而在3个tikv结点、机械硬盘的测试集群上只用了10来分钟。
4月11日更新:
经过仔细查看日志,发现正常集群一直在尝试发送同一个或几个region的快照时失败。
[ERROR] [snap.rs:546] [“failed to send snap”] [err=“Grpc(RpcFinished(Some(RpcStatus { code: 1-CANCELLED, message: "CANCELLED", details: })))”] [region_id=1352555781] [to_addr=192.168.10.11:20160]
是不是这个peer在目标节点上已经没了?你根据region看看,是不是这个region的3个peer已经在其他机器补齐了?
都是内网,故障结点与其他结点互ping都是0.1毫秒左右
你想提升速度的话,调大store limit 就行了。单独调大这个节点的 add-peer。调大其他节点的remove-peer
现在有个问题就是整个集群的写入速度变得很慢,4月1日到4月9日,由于故障未能写入的3000条sql语句重新写入花了近1小时。而在3个tikv结点、机械硬盘的测试集群上只用了10来分钟。
写入慢的话还得再看看,比如说是不是不断的重试。你那个故障节点上还有leader吗?实在不行把leader驱逐,看看写入速度是不是快了一些。
show config where name like ‘%high-space-ratio%’;
show config where name like ‘%low-space-ratio%’;
你的集群空间是不是不太足了,把这俩参数都调大一点吧
leader挺平均的。我想是不是直接把这个结点缩容掉再扩容回来会更好些?
这两个的值分别为0.7和0.8,每个正常Tikv结点都还有约780G/4.4T的剩余磁盘空间,如果有需要可以再扩容几个TiKV结点
这里介绍不了我
(持续学习)
12
看一下这个TiKV的打分是不是相对别的节点低很多呢
看看tidb的log,如果总是关于这个故障节点的报错,可以重建,不过删掉前从pd的页面看看有没有missing-peer 。
我建议另外找台机器扩容一个tikv节点,然后把这个故障的tikv节点缩容掉吧,先不要在这台机器上原地扩容
h5n1
(H5n1)
18
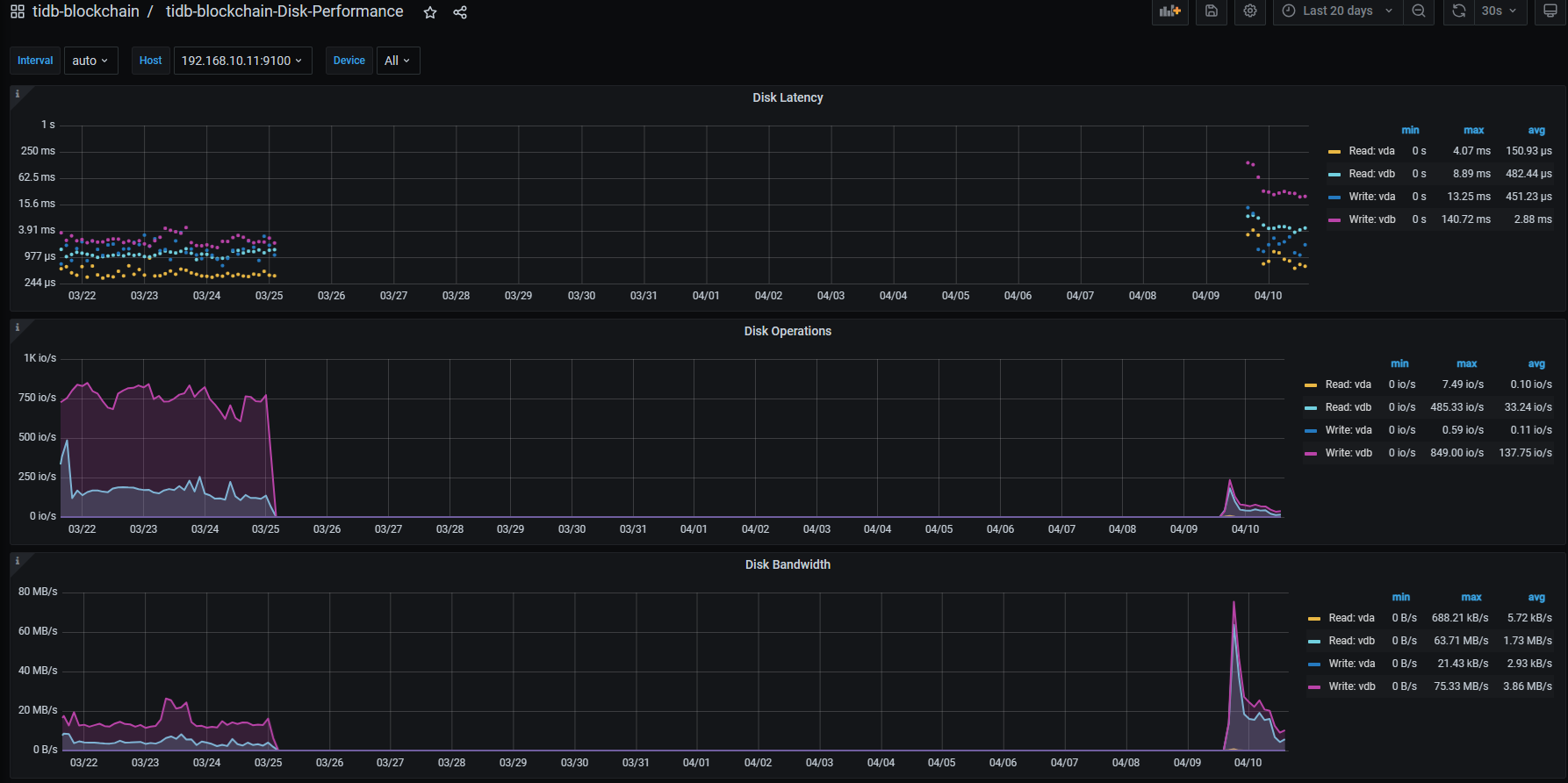
用的虚拟机,有没有检查虚拟机和宿主机有没有问题,比如磁盘性能 CPU 等
有考虑这一块,因为之前几个tikv结点在集群启动时,log都有打出 no ssd device,集群中都是nvme ssd。目前因为服务器运维人员不在,还没啥方案检查磁盘性能。