【 TiDB 使用环境】生产环境
【 TiDB 版本】 6.5.4
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
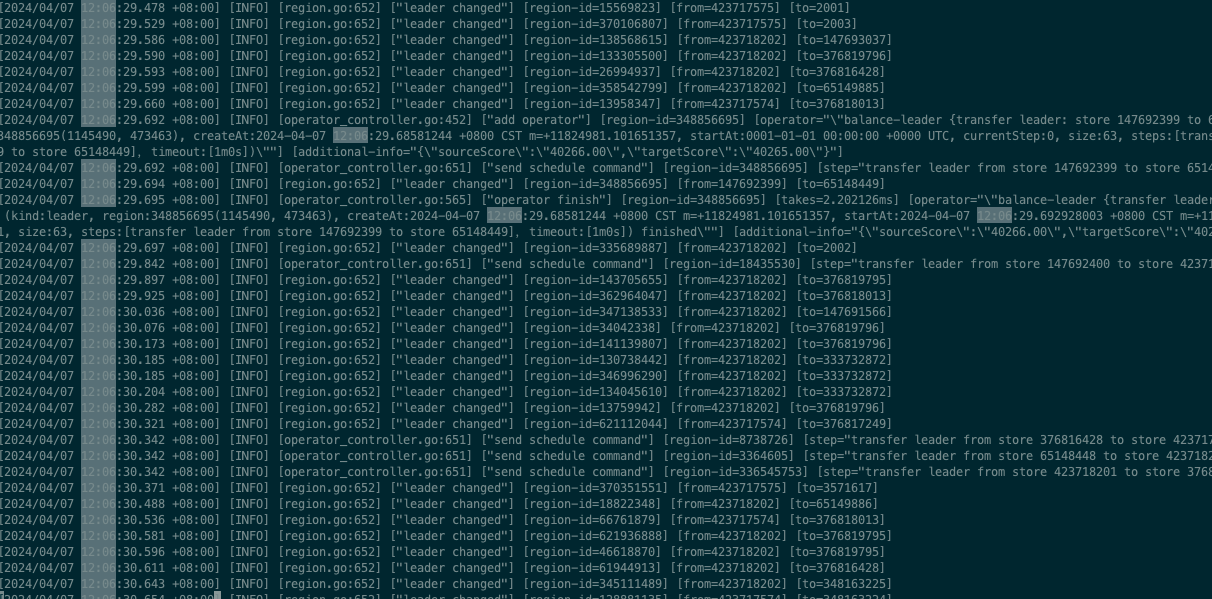
12:30时 发现 dashboard上 发现有2个机器上,4个tikv节点(打了label),显示(disconnet) 有时又是up状态
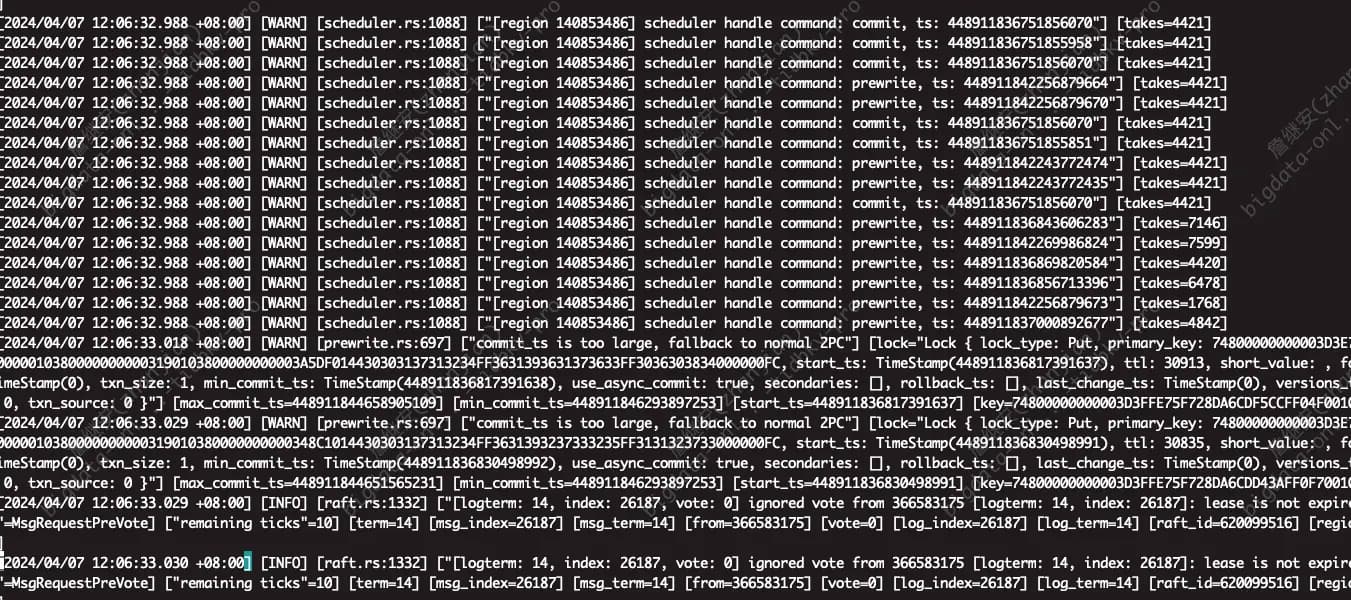
期间查询部分sql 会报错 region 不可用的错误, 然后发现 集群从12点06开始,不可写入
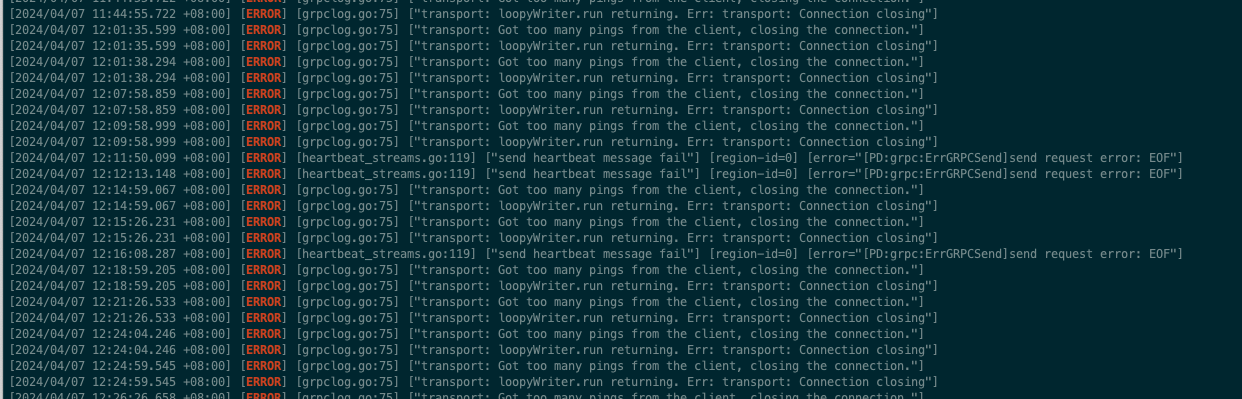
查看12:06有这样一批warn日志,没有查到其他特殊日志
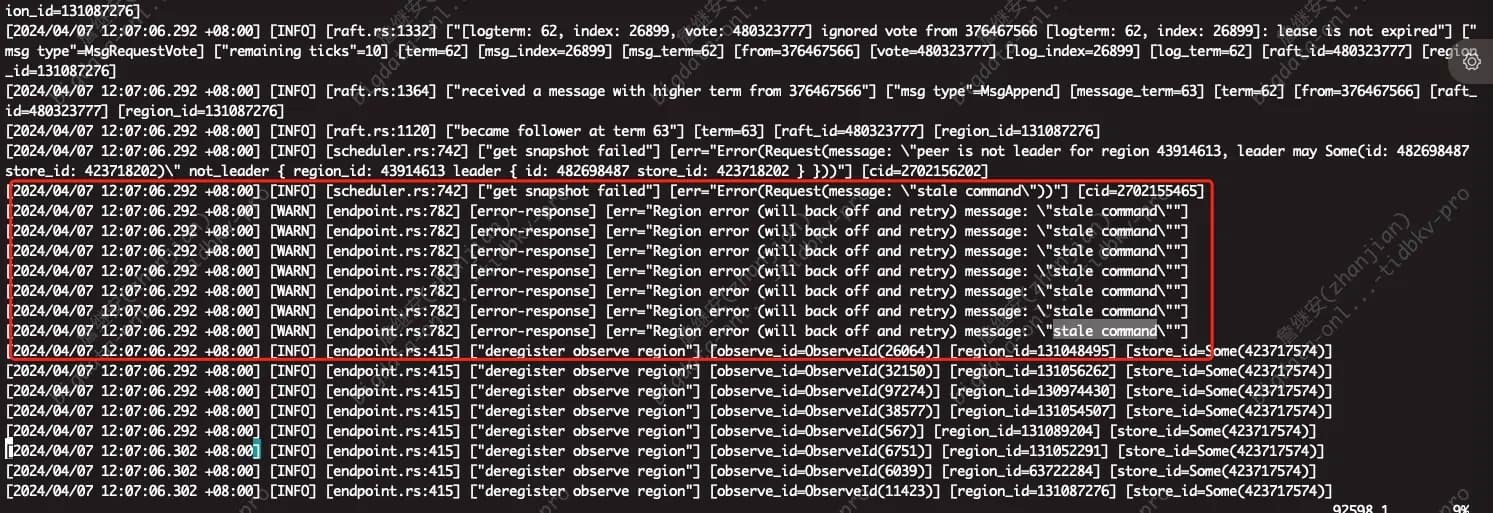
然后集群 就region不可用
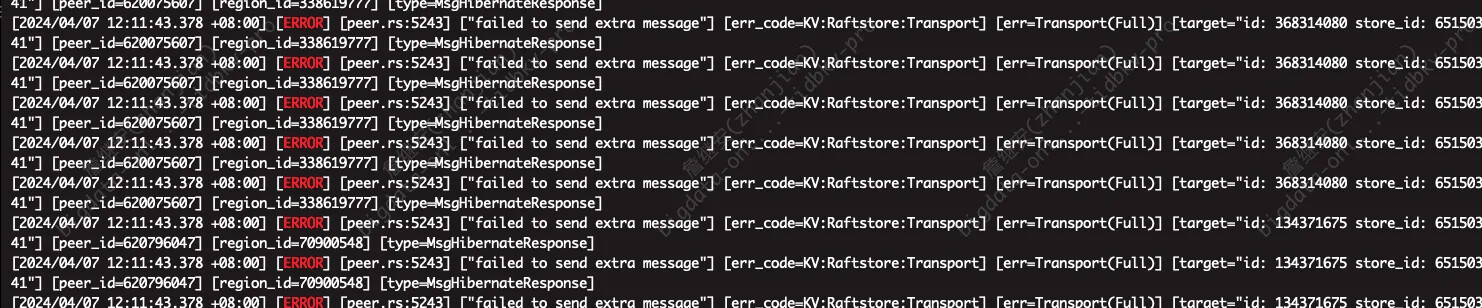
最后在一直 狂打日志,
中间尝试过通过命令重启 无效
最有在14:00的时候,重启服务器。 然后在14:15恢复了 可以写入 不知道最后是自恢复还是啥
想请问下。什么情况那一批定时任务是干嘛用的, 或者有其他排查方法不
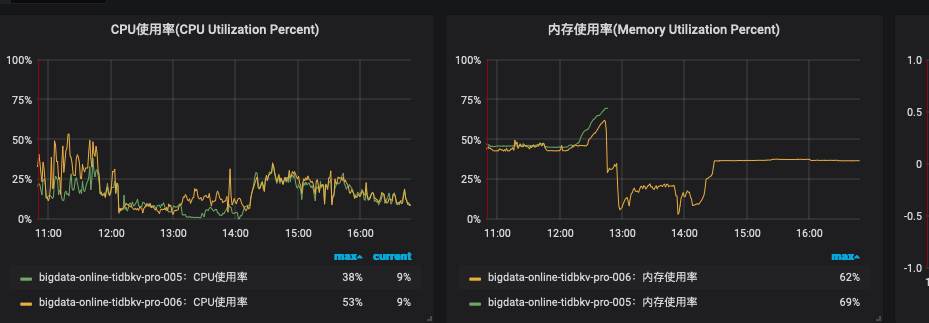
这是2台 机器的资源使用情况
cpu有点奇怪,12:06开始 到12:10分 使用率直接掉没了,内存倒是上升了
DBAER
(66666)
8
这个有点奇怪,cpu 下降了,应该没有资源不够用的情况,我看日志好像有region 没有leader ,等大佬分析吧。
监控只有最近3小时的 数据已经没了 [quote=“Kamner, post:6, topic:1024268, full:true”]
Ming
11
tikv有多次重启吗,对应的tikv日志搜索Welcom能搜到东西吗?
可以搜到 其中一个kv节点
[2024/04/07 13:14:40.820 +08:00] [INFO] [lib.rs:85] [“Welcome to TiKV”]
[2024/04/07 14:01:56.828 +08:00] [INFO] [lib.rs:85] [“Welcome to TiKV”]
但是这个第一次应该是命令重启 第二次重启服务器的
Ming
13
看到12点50应该是?那个时间内存使用上升之后急速下降,像是节点宕掉或者有其他服务挂掉了一样。
但是没看懂为啥这个监控 13点以后收集不到其中一台服务器的内存使用了呢。
另外一个我 也不清楚为啥没内存,有可能跟05机器手动启动服务器有关,导致一些ecs监控没自起
这个对应06 机器对应的日志
[2024/04/07 12:51:50.149 +08:00] [INFO] [lib.rs:85] [“Welcome to TiKV”]
[2024/04/07 12:56:24.206 +08:00] [INFO] [lib.rs:85] [“Welcome to TiKV”]
[2024/04/07 13:53:06.783 +08:00] [INFO] [lib.rs:85] [“Welcome to TiKV”]
今天我的测试环境超级慢。直接说结果,tidb 和pd 是混合部署 各3节点。都是云主机 其中 一个节点机器被同事降了配置。之前是16G 降为8GB。这个节点缩容了tidb 只保留了pd。然后卡顿慢的现象就消失了。感觉不至于,现象确实这样。 会不会因为同样的服务所在的机器配置差距导致?
DBAER
(66666)
18
1 个赞