【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.2
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
Tikv TiFlash cpu百分之百,扩容后,发现部分表出现只有id,其他字段都是空的问题
cpu100%的图片:
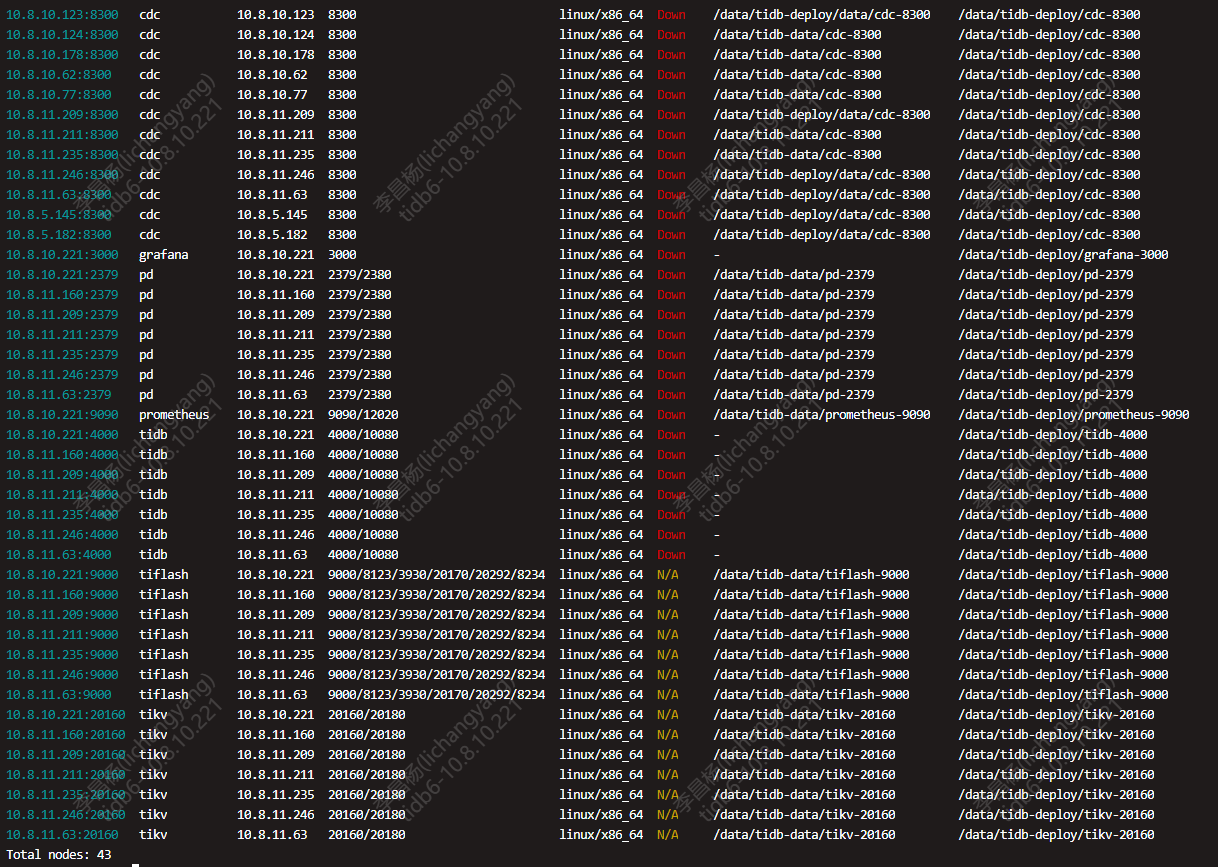
重启后Tikv,tiflash时,状态为N/A,无法得知状态
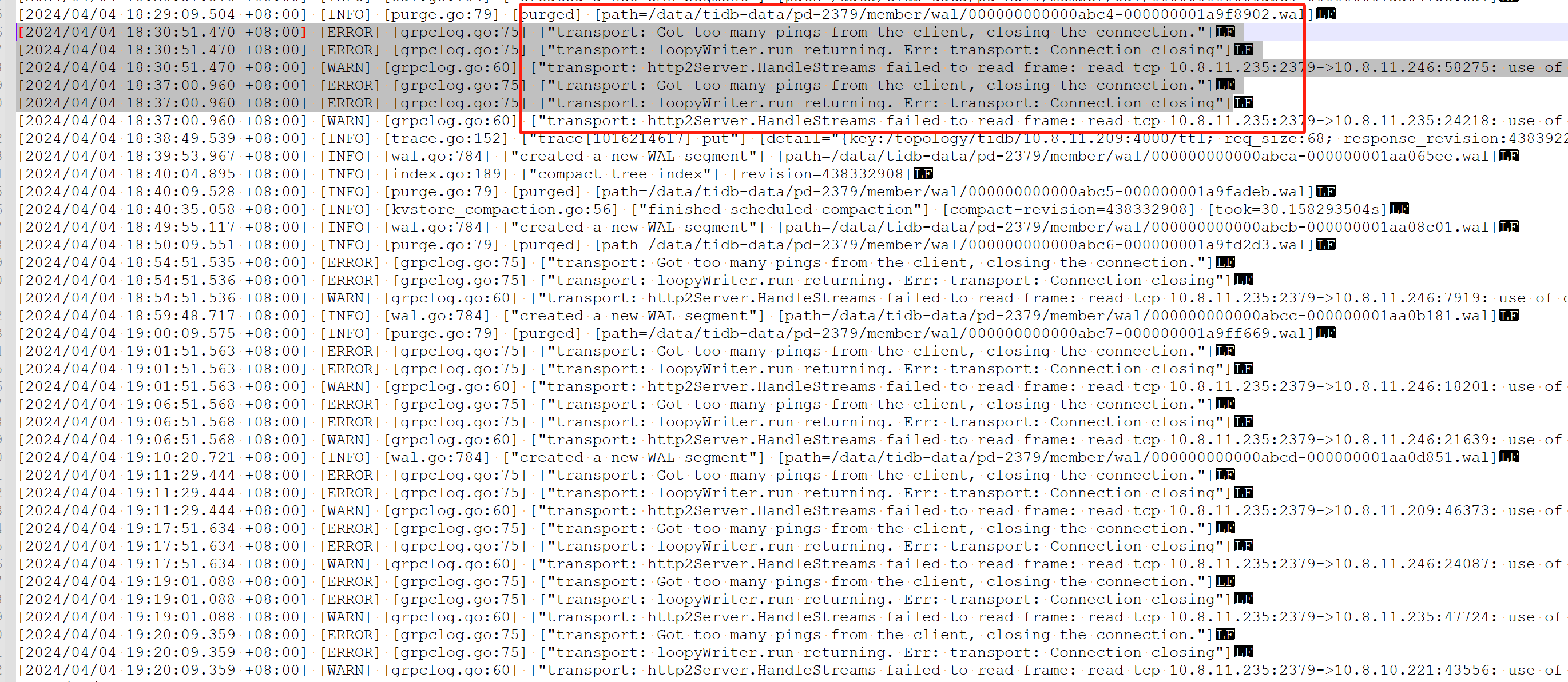
查看system info 监控,发现网路和tcp有异常:
pd的错误日志:
然后进行扩容,重启之后,发现业务数据不正常,出现了大量只有id,其他数据全是空的情况,数据丢失了。如下所示:
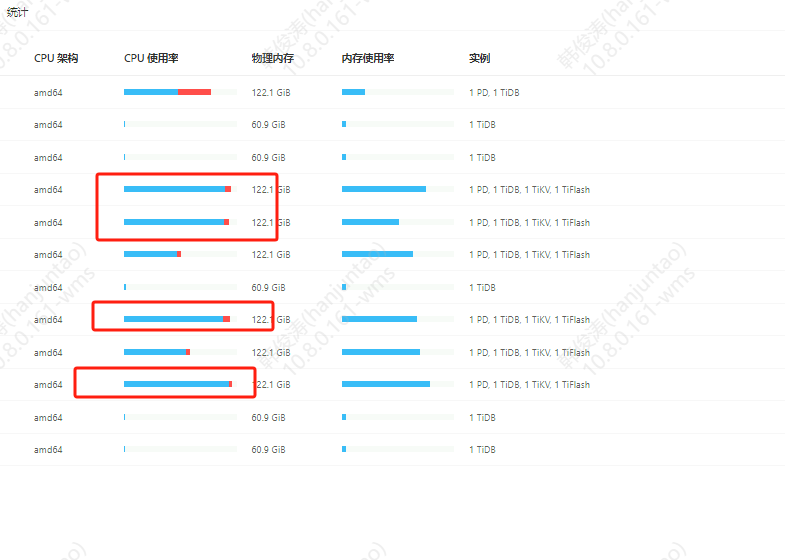
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
集群宕机了,tikv和tiflash所在的节点,cpu全部100%了
有猫万事足
5
7个pd?
其中6个pd都和tikv和tiflash放一起,这个部署方式是不推荐的。
pd容易抢不到cpu执行时间。
pd只建议和tidb放一起。
我现在感觉是pd就没起来。
所以整个集群就一直起不来。
tikv tiflash 都建议独立部署。 tidb和pd可以混合部署。
DBAER
(66666)
9
这争抢资源了,tikv 和tiflash 混部署在一个主机了,还有为啥这么多pd,是什么架构设计啊
友利奈绪
10
tikv 和tiflash 混部署在一个主机了争抢资源
你这种拓扑方式是咋想的,122G那几台机器部署pd+tidb+tikv+tiflash。。。。还不如找2台机器单独部署tiflash,tidb和pd单独部署在60G内存机器,剩下的122G机器部署2个tikv呢。。。。
tiflash很容易占用全服务器的cpu,这样的话万一你的pd+leader也在这台机器上,很可能导致pd挂死。。。。
你现在启动连pd都起不来,tikv和tiflash肯定起不来了。。。你可以试试单独启动pd看能起来不。。。
Shanks
(Ti D Ber J Ui6 Uv Zm)
13
TiKV 与 TiFlash 没有做资源隔离, 然后 Region 又大量分布在这6台机器上,导致 TP 和 AP 全面资源竞争。大概率这个是主因吧
Shanks
(Ti D Ber J Ui6 Uv Zm)
14
你这个扩容主要扩了什么东西?扩容前,cpu 使用是否正常?业务是否正常?数据是否存在问题?另外,能不能从日志看出报错情况?
Shanks
(Ti D Ber J Ui6 Uv Zm)
15
当务之急是尽快排查清楚数据影响范围。数据是否还有备份,是否需要恢复,该如何恢复。后续建议把 TiKV 与 TiFlask 分开。建议遵循官方的部署建议。
这个部署拓扑结构一言难尽,现在扩容后重启后,数据库正常了,数据丢失,正在补数据,后续需要赶紧调整部署架构了。目前运维正在查找问题原因,事故影响范围很大 
问题描述上面贴了pd 的错误日志,出问题的时间点,有大量的错误日志
现在就有一个地方非常好奇,为啥tidb底层数据会丢失,表里面的数据只有id,其他的字段都为空,现在没有合理的解释,也没有搜索到
托马斯滑板鞋
(托马斯滑板鞋)
19
把tiflash replica 置为0,再查,看看数据还在不
你把业务的sql手工放到tidb-server上执行下,看看会发生这种情况吗?