获取纳斯达克100的所有股票id
import requests
from bs4 import BeautifulSoup
# 设置请求头部信息
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36"
}
# 发送GET请求
res = requests.get("https://api.nasdaq.com/api/quote/list-type/nasdaq100", headers=headers)
# 解析JSON数据
main_data = res.json()['data']['data']['rows']
# 打印公司名称
for i in range(len(main_data)):
print(main_data[i]['symbol'])
import yfinance as yf
import pandas as pd
import mysql.connector
from sqlalchemy import create_engine
# 定义纳斯达克前100家公司的股票代码列表
nasdaq_top_100 = [ ] # 请补全列表
import requests
from bs4 import BeautifulSoup
# 设置请求头部信息
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36"
}
# 发送GET请求
res = requests.get("https://api.nasdaq.com/api/quote/list-type/nasdaq100", headers=headers)
# 解析JSON数据
main_data = res.json()['data']['data']['rows']
# 打印公司名称
for i in range(len(main_data)):
print(main_data[i]['symbol'])
nasdaq_top_100.append(main_data[i]['symbol'])
# 创建一个空的列表来存储每家公司的DataFrame
dataframes = []
# 遍历股票代码列表
for ticker in nasdaq_top_100:
# 获取股票数据
stock = yf.Ticker(ticker)
# 获取财务报表数据
balance_sheet = stock.balance_sheet
income_statement = stock.financials
# 计算ROE
net_income = income_statement.loc['Net Income']
shareholder_equity = balance_sheet.loc['Stockholders Equity']
roe = net_income / shareholder_equity
# 创建一个DataFrame来存储当前公司的ROE
df = pd.DataFrame({'Ticker': [ticker], 'ROE': [roe]})
# 将DataFrame添加到列表中
dataframes.append(df)
# 使用pd.concat合并所有公司的DataFrame
roe_df = pd.concat(dataframes)
# 输出结果
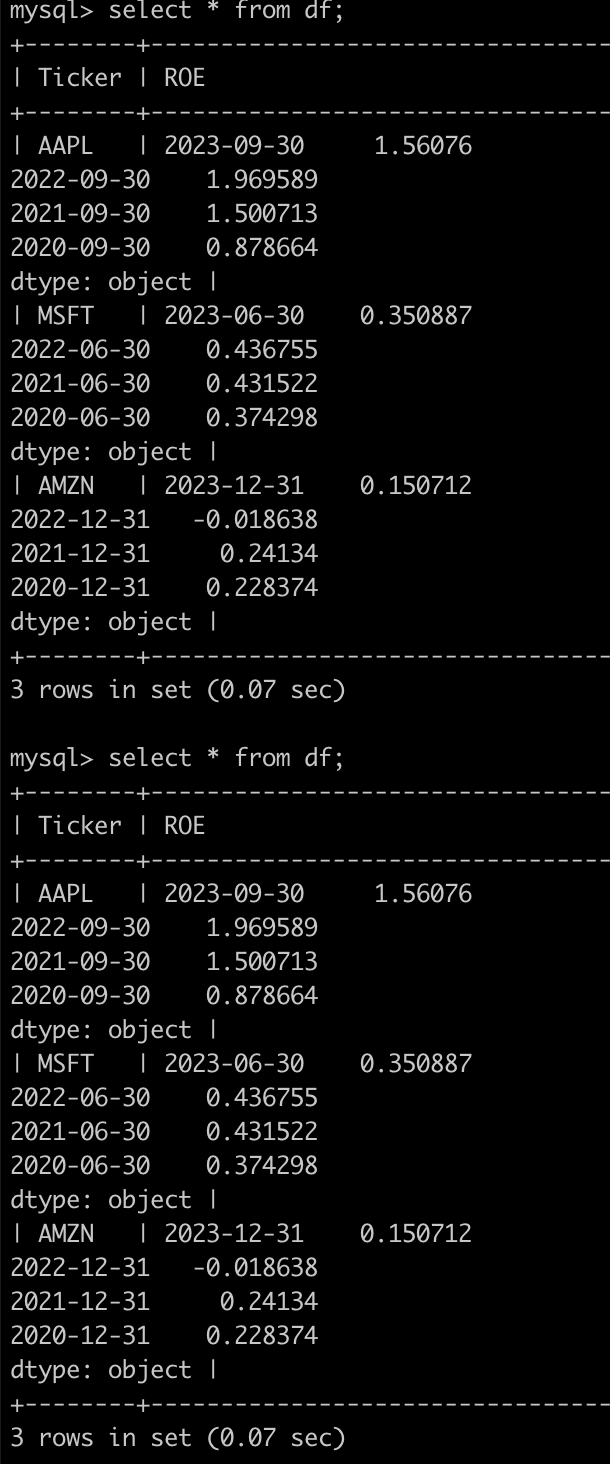
print(roe_df)
#url = 'mysql+pymysql://username:password@hostname:port/dbname?charset=utf8'
#engine = sa.create_engine(url, echo=False)
engine = create_engine('mysql+pymysql://username:password@ip/test')
roe_df.to_sql('df', engine, index=False,
method = "multi",chunksize = 10000 ,if_exists='replace')
文章结尾