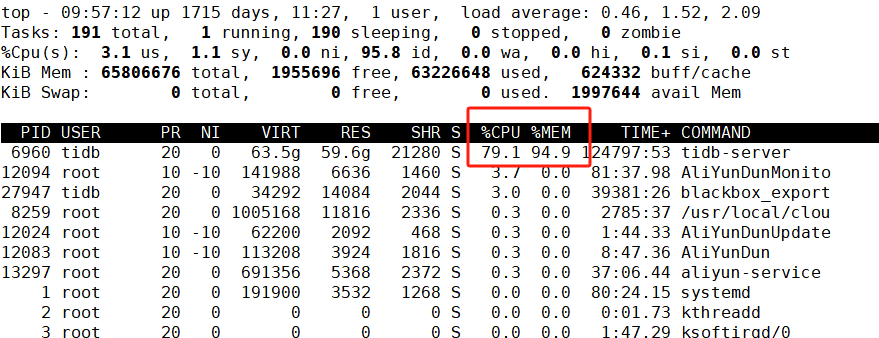
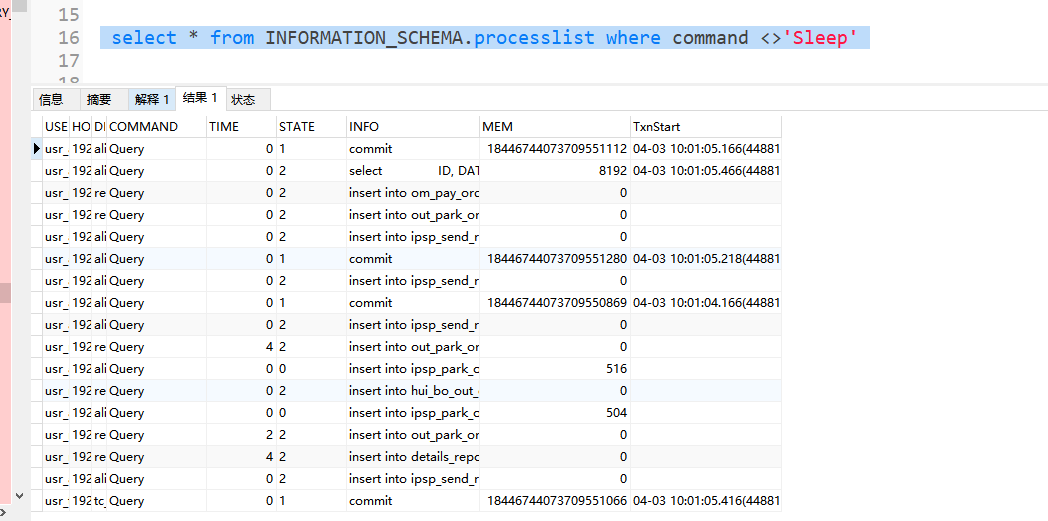
刚刚9点30收到告警tidb其中1台内存使用达到98% ,我去tidb查看当前执行的会话连接,没有一个超过100s的进程,都是正常的sql运行。memm使用多的看起来全部都是commit。整体看起来没啥问题。
1 个赞
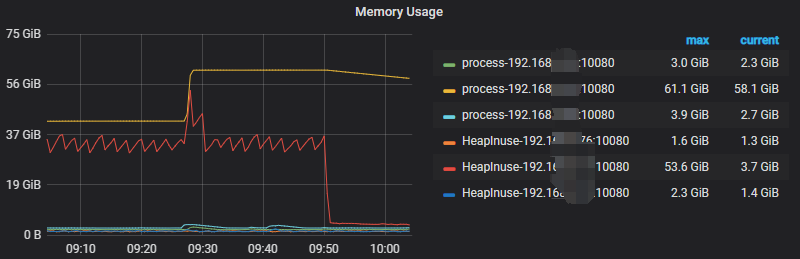
grafana上 内存指标
看看dashboard慢查询呢
看看dashboard的top sql呢
1 个赞
慢语句?
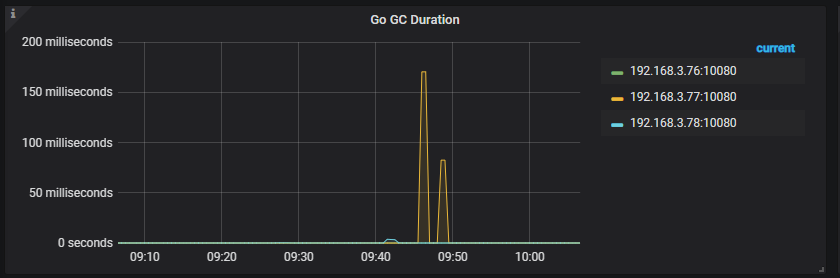

你这插入数据怎么那么慢,磁盘io正常吗??
好几年了,一直都是这么慢,这里面十几个库,都是大事务的。磁盘IO都是阿里云SSD
你这集群明显不堪重负了
阿里云的ssd是本地盘吗?ssd云盘的性能完全不行和本地盘天差地别。
看 日志 expensive_query 有这个关键字不
https://docs.pingcap.com/zh/tidb/stable/configure-memory-usage#tidb-内存控制文档
都是本地盘。数据量大,40多T,30个tikv服务器。

现在正在慢慢降低。暂时没找出来哪里使用特别高的slq和进程
看这个节点的资源都被insert占用了,几个tidb节点啊?没做负载均衡吗?
做了负载。3个tidb。insert有业务大量的,不过同时还有我的两个删历史数据的,删历史数据在另一个tidb节点。大概10s左右删1w条 limit1000删的。24小时不停地删除呢。
下次再长可以这样抓下heap: curl -G tidb_ip:4000/debug/pprof/heap > heap.profile
1 个赞
有条件还是扩下tidb节点吧,别oom影响系统使用了
![]() 最近再删数据。就是想要缩容。减少支出呢。。
最近再删数据。就是想要缩容。减少支出呢。。