[
分布式系统的历史
](#%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F%E7%9A%84%E5%8E%86%E5%8F%B2)
2006年,谷歌推出了大数据的三驾马车:
* GFS -- 解决了分布式文件系统问题
* Google BigTable - 分布式key-value问题
* Google MapReduce - 解决了在分布式文件系统和分布式KV存储上如何做分布式计算和分析问题。
分布式计算的主要挑战
* 如何最大程度的实现分治
* 如何实现全局的一致性
* 如何进行故障与部分失效的容错
* 如何应对不可靠的网络与网络分区
分布式系统里著名的CAP理论
- Consistency(一致性) - 副本一致性
- Avaliability(可用性)
- Portition Tolerance(分区容忍性)
- CA、CP、AP
事务:ACID
两个一致性不一样:前者描述的是副本的一致性,后者是事务的一致性。
RPO: 数据恢复点目标,主要指业务系统所能容忍的数据丢失量。
RTO: 恢复时间目标 ,主要指的是所能容忍的业务停止服务的最长时间。
[
TiDB 高度分层架构
](tidb%20%E9%AB%98%E5%BA%A6%E5%88%86%E5%B1%82%E6%9E%B6%E6%9E%84)

弹性是整个架构设计的核心考量点,从逻辑上将TiDB主要分为三层:
* 支持标准SQL的技术引擎 - TIDB Server
* 分布式存储引擎 - TiKV
- 元信息管理与调度引擎 - Placement Driver(PD)
- 集群的元数据管理,包括分片的分布、拓扑结构等
- 分布式事务ID的分配
- 调度中心
数据库核心:数据结构
Tikv 单节点选择了基于LSM-tree的RocksDB引擎:
- RocksDB是一款非常成熟的LSM-tree存储引擎
- 支持批量写入(Atomic batch write)
- 无锁快照读(Snapshot)
- 这个功能在数据副本迁移过程会起到作用。
[
TiKV
](TiKV)
TiKV系统采用范围(range)数据分片算法。
分布式事务模型
- 去中心化的两阶段提交
- 通过PD全局授时(TSO)
- –4M timestamps 每秒
- 每个TiKV节点分配单独区域存放锁信息(CF Lock)
- Google Percolator事务模型
- TiKV支持完整事务KV API
- 默认乐观事务模型
- 也支持悲观事务模型(3.0+版本)
- 默认隔离级别: Snapshot Isolation
SQL关系模型
在KV上实现逻辑表:
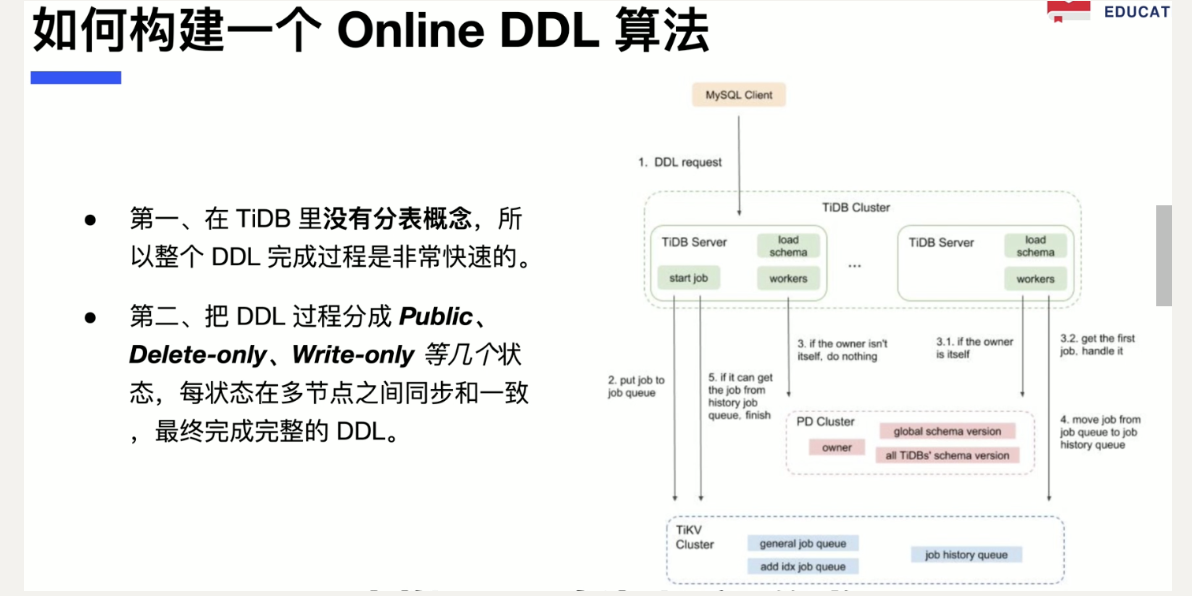


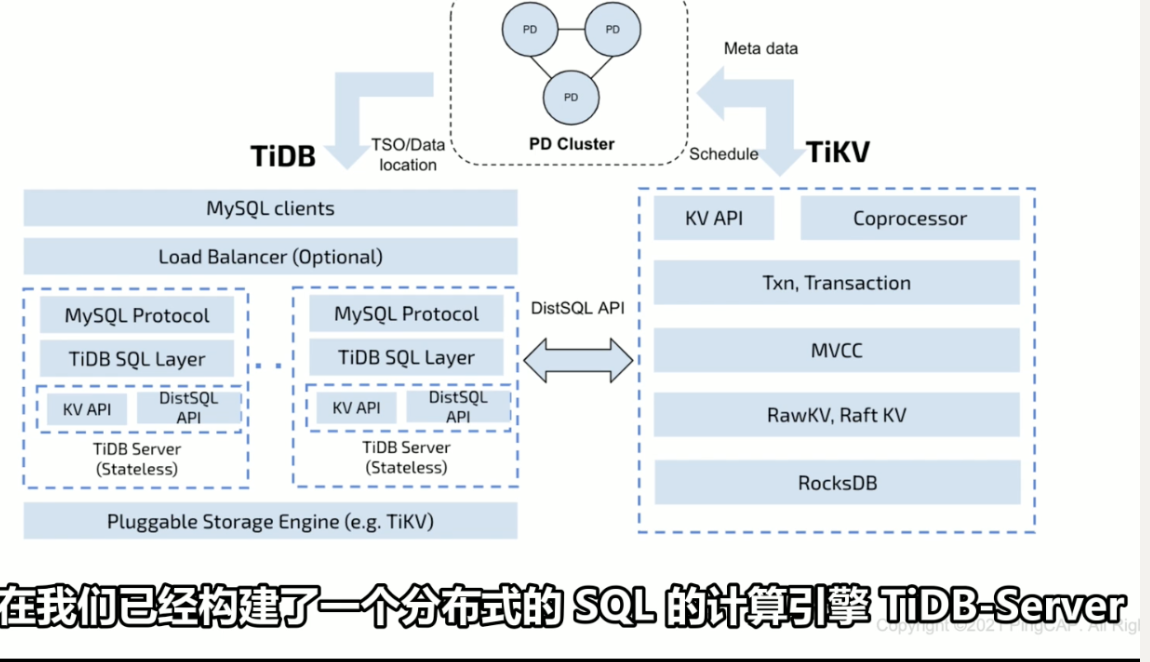
HTAP

spark来缓解数据中台算力问题: 只能提供低并发的重量级查询。
物理隔离是最好的资源隔离
列存天然对OLAP查询类友好 - Tiflash
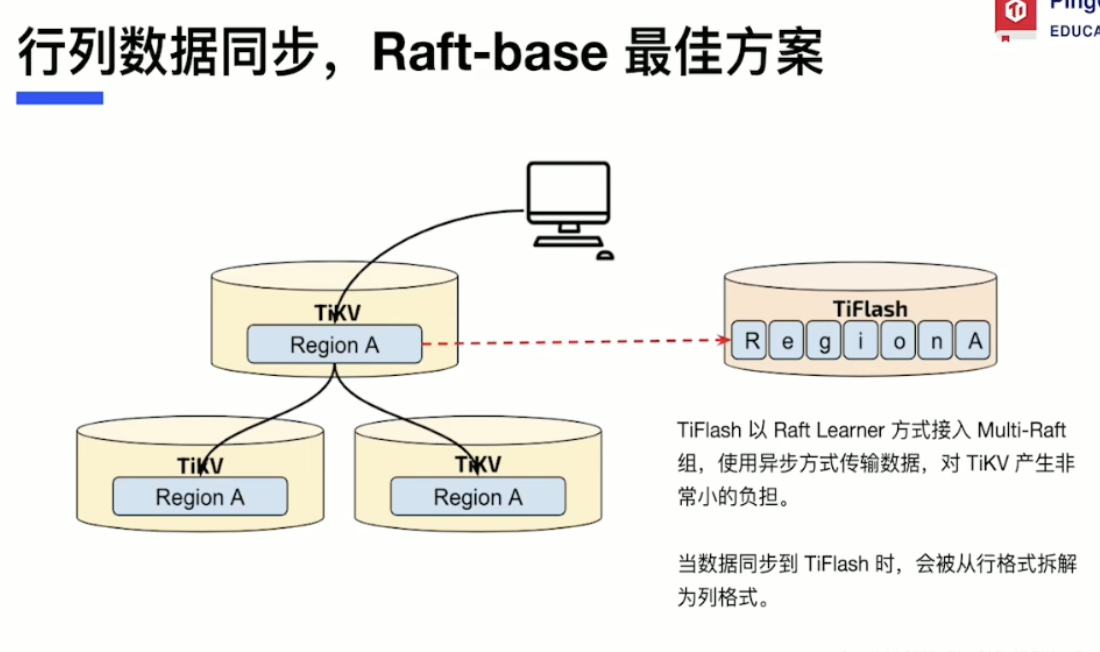
行列数据同步 - Raft-base最佳方案
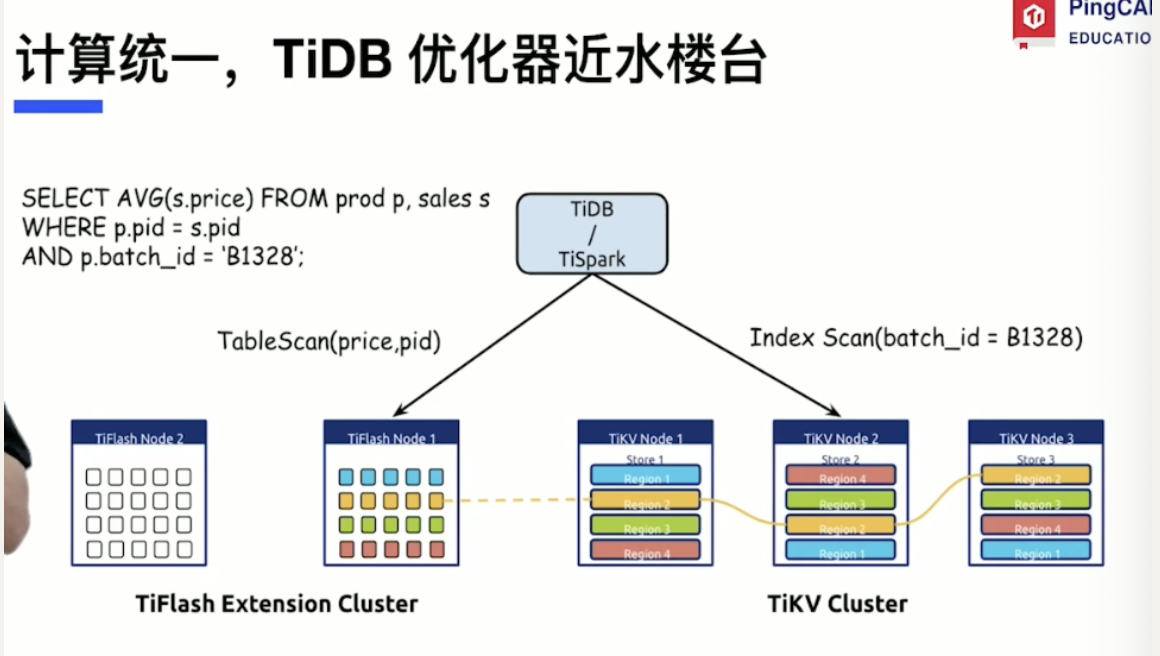
MPP引擎 -并行计算

TiDB数据库在HTAP的技术方已经实现的功能:
- 列式存储实现了实时写入能力
- MPP解决节点的扩展性与并行计算
- 使spark运行在TiKV上。