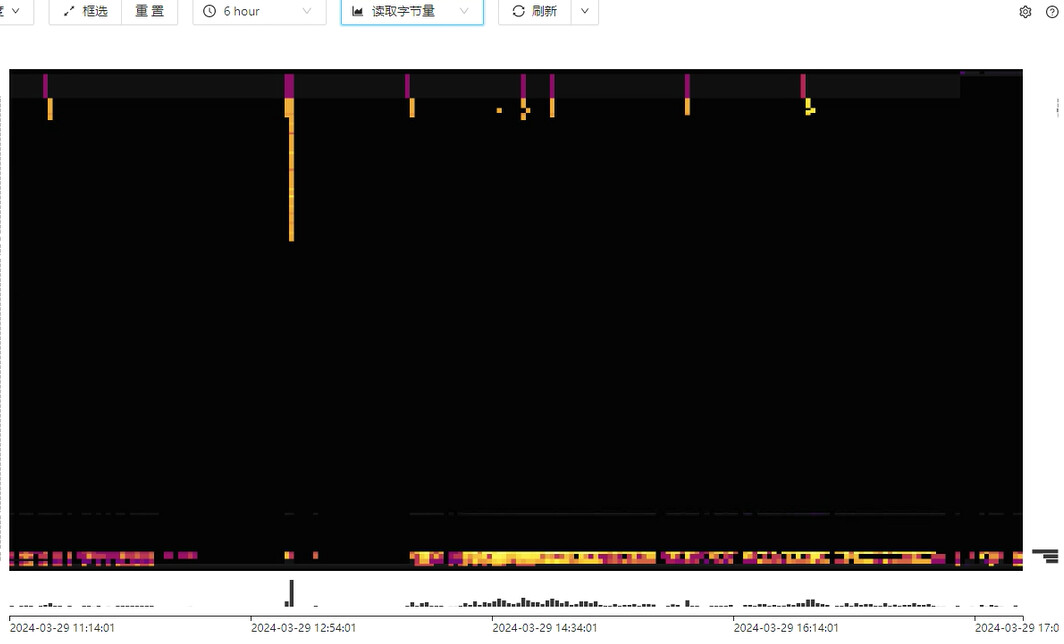
看最亮的地方,每分钟多少流量
那里看出来热点了,这个图里亮度是相对的,不能说看到亮的就说是热点啊
120M
那这个热点如何判断,根据每分钟读取的流量吗?
热点是相对的,只要你的 TiKV 节点能扛的住就行,如果是正常业务 120 M 也没问题,一般啥时候看这个热力图,一般发现各 TiKV 节点负载不均衡,读线程池有严重的倾斜的时候再看这个
读取热点可能是读取的数据都集中到一台机器了,说明存储的数据不均衡,region没有打散,导致某台机器负载过高
1.可以将数据读取修改为flower read,利用多个副本分片,提升读的能力 2.将数据打散利用tidb多个节点提升访问性能 但以上每一种都要创建索引提升查询性能。另外线上也可先通过应用关闭功能访问,直到在测试验证通过后再恢复功能
消除读热点的常用办法:
- 垂直拆分(Vertical Splitting):将热点表按照业务逻辑进行拆分,将热点数据分散到不同的表中。这样可以减少单个表的读压力,提高整体的读取性能。
- 水平拆分(Horizontal Splitting):将热点表按照某个字段进行拆分,将数据分散到不同的分区或分片中。这样可以将读请求分散到不同的节点上,减轻单个节点的读压力。
- 缓存(Caching):使用缓存技术,如Redis或Memcached,将热点数据缓存起来。这样可以减少对数据库的读取请求,提高读取性能。
- 负载均衡(Load Balancing):使用负载均衡器将读请求均匀地分发到不同的TiDB节点上。这样可以避免单个节点的过载,提高整体的读取性能。
- TiFlash:TiFlash是TiDB的列式存储引擎,可以用于存储和查询热点数据。将热点数据存储在TiFlash中,可以减轻TiDB节点的读压力,提高读取性能。
- 数据预分区(Pre-splitting):在创建表时,根据热点数据的分布情况,预先将数据分散到不同的分区中。这样可以避免数据倾斜,提高读取性能。
- 优化查询语句:通过优化查询语句,使用合适的索引、避免全表扫描等方式,减少对热点数据的读取压力。
另外我少回答了一个。tidb高版本也可以使用小表缓存,但是缓存主要应对变更不频繁的数据。因为一旦更新数据,缓存就会失效,又会到tidb中查询数据,造成热点
今天有一个表到了1.2G了,但是tikv节点能抗住 这个tikv节点负载不均衡,读写线程池在哪看呢?
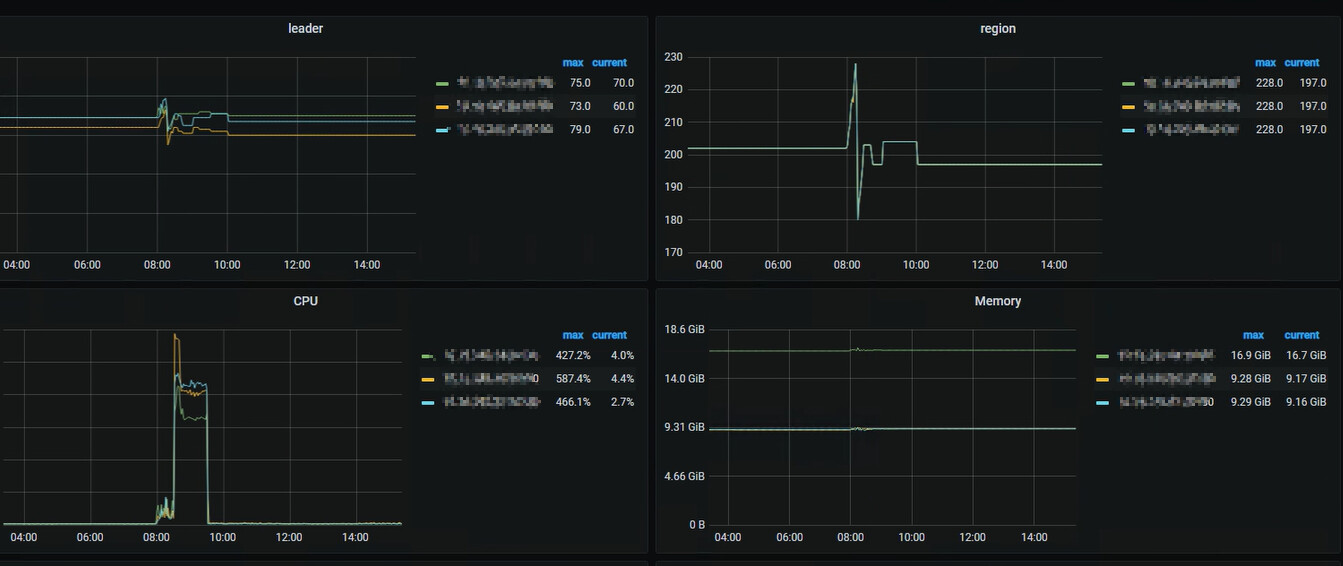
没倾斜,TiKV 的 CPU 用的差不多,优化 SQL 把
哦哦,意思就是在那个时间段内,热点很大,但是tikv每个节点都比较均匀,cpu都打满了,所以更大原因是sql的问题,不是因为某个节点被单独访问的原因造成的,对吗?
https://docs.pingcap.com/zh/tidb/stable/dashboard-key-visualizer#y-轴明暗交替需要关注产生的热点聚集程度
另外,明亮区域的高度(Y 轴方向的粗细)非常关键。由于 TiKV 自身拥有以 Region 为单位的热点平衡机制,因此涉及热点的 Region 越多其实越能有利于在所有 TiKV 实例上均衡流量。明亮条纹越粗、数量越多则意味着热点越分散、更多的 TiKV 能得到利用;明亮条纹越细、数量越少意味着热点越集中、热点 TiKV 越显著、越需要人工介入并关注。
需要考虑介入的读热点应该是明亮的横线。
你这个图,其实说明可能读取的时间比较集中,但绝对是比较理想的情况,最多是下面那些表,可能需要关注一下。
不过一般以我的经验,下面这些表可能是和统计信息相关的系统表。是没有办法改造的。 ![]()
应该是sql问题
明白,所以最好的办法是增加tiflash节点,进行olap统计